1 前言
在进行芯片设计时,通常需要一些衡量设计好坏的指标。目前业内常用的指标包括:
- 运行速度,包括整个系统的吞吐率和时钟频率;
- 资源占用,包括整个系统消耗的资源大小、板面体积和关联物料成本;
- 功耗,通常需要考虑完成某个给定任务所消耗的总能量,而不是单芯片能耗;
- 计算精度,包括如何定点化,以及如何在有限字长情况下保证最终输出性能。
对于通信系统而言,定点性能指标非常关键,因为如果定点化后,运算结果与浮点原始计算结果的差异很大或者总有溢出,那么即使在面积、速度以及功耗方面有很好的性能,该系统也是无法使用的。
HDL电路的优化也是从这几个方面入手。
2 提高电路运行速度
提高电路运行速度主要包含3个方面:吞吐率、输入输出延时、时序。吞吐率能够表征一个时钟周期内处理的数据总量,是电路性能的基本衡量单位;延时表征输入与输出之间的时间差,通常采用延迟多少个时钟周期表示;时序则表示时序单元间组合逻辑的延迟大小,通过其中的关键路径可限制整个电路能够运行的最大工作频率,因此时序的衡量标准为时钟频率。
提高电路运行速度的主要思想是:
- 空间换时间;
- 将原有设计进行优化或重排序;
- 组合逻辑的优化。
主要手段包括:
- 并行化与流水线;
- 循环逻辑展开;
- 重定时。
2.1 吞吐率
芯片设计中的吞吐率与生产线的产量有相通之处,因此在设计中可以借鉴现代工业化生产的方式,采用流水线或者类似的方法提高吞吐率。下面通过一个简单的倍数累加函数来描述吞吐率的概念,其中的“+”可以被认为是重载运算符,也可以替换为诸如乘法、除法或者MAC等其他的功能单元。
X = 0.5;
for(i=0;i<times;i++)
times_x = X + times_x;
 按照上述C代码实现的硬件结构如图所示。将上述程序直接改为Verilog代码,可以写成如下形式:
按照上述C代码实现的硬件结构如图所示。将上述程序直接改为Verilog代码,可以写成如下形式:
module TimesN(
output reg [7:0] Times_x,
output finished,
input [7:0] X,
input clk,start
);
reg [7:0] times;
reg [7:0] Times_x;
assign finished = (times == 0);
always@(posedge clk)
if(start)begin
Times_x <= X;
times <= 'TIMES; //'TIMES=3 宏定义
end
else if(!finished)begin
times <= times - 1;
Times_x <= Times_x + X;
end
endmodule
可以看出,模型的吞吐率是每3个周期完成1次计算(8位);整体延迟为3个时钟周期,而关键路径为加法器。
对于上述实现方法,可以通过流水线方式进行改进,从而使吞吐率达到单周期完成1次计算,具体代码如下:
module TimesN_pipe(
output reg [7:0] Times_x,
input clk,
input [7:0] X
);
reg [7:0] Times_x1,Times_x2;
reg [7:0] X1,X2;
always@(posedge clk)begin
//Pipeline stage 1
X1 <= X;
Times_x1 <= X;
//Pipeline stage 2
X2 <= X1;
Times_x2 <= Times_x1 + X1;
//Pipeline stage 3
Times_x <= Times_x2 + X2;
end
endmodule
电路实现结构如图所示:
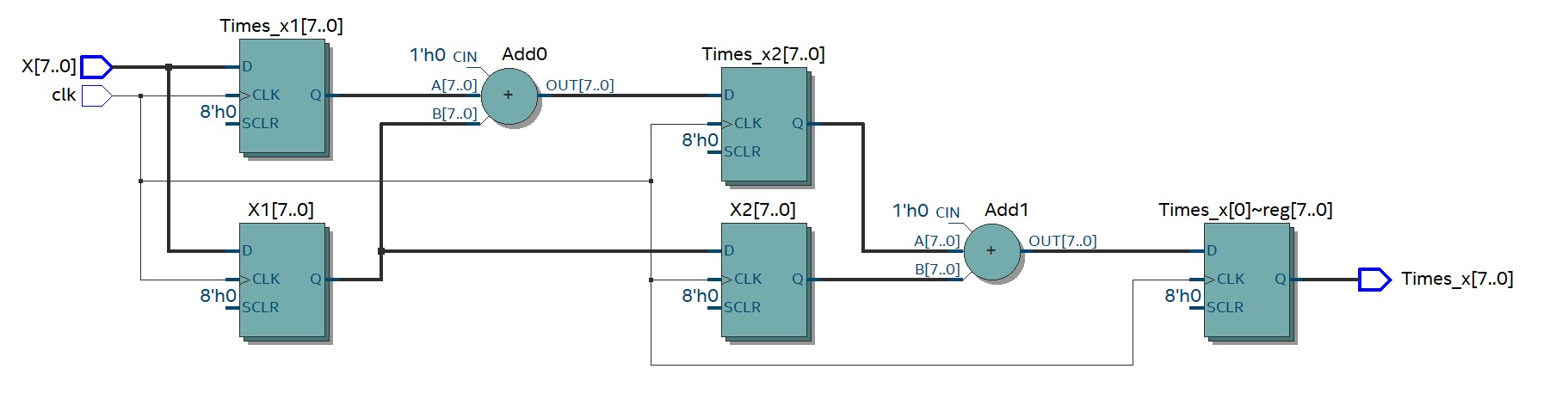
通过上述实现方法能够达到的效率是:单个周期完成一次计算(8位);整体延时为3个时钟周期,而关键路径为加法器。上述实现是以增加资源消耗为代价的,相对于迭代实现方式,需要增加加法器和多个寄存器,同事整体延时没有得到改进。
2.2 整体延时
降低一个逻辑电路整体延迟的主要手段包括:
- 除去所插入的流水线寄存器;
- 将串行处理修改为并行处理;
- 单个周期内,在合理的限度下尽量完成较多的组合逻辑。
因此针对前面的N倍累加器,如果需要降低输入输出整体延迟,一个直观的想法是去掉流水线所用的寄存器,直接完成多个加法,即将加法器串联在一起,用这种模式的确能够降低电路的整体延时,代码如下:
module TimesN_comb1(
output [7:0] Times_x,
input [7:0] X
);
wire [7:0] Times_x1,Times_x2;
assign Times_x1 = X;
assign Times_x2 = Times_x1 + X;
assign Times_x = Times_x2 + X;
endmodule
电路结构如图所示:

前面给出的例子是基于单输入的倍数计算,在实际中很难遇到如此简单的设计,此处给出该例子的主要目的是为了说明流水线、吞吐率、延迟这三者的关系。如果将例子中的加法器换成乘法器,将单输入换为多输入,就比较有实际意义了。在实际的通信电路中,较大字长的乘法器通常都是阻碍电路工作于较高频率的主要因素,所以如何优化乘法器的位置、如何优化摆放是芯片优化中的一个基本工作。
考虑一个四次方的乘法电路实现,相关的C语言实现过程与前面的描述类似:
X=0.5 //time = 4,采用宏定义方法;X为输入,times_x为输出
for(i=0;i<times;i++)
times_x = X*times_x;
但在具体电路细节上有一定的差异,具体如下:
module PowerN_comb2(
output [7:0] Times_x,
input [7:0] X
);
wire [7:0] Times_x1,Times_x2;
assign Times_x1 = X;
assign Times_x2 = Times_x1*X;
assign Times_x = Times_x2*Times_x2;
endmodule
比较模块PowerN_comb2与Times_comb1(需要将加法器替换为乘法器),就会发现两者的延迟、吞吐率以及关键路径实际上是一致的。而实际上,它们其中一个完成了4次方运算,另一个只是完成了3次方运算。出现这种情况的原因就是TimesN_comb1是一个关键路径,且是一个不平衡树,而PowerN_comb2为平衡树,如图:
如电路时序不满足要求,则在图中对应位置插入流水线寄存器以实现流水线操作,此时时序可以满足要求。
2.3 小结
吞吐率作为衡量电路性能的关键因素,提高它的主要技巧如下:
- 当需要增加电路的吞吐率时,可以将其中的迭代循环部分展开。相关的方法包括展开(例如将原有单周期执行1次任务修改为一次执行2次)或者完全展开(全部并行,即单周期将所有任务执行完毕),这种实现方式的代价就是关键部件的数量翻倍(依赖于展开的程度)。
- 可以通过插入流水线寄存器改善关键路径的时序,或者通过去除部分关键流水线寄存器改善路径的整体延时,代价为组合逻辑的时序恶化,这两者互相矛盾。
- 在优化时序时,注重整体运算单元的平衡。通常平衡二叉树的时序和延迟都是最优的,而非平衡二叉树可以通过移动寄存器位置优化组合逻辑。时序优化的主要技巧包括:重定时、寄存器位置重排列,以及循环的中断等。
3 降低电路规模
在正式的产品中,往往希望产品越便宜越好,性能越高越好。“便宜”对于ASIC而言就是最终实现面积越小越好,而对于FPGA而言,则是消耗的资源越少越好;而“性能”则对应于之前所说的吞吐率。对于ASIC而言,由于每一个电路门都是可控的,所以设计与综合时只需按照逻辑门数越低越好的目标设置即可。而对于FPGA而言,则略微有点不同,由于FPGA在生产出来后,资源数量已经确定,而各款FPGA之间的资源数目不是连续分布的,通常以同级别FPGA最大规模的10%的资源作为台阶进行分布,无法像ASIC一样尽量使用最小的资源。因此对于FPGA而言,其追求的面积目标就是在保证性能的前提下,设计资源能够占到该款FPGA资源的80%左右(资源包括LE/RAM/IO等,而且是满足项越多越好)。当选定FPGA后,则应当发挥该FPGA的最佳性能。
减少电路面积的主要策略是选择合适的实现构架,其次是尽量复用部分逻辑单元。这里的理论技巧主要是图论、DFG和割集等,大家可以参阅相关参考文件。相对于ASIC芯片设计,FPGA在设计时还需要额外考虑时钟与全局信号,因为FPGA已经为此类信号专门预留了时钟数和全局信号。而要在FPGA中利用这些时钟与复位专用通路,就必须遵循FPGA厂商的指导规范,从而达到优化面积的目的。
在实际电路设计中,减少电路面积的核心思想是通过时间换取空间,即在多个时钟周期内反复使用同一部件。此外,如果系统设计不良,还需采取再平衡、重排序、重定时等技术手段实现面积最优化。
3.1 折叠
折叠实际上就是反复使用某个部件的过程。在电路设计中,有时可用的逻辑资源非常有限,通常需要牺牲系统的吞吐率来使占用面积减少。针对多时钟域的情况,即低速域与高速域存在于同一设计中(例如同时存在数字中频或多速率抽取电路)。在多时钟情况下,通常运行在低速率下的单元要求大规模并行以保证基本的吞吐率,此时就可以将低速率并行单元移到高速率时钟域下,并采用串行折叠方法以实现面积节省。一个典型的例子如图:
结合折叠,可以按照如下电路结构实现相同的电路功能:
从这个折叠的例子可以看出,通过某个需要反复使用的部件进行倍频或者高频倍频后时分复用可实现折叠。另外,折叠的部件不应当局限于某个具体得到硬件(例如乘法器),而应当自动识别某一模式,然后进行模式匹配。最后,再针对模式匹配的结果进行折叠,从而带来更大的面积节约。模式折叠的一个典型例子如图所示:
在这个例子中,对双模乘加单元进行提取,并按照两倍时钟的方法复用该单元,使实际器件使用面积降低约一半。这种折叠方法是基于真事多倍时钟的方法,在实现设计中还有基于隐含多倍时钟的折叠方法,即将原始吞吐率降低为原来吞吐率的1/N,然后复用折叠运算单元,从而实现N倍的折叠。这种折叠方式在单片机领域尤其常见,例如乘法器、除法器等。
下图以4×3乘法器设计为例说明隐含多时钟域的折叠实现方法:
这是标准的全并行4×4乘法器。对于该乘法器而言,如果要求高速度,则采用阵列式乘法器结构,使用12个1位加法器(全加器/半加器);如果对速度要求不高,而要求面积占用要小,则应当使用串行时序乘法器。需要注意的是,阵列乘法器为纯组合逻辑电路,而串行时序乘法器是由时钟控制的时序电路。
将该阵列乘法器进行折叠变换较为简单。通过观察阵列式乘法器结构可知,一个阵列式乘法器相当于“三个”加法器的级联。因此实现串行时序乘法器时,只采用“一个”加法器来实现乘法运算。此外,还需要增加控制逻辑,并插入部分寄存器来存放中间结果。乘法器的折叠代码实现如下:
module multi_seq_full#(parameter MUL_WIDTH=4)(
input clk,
input [MUL_WIDTH-1:0] x,
input [MUL_WIDTH-1:0] y,
output reg [2*MUL_WIDTH-1:0] result
);
localparam MUL_STEP = `log_floor(MUL_WIDTH); //log宏定义
localparam MUL_INIT = 0,MUL_SEQ = 1,MULT_RESULT = 2;
reg [MUL_STEP-1:0] count = 0;
reg [1:0] = 0;
reg [2*MUL_WIDTH-1:0] P,T;
reg [MUL_WIDTH-1:0] y_reg;
always@(posedge clk)begin
case(state)
MUL_INIT:begin
count <= 0;
P <= 0;
y_reg <= y;
T <= ,x};
state <= MULT_SEQ'
end
MULT_SEQ:begin
if(count==MUL_WIDTH-1)
state <= MULT_RESULT;
else begin
if(y_reg[0]==1'b1)
P <= P + T;
else
P <= P;
y_reg <= y_reg >> 1;
T <= T << 1;
count <= count + 1;
state <= MULT_SEQ;
end
end
MULT_RESULT:begin
result <= P;
state <= MULT_INIT;
end
default:
state <= MULT_INIT;
endcase
end
endmodule
上述实现代码可以通过改变参数MUL_WIDTH获得不同位长的串行乘法器,具体实现代码包括:
- 串行的时序控制逻辑,即程序代码中state变量,其中MULT_SEQ过程是串行过程,通过计数器count控制;
- 累加与进位过程,即2个1位移位器与一个加法器;
- 结果输出单元,即state在MULT_RESULT状态时,输出乘法结果。当需要乘法器输出状态指示时,可以通过输出state信号或相关运算获得。
3.2 基于多通道的复用
如果电路中有大量相同的运算,而控制流程大致相同,就可以采用多通道的方法实现电路的简化。一个典型的多通道复用电路就是通信基站上所用到的多信道数字中频技术(一条数据通路支持同时完成3个小区或者6个小区的数字中频变换),在概念上非常类似于C语言中的函数调用。
在正常情况下,如果有N路并行完成相同的任务,直观做法就是例化N个相同模块。例如下面给出的是例化DesignWare乘法器IP的9位复数乘法器代码。
DW02_mult#(9,9)U_Comn(.A(b_b),.B(cossin),.TC(1'b1),.PRODUCT(common));
DW02_mult#(9,9)U_i (.A(cos),.B(ab),.TC(1'b1),.PRODUCT(mul_i));
DW02_mult#(9,9)U_q (.A(sin),.B(a_b),.TC(1'b1),.PRODUCT(mul_q));
如果想要节省乘法器或者类似的可执行单元,可以采用讲时钟倍频的方法,然后时分复用。这种思想可衍生出多通道的概念。
多通道实现有几个关键性问题:
- 输入通道的多选一控制;
- 输出通道的1对N解复用;
- 由于在单通道时有存储单元,一次多通道也需要进行缓存,这个缓存控制也是关键。
通常的多通道解决方案是通过一个N次计数器完成基本控制,而对于中间状态缓存,也需要N倍寄存器或者通过FIFO/RAM等器件保存中间结果。这种方案属于程序化的解决方案,存在较多的冗余可能性,例如中间状态缓存器是否可以通过整合优化,寄存器的生命周期是否可以共享等。这些进一步的优化手段可以从相关的图论理论与VLSI专业书籍中获得。
3.3 基于控制逻辑的复用
基于逻辑控制的复用不存在时钟倍频或其他时钟变换手段,只是通过提取公共可能的控制电路,以实现电路复用。CPU中的典型例子就是SIMD,即单指令多数据。SIMD能够在一条指令中并行执行多个相同的运算单元,这种实现的根基也就是控制逻辑复用。下面简单介绍ARM 1176ejs中的一条SIMD增强指令的实现过程,该指令实现4个8位并行加法器,计算部分采用4个相同的组合逻辑实现,而控制部分公用一套逻辑,因此下面的代码中没有出现控制部分,控制部分在CPU的逻辑中实现。
module SIMDAdder(
AUOut,COut,GE,Sat,Ext,
ADataEx,BDataEx,CIn,SignedSIMD,AuInvT,AuInvB,SigndeSat
);
input SignedSIMD;
input AuInvT;
input AuInvB;
input SignedSat;
input [31:0] ADataEx;
input [31:0] BDataEx;
input [6:0] CIn;
output [31:0] AUOut;
output COut;
output [3:0] GE;
output [3:0] Sat;
output [3:0] Ext;
wire [34:0] iAUOut;
wire [3:0] iExt;
wire [3:0] CryOut;
wire [3:0] EarlySat;
wire [3:0] EarlyGE;
wire [34:0] InAEx;
wire [34:0] InAEx;
assign InAEx[34:0] = {ADataEx[31:24],CIn[5],ADataEx[23:16],CIn[3],ADataEx[15:8],CIn[1],ADataEx[7:0]};
assign InBEx[34:0] = {BDataEx[31:24],CIn[6],BDataEx[23:16],CIn[4],BDataEx[15:8],CIn[2],BDataEx[7:0]};
A1176CoreAdd35 uAdd35(
.A (InAEx[34:0]),
.B (InBEx[34:0]),
.CI (CIn[0]),
.CO (CryOut[3]),
.SumOut (iAUOut[34:0])
);
assign CryOut[0] = iAUOut[8]^(InAEx[8]^InBEx[8]);
assign CryOut[1] = iAUOut[17]^(InAEx[17]^InBEx[17]);
assign CryOut[2] = iAUOut[26]^(InAEx[26]^InBEx[26]);
assign COut = CryOut[3];
assign EarlyGE[0] = (SignedSIMD &~ (ADataEx[7]^BDataEx[7]));
assign EarlyGE[1] = (SignedSIMD &~ (ADataEx[15]^BDataEx[15]));
assign EarlyGE[2] = (SignedSIMD &~ (ADataEx[23]^BDataEx[23]));
assign EarlyGE[3] = (SignedSIMD &~ (ADataEx[31]^BDataEx[31]));
assign GE[0] = EarlyGE[0]^CryOut[0];
assign GE[1] = EarlyGE[1]^CryOut[1];
assign GE[2] = EarlyGE[2]^CryOut[2];
assign GE[3] = EarlyGE[3]^CryOut[3];
assign EarlySat[0] = (~SignedSat&AuInvB) | (SignedSat&(ADataEx[7]^BDataEx[7]));
assign EarlySat[1] = (~SignedSat&AuInvB) | (SignedSat&(ADataEx[15]^BDataEx[15]));
assign EarlySat[2] = (~SignedSat&AuInvT) | (SignedSat&(ADataEx[23]^BDataEx[23]));
assign EarlySat[3] = (~SignedSat&AuInvT) | (SignedSat&(ADataEx[31]^BDataEx[31]));
assign iExt[0] = EarlySat[0] ^ CryOut[0];
assign iExt[1] = EarlySat[1] ^ CryOut[1];
assign iExt[2] = EarlySat[2] ^ CryOut[2];
assign iExt[3] = EarlySat[3] ^ CryOut[3];
assign Sat[0] = (iAUOut[7]&SignedSat)^iExt[0];
assign Sat[1] = (iAUOut[16]&SignedSat)^iExt[1];
assign Sat[2] = (iAUOut[25]&SignedSat)^iExt[2];
assign Sat[3] = (iAUOut[34]&SignedSat)^iExt[3];
assign AUOut = {iAUOut[34:27],iAUOut[25:18],iAUOut[16:9],iAUOut[7:0]};
assign Ext = iExt;
endmodule
告辞。
