{kind=link}
硬件算法之脉动算法
19 Jul 2019 2210字 8分 次 Hardware Algorithm打赏作者 CC BY 4.0 (除特别声明或转载文章外)
1 脉动算法和脉动阵列
脉动算法(systolic algorithm)是指基于H.T.Kung所提倡的脉动阵列(systolic array)所实现并行处理算法的总称。脉动阵列是一种由众多简单的运算元件(Processing Element,PE)按规则排列的硬件架构,具有以下特征:
- 由单一或多种构造PE按规则排列;
- 只有相邻的PE互相连接,数据每次只能在局部范围内移动。除了局部连接,同时还采用总线等连接方式的架构被称为半脉动阵列;
- PE只重复进行简单的数据处理和必要的数据收发;
- 所有PE由统一的时钟同步工作。
每个PE都和相邻PE同步进行数据收发和运算。数据从外部流入,PE阵列一边搬运数据,一边采用流水线或并行方式对其进行处理。各个PE的运算和数据收发动作和心脏规律性的收缩促使血液流动的过程非常相似,因此此类架构被命名为脉动阵列。此外,PE有时也被称为单元(cell)。
脉动阵列中数据的移动只能在相邻PE间进行,这种单纯的架构具有良好的扩展性,系统性能可随着阵列的规模的扩大成比例增加。并且脉动阵列非常适合在集成电路上实现。下图展示的是一些经典的脉动阵列和脉动算法。脉动阵列按PE的排列和连接方式,大致上可以分为线性串联的一维阵列、网格状连接的二维阵列,以及树状连接的树结构阵列。基于这些阵列结构,大量的研究分别提出了用于信号处理、并行计算、排序、图像处理、模板计算、流体计算等各种应用的脉动算法。
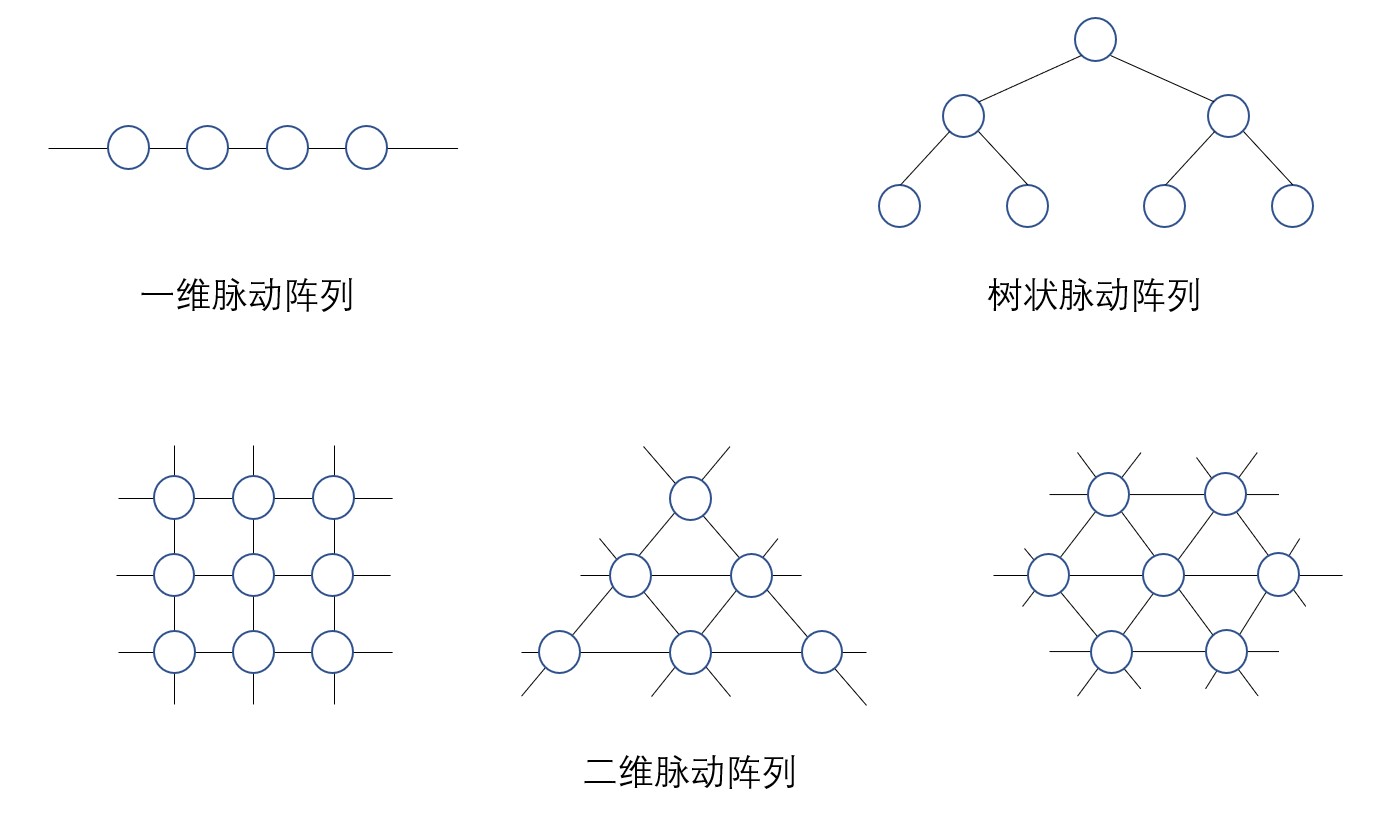
早期的脉动阵列无论结构还是功能都是固定的,随后才出现了具有可编程或可重构功能的通用脉动阵列(general-purpose systolic array)。可编程是指在固定电路上运行不同的程序来改变功能,可重构是指通过更新电路来改变功能。 此外,当脉动阵列的规模扩大到一定程度后,由于时钟的延迟,实现大范围内的电路以较高频率同步是非常困难的。S.Y.Kung为了解决这个问题,提出了将数据流引入脉动阵列架构的波前阵列(wavefront array)。该架构中的PE由异步电路方式设计,可以按照各自的速度运行,和相邻PE基于握手的方式进行数据收发。
2 基于一维脉动阵列的部分排序
将数据按照某种顺序重新排列的过程被称为排序。排序是很多问题求解过程中都要用到的一种重要的数据处理过程。下面我们以一种将n个数据组成的数组按数值从大到小排列,再输出其中数值最大的N个数据的应用为例,讲解如何使用脉动算法进行处理。
下图所示的是用来对数值最大的N个数据进行排序的以为脉动阵列及其PE。
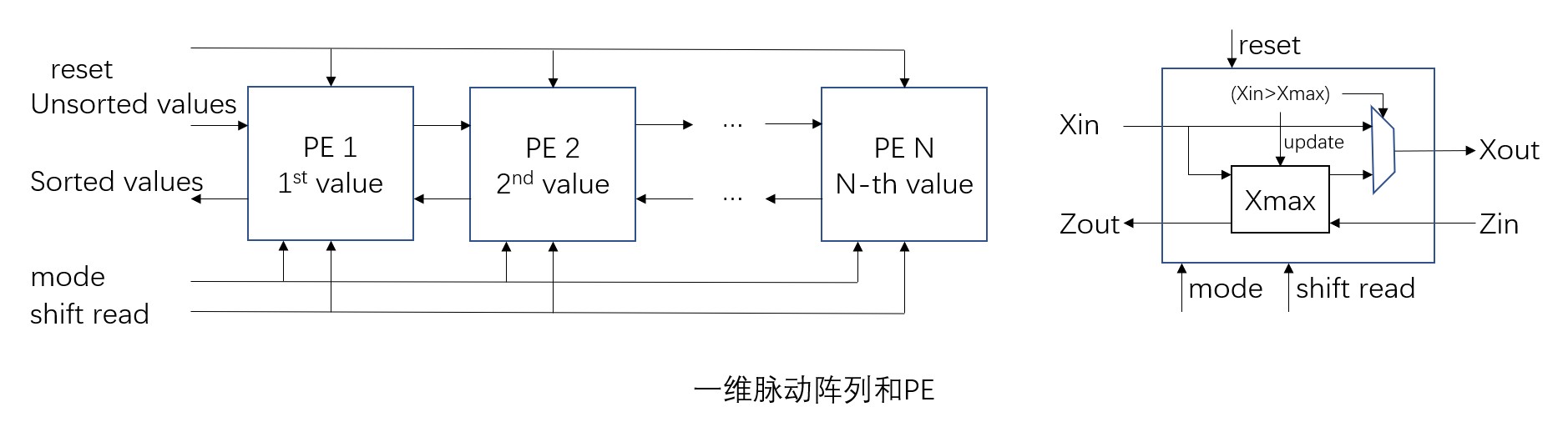
一维排列上的N个PE都具有寄存器,用来保存临时最大值Xmax,当输入Xin比Xmax大时将Xmax更新为Xin。临时最大值更新时将原本的Xmax输出到右侧的PE,没有更新时则将Xin输出到右侧的PE。不断重复这个过程直到最后第N个数据进入PE,数值最大的N个数据就会从左到右按顺序存放在各个PE寄存器中。
整个电路的运行过程如下图所示:
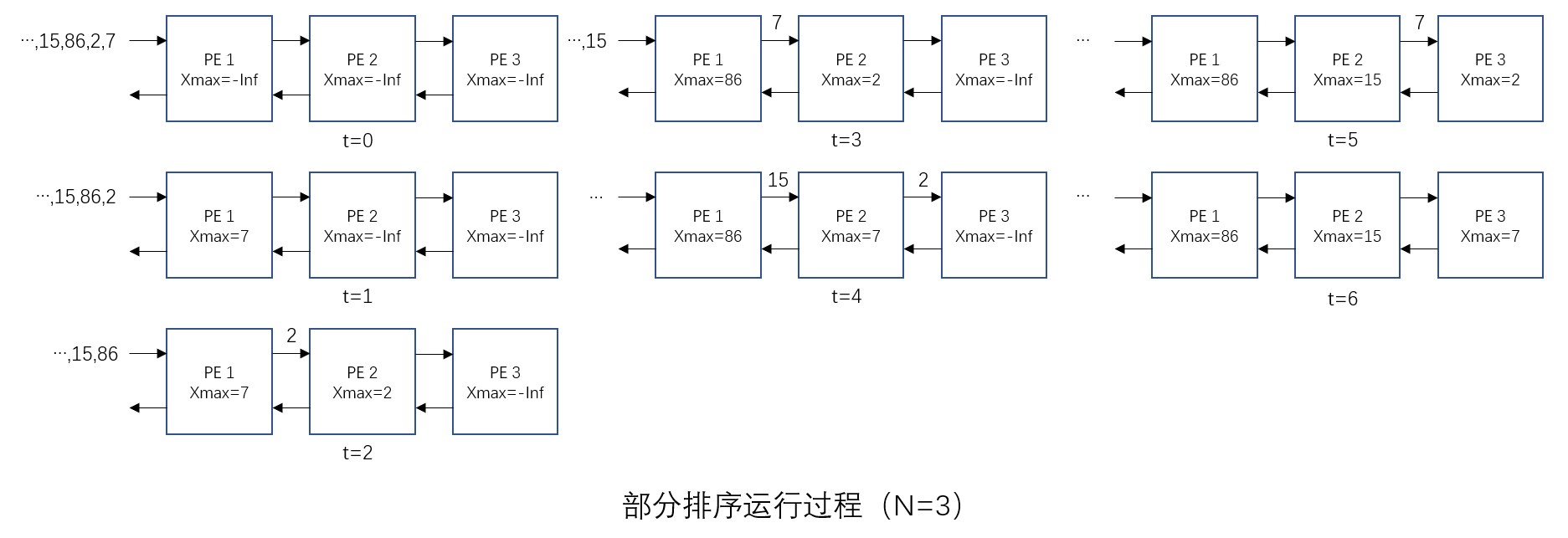
采用由N个PE组成的脉动阵列对n个数据进行部分排序,总共需要(N+n-1)个步骤。
一维脉动阵列示意图的左半部分所示的脉动阵列包含控制用输入信号reset、mode、shift read。当reset有效时,所有PE内的临时最大值寄存器被初始化。mode信号用来选择电路为排序模式(输入为1时)或读取结果模式(输入为0时)。shift read是用来将排序结果从大到小逐一读出的信号。如上图中t=6时的电路状态所示,最大值存放在最左侧具有输入/输出端口的PE中。此时,脉动阵列可被当作移位寄存器,shift read作为移位控制信号,使用Zout和Zin的连接依次读取数据。
3 基于一维脉动阵列的矩阵向量相乘
矩阵向量相乘运算Y=AX也可以采用一维脉动阵列实现。运算元素数为N×N的矩阵所需PE的个数为N。下图为N=4时矩阵向量向量的一维脉动阵列示例。
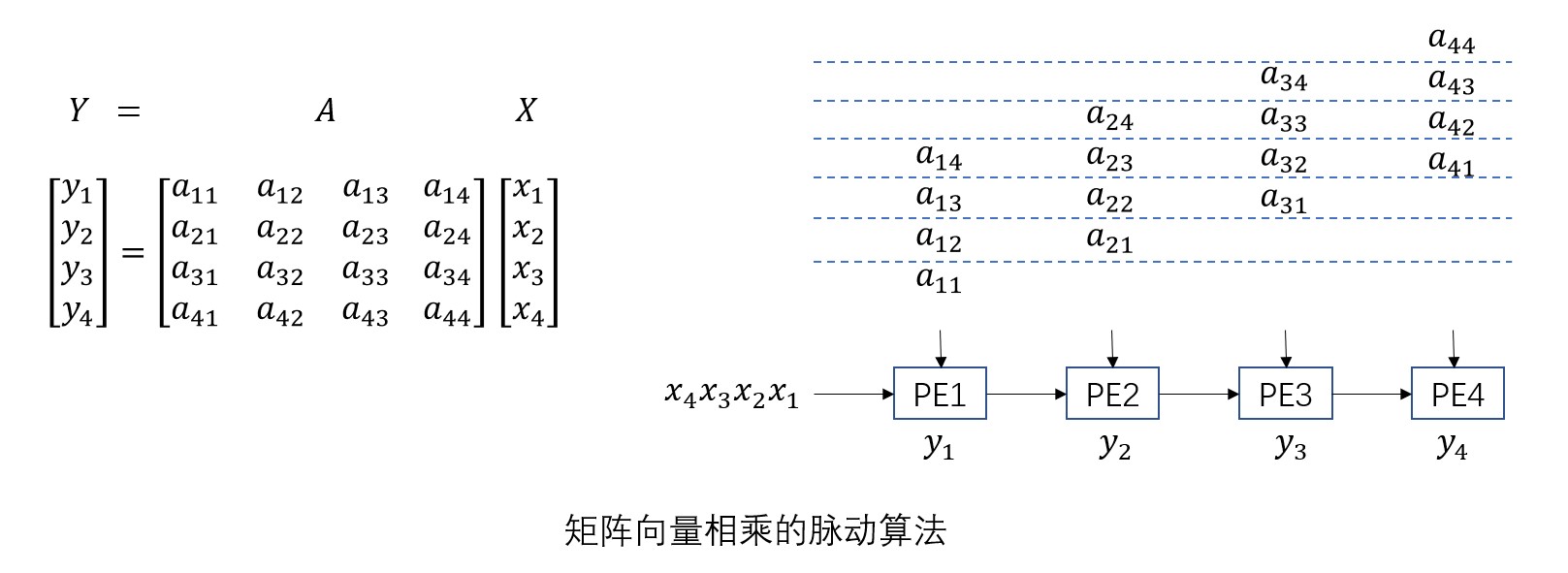
向量X的各个要素从左到右,矩阵A各行从上到下依次输入到一维线性排列的PE进行运算。各个PE将向量X的元素x和矩阵A各行要素a相加,将结果向量Y各元素的中间结果暂存到寄存器yi中。所有PE每一步计算一次yi=yi+ax,并将x值输出到右侧的PE。
首先在运算开始前将所有的PE中的寄存器yi初始化为0。第一步在PE1中计算y1=0+a11x1。随后,PE1中的y1=y1+a12x2和PE2中的y2=0+a21x1运算并行进行。向PE1~PE4输入的各行元素依次延迟一步,这样各个PE运算所需的数据都会在恰当的时间点输入。不断重复这个过程直到最后一个矩阵元素输入到PE4,各PE中寄存器所组成的y1~y4的值即为所求向量Y的值。由于矩阵各行的输入时间依次错开,完成运算所需总步数为2N-1。
4 基于二维脉动阵列的矩阵相乘
将上一节的一维脉动阵列扩展到二维,形成网格状排列的二维脉动阵列,就可以进行矩阵相乘运算C=AB。矩阵大小为N×N的话,需要由N×N个PE构成的N×N纵横排列的脉动阵列。下圖為N=4时的示意图:
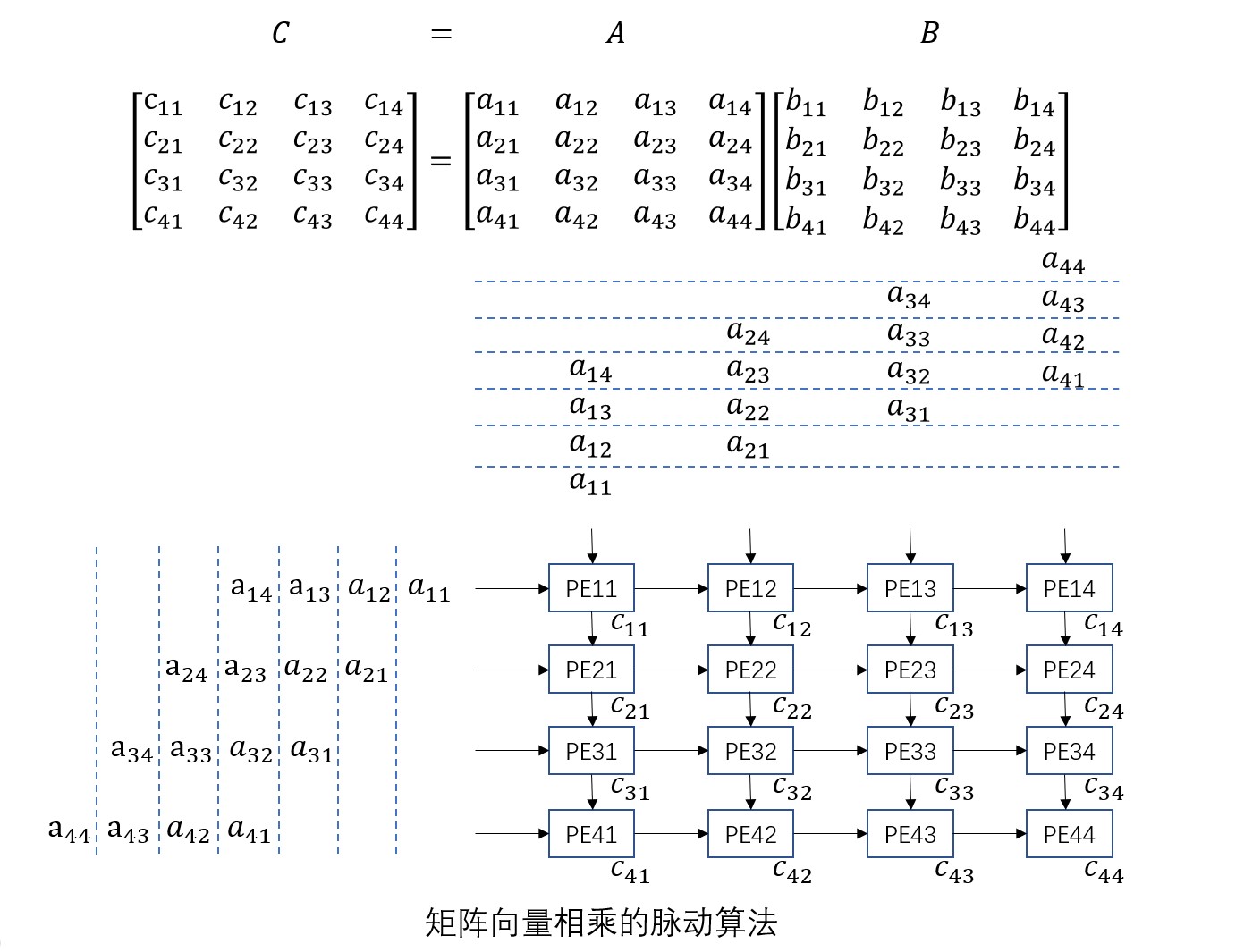
和基于一维脉动阵列的矩阵向量相乘相同,从阵列的左侧和上方将矩阵A和B各行依次错位输入。PE的功能和之前也一样,运算开始前将内部寄存器初始化为0.当矩阵最后一个元素a44b44输入到PE44,所有PE中的寄存器值组成所求矩阵C。运算所需总步数为3N-2。
告辞。