{kind=link}
硬件算法之流处理
27 Jul 2019 2468字 9分 次 Hardware Algorithm打赏作者 CC BY 4.0 (除特别声明或转载文章外)
1 定义和模型
针对逐个输入的数据序列,持续地依次处理其中各个元素的方式被称为流处理(stream processing)。数据元素可以是单一标量数据,也可以是包含多个字节的向量数据。流处理每次只能处理一个元素,虽然元素增多(数据流增长)时处理时间会成比例增加,但这也意味着只要付出时间就可以处理巨大的数据集。流处理器自身并不包含保存全部流数据的存储器,数据流通常从外部存储器、网络或是传感器输入。因此,例如要对来自网络上无数的、不间断的服务器请求信息进行统计,又无法将如此大量的数据存储下来,就可以使用流处理的方式。另外,从外部存储器上读取数据流时,流处理通常从规则、连续的地址空间读取数据,因此具有可充分利用内存带宽的优势。
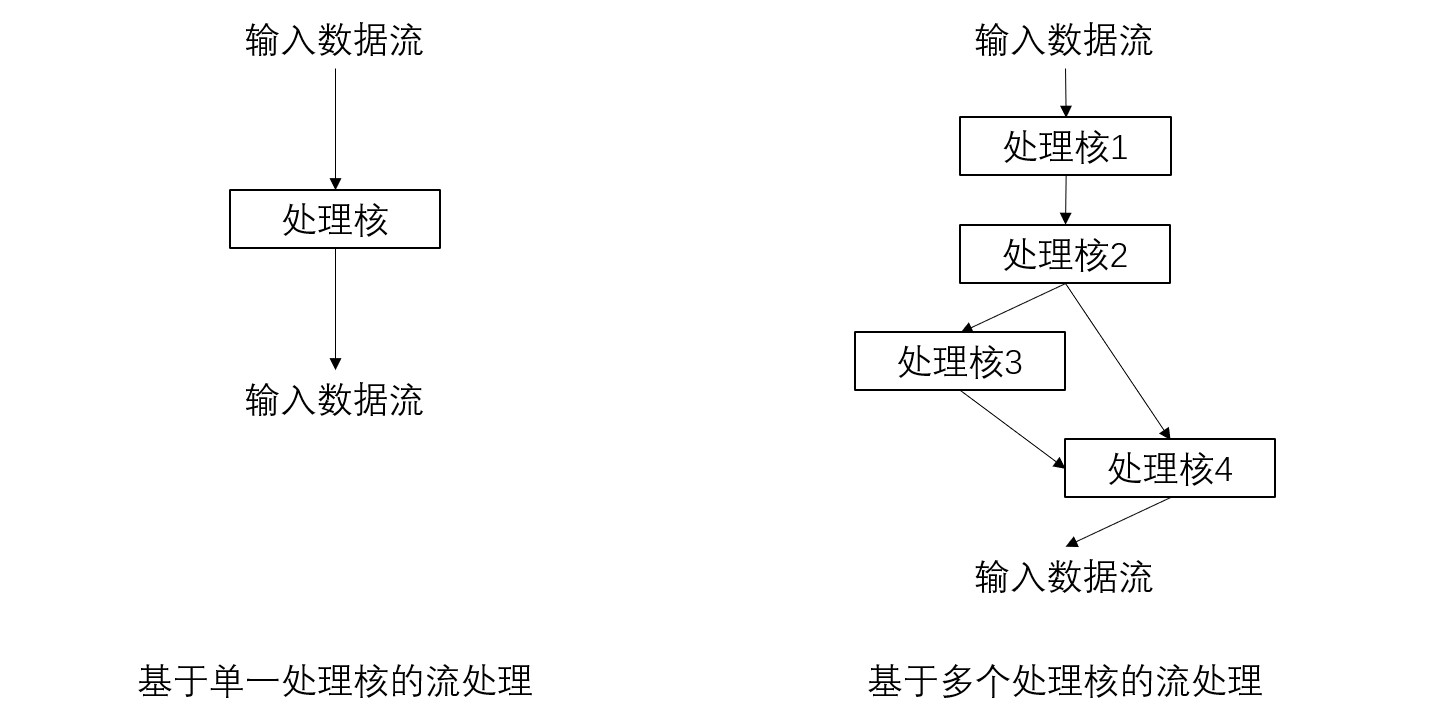
处理流数据元素的处理单元称为处理核(kernel)。下图左边是基于单一处理核进行流处理的模型。
虽然输入的是数据流,根据处理的种类不同,输出可以是数据流也可以是其他形式,比如可以连接多个相互依存的处理核,联合进行数据流处理。这就相当于使用数据流图进行数据处理,处理核相对于数据流图中的节点,如下图右边所示:
2 硬件实现方法
流处理有各种各样的实现方法。首先可以使用软件实现高吞吐量的流处理系统,例如在通用微处理器中嵌入向量指令或SIMD指令。这类指令可以高速处理固定长度的向量数据。然而,通用处理器由于并行能力有限、内存层级较深等原因,其处理数据流输入/输出的效率不高。因此通常会采用硬件的方式实现高性能的流处理系统。
高性能流处理硬件的架构通常包含可同时进行大量运算操作的并行机制,例如流水线、脉动算法、数据流机等。以上图基于多个处理核的流处理所示的系统为例,如果有足够多的硬件资源来实现图中由多个处理核组成的流处理结构,每个处理核都作为一级流水线相互连接,最终就能形成一个大型流水线设计。这样的系统可以达到吞吐量为1的流处理,即每个时钟周期都可以进行数据的输入/输出。
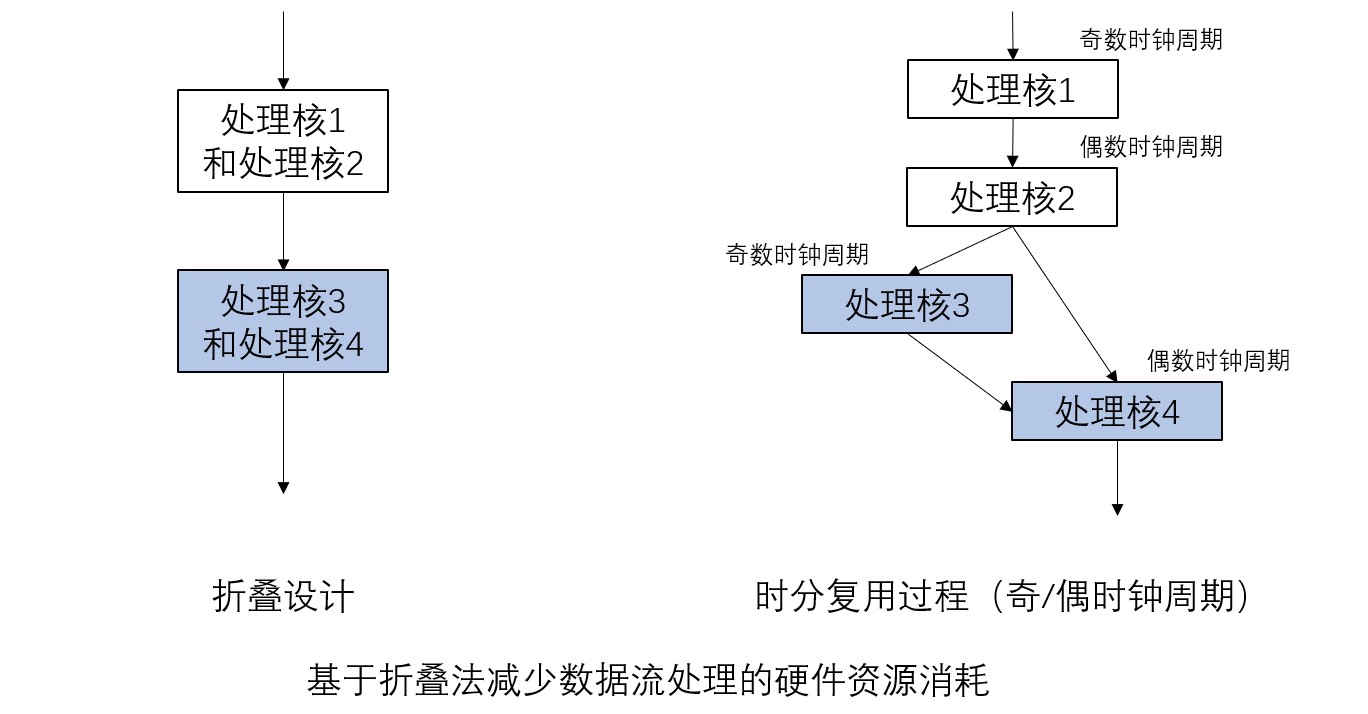
下面探讨硬件资源不充裕时的设计方法。这种情况下,硬件资源不足以实现所有处理核,需要各个核心共享硬件资源,因此会导致单位处理时间的延长。还以上图基于多个处理核的流处理为例,我们假设硬件资源只够实现半数处理核的情况。此时,可以像下图折叠设计所示的那样减少模块的数量,比如第一个模块可以实现处理核1和处理核2,第二个模块可以实现处理核3和处理核4,通过动态切换它们的工作模式来实现原本的四个处理核的功能。这种方式会将原数据流图折叠变小后映射到硬件,因此被称为折叠(folding)法,硬件的时分复用过程如下图时分复用过程所示。首先处理核1对输入数据进行处理,然后切换到处理核2进行处理。处理核3和处理核4也按照同样方式运行。这样的系统设计导致处理周期翻倍,吞吐量会降低到原来的二分之,但可以在硬件资源有限的情况下实现流处理。
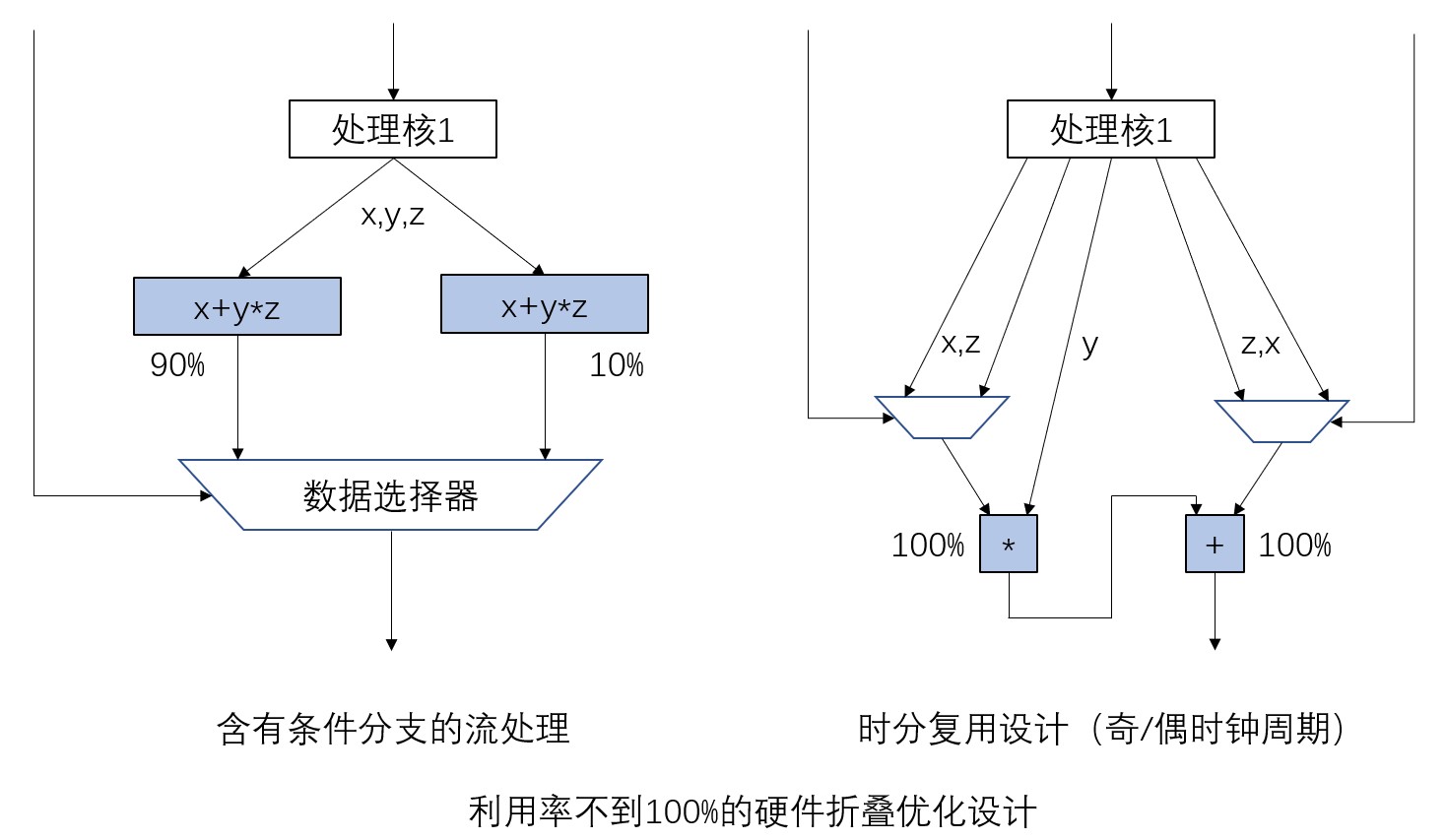
在之前的示例中处理核都是一直运行, 其硬件利用率为100%而上述的折叠法示例中,理论上重叠部分的处理核节点的利用率超过了100%,其结果就是吞吐量降低。然而在实际系统中,有很多原本利用率就不到100%与其他电路加起来也低于100%的处理核,例如分支处理等。复用这类模块虽然需要引入复杂的控制电路,但可以实现减少硬在之前的示例中处理核都是一直运行, 其硬件利用率为100%而上述的折叠法示例中,理论上重叠部分的处理核节点的利用率超过了100%,其结果就是吞吐量降低。然而在实际系统中,有很多原本利用率就不到100%与其他电路加起来也低于100%的处理核,例如分支处理等。复用这类模块虽然需要引入复杂的控制电路,但可以实现减少硬件资源消耗的同时保持利用率。下图就是一个利用率不到100%的系统通过折叠优化设计的示例。下图左边所示的流处理包含一个条件分支,两个算式(x+yz)和(xy+z)的运算同时进行,其结果通过选择器分别以90%和10%的比例被选择输出。从中我们不难发现两个算式具有共通的部分,可以通过复用运算器的方式设计出支持两种运算的模块。下图右边就是这样一种设计,其中包含一个加法器和一个乘法器,然后在运算器输入处插入数据选择器,以便在两种算式模式间切换。因为两种运算不需要同时工作,这种设计方法可以实现在不增加时钟周期的条件下降低硬件资源使用量。
另外,如果连续处理的多个数据之间存在依赖关系,在流处理过程中插入延迟缓冲存储器就可以解决。例如在下图中,假设处理核1当前输出为ei,如果处理核2的输入还要求提供过去的结果ei-1和ei-3,就可以采用图中所示的三级寄存器串联形成的延迟缓冲存储器。后面会以模板计算为例介绍使用延迟缓冲器的流处理系统。

3 计算实例
下图是一个数组求平均值的流处理示例:
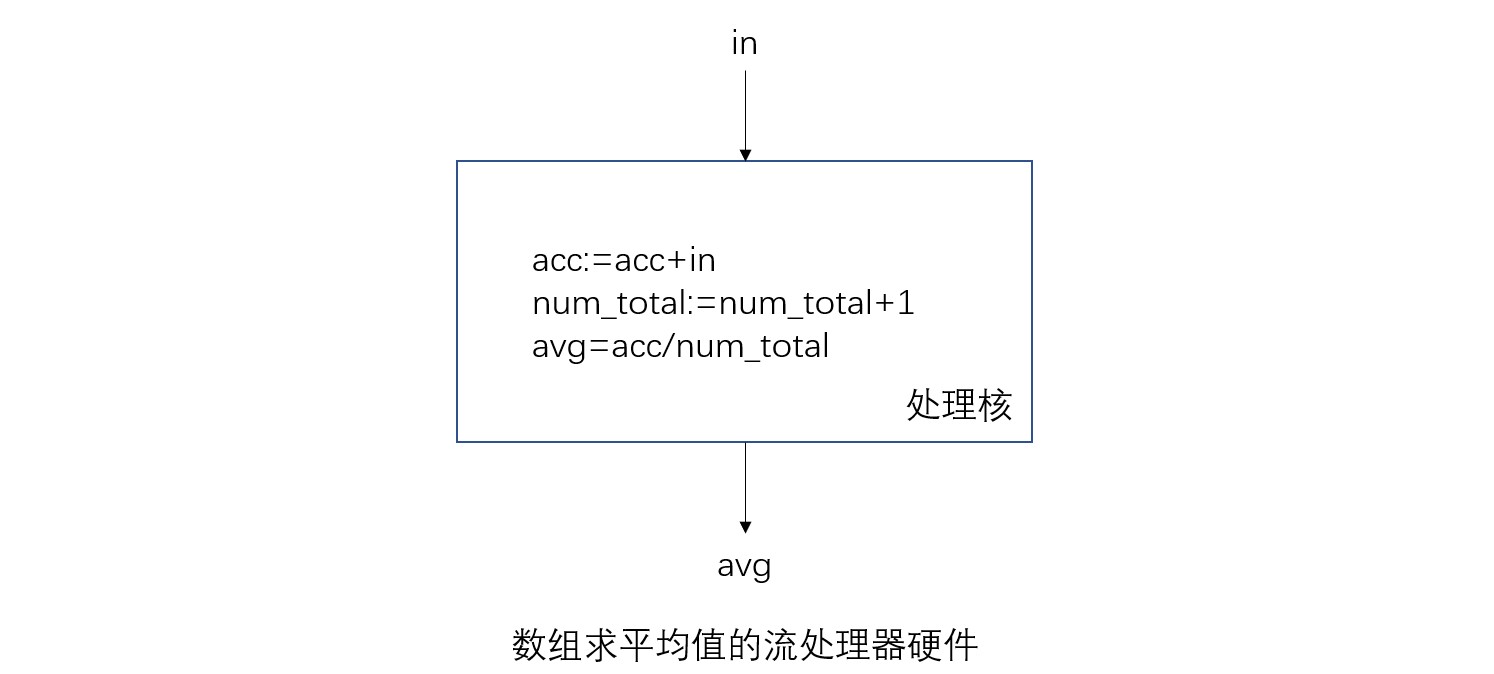
示例中的处理核有两个寄存器:acc和num_total。寄存器在开始时都初始化为0.当一个数组元素从in输入,acc对该元素的值进行累加,而num_total自行加1。每个时钟周期都将acc和num_total相除后的值赋给avg,表示该时间点的平均值。
下图是一个以二维循环模板计算为对象,实现二维循环模板计算的流处理硬件示例。
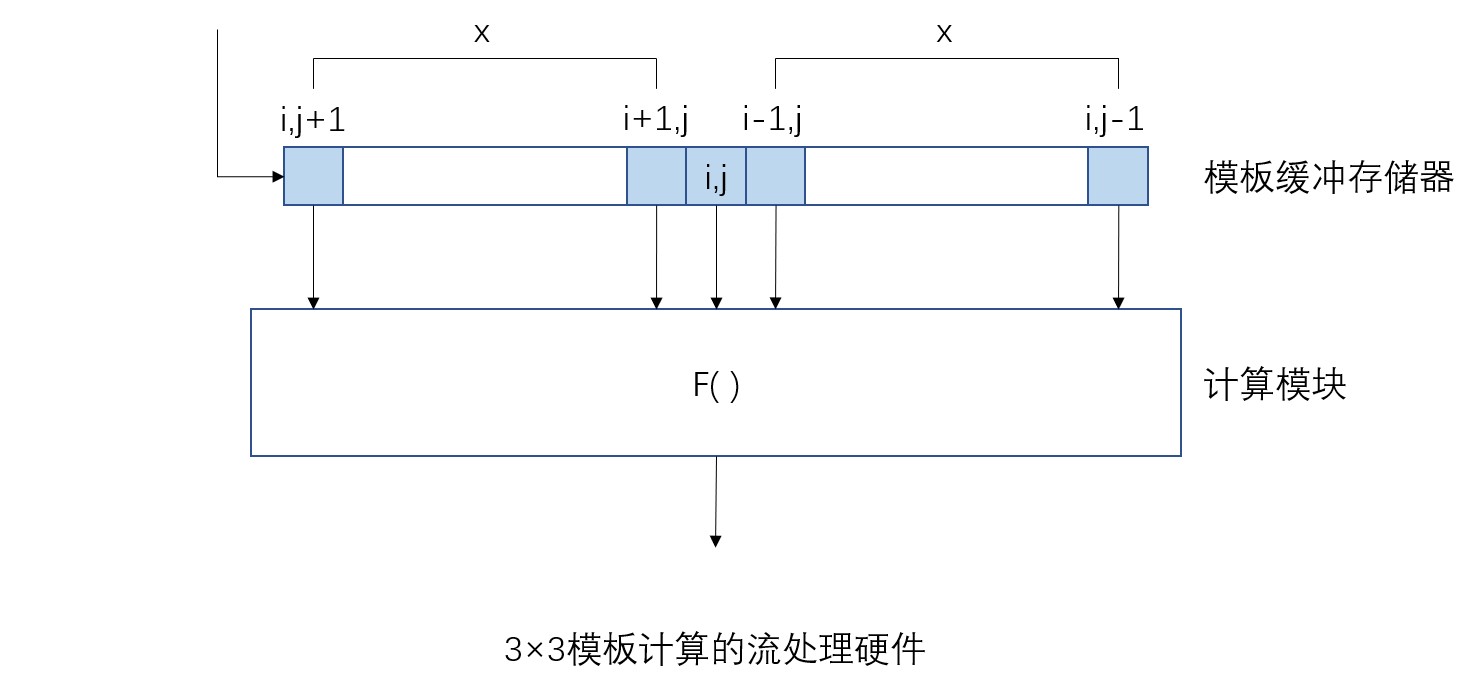
处理核中的函数F()负责进行3×3模板运算,从5个输入数据计算元素(i,j)的值。该运算不但涉及当前输入元素的值,还要用到之前和之后输入的元素,因此需要使用延迟缓冲存储器来实现。这里的缓冲存储器也被称为模板缓冲存储器。
假设二维阵列的宽度为X,则模板缓冲器所使用的移位寄存器的长度为(2X+1),并如上图所示有5个读取端口分别对应输入。在目标元素(i,j)输入之后的第X个时钟周期,该元素正好移动到模板缓冲器的中央,此时可以同时读取星形模板内的五个数据。计算模块就可以使用这些数据一次性算出(i,j)的值。因此,二维模板计算的缓冲器大小和阵列宽度成正比。而三维模板计算比二维需要更大的缓冲器,可能会有片上存储容量不足的情况发生。此时,可以采用将阵列分割成多个小型的子阵列,再依次逐一处理的方法。
告辞。