{kind=link}
处理器流水线介绍
11 Aug 2019 3792字 13分 次 Digital IC Design打赏作者 CC BY 4.0 (除特别声明或转载文章外)
1 处理器流水线概述
1.1 经典的五级流水线
经典MIPS五级流水线如图所示:
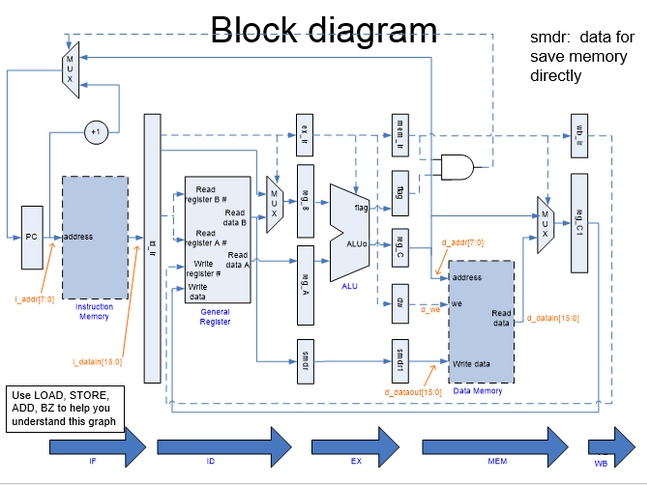
在此流水线中一条指令的生命周期分为以下步骤:
- 取值:取指令是指将指令从存储器中都出来的过程。
- 译码:指令译码是指将从存储器中取出的指令进行翻译的过程。经过译码之后得到的指令需要的操作数寄存器索引,可以使用此索引从通用寄存器组(Register File,Regfile)中将操作数读出。
- 执行:指令译码之后所需要进行的计算类型都已得知,并且已经从通用寄存器组中读取出了所需的操作数,那么之后便进行指令执行。指令执行是指对指令进行真正运算的过程。在“执行”阶段的最常见部件为算术逻辑部件运算器(ALU),作为实施具体运算的硬件功能单元。
- 访存:存储器访问指令往往是指令集中最重要的指令类型之一,访存是指存储器访问指令将数据从存储器中读出,或写入存储器的过程。
- 写回:写回是指将指令执行的结果写回通用寄存器组的过程。如果是普通运算指令,该结果值来自于“执行”阶段计算的结果;如果是存储器读指令,该结果来自于“访存”阶段从存储器中读取出来的数据。
在处理器中采用流水线设计有助于提高处理器的性能。以上述五级流水线为例,由于前一条指令在完成了“取指”进入“译码”阶段后,下一条指令马上就可以进入“取指”阶段,以此类推。如果流水线没有停顿,理论上可以取得每个时钟周期都完成一条指令的性能。
1.2 流水线与状态机的关系
流水线的本质可以理解为一种以面积换性能、以空间换时间的手段,提高了性能,优化了时序,增加了吞吐率。
与流水线相对应的另外一种策略是状态机,状态机是流水线的取反,本质上可以理解为是一种以性能换面积、以时间换空间的手段。
流水线和状态机的关系是展开和折叠的关系。假设处理器不采用流水线而使用状态机来完成,则需要多个时钟周期才能完成一条指令的所有操作,每个时钟周期完成状态机的一个状态(分别为取指、译码、执行、访存和写回)。通过使用状态机,可以省掉上述流水线中的寄存器开销,还可以复用组合逻辑数据通路,因此面积开销比较小,但是每条指令都需要5个周期才能完成,吞吐率和性能很差。
8051内核就没有流水线。
1.3 流水线的深度
早期的经典流水线是五级流水线,现代的处理器往往具有极深的流水线级数,譬如高达十几级甚至二十几级的深度。流水线的级数越多,意味着流水线被切的越细,每一级流水线内容纳的硬件逻辑便越少。在两级寄存器(每一级流水线由寄存器组成)之间的硬件逻辑越少,则意味着能够运行到更高的主频。因此,现代的处理器流水线极深主要是由于处理器追求高频的指标所驱使。高端的ARM Cortex-A系列由于有十几级的流水线,所以能够运行到高达2GHz的主频,而Intel的x86处理器甚至采用几十级的流水线深度将主频推到3~4GHz的高度。主频越高也意味着流水线的吞吐率越高,从而性能越高。
由于每一级流水线都由寄存器组成,更多的流水線級數需要消耗更多的寄存器,以及更多的面积开销。
由于每一级流水线需要进行握手,流水线最后一级的反压信号可能会一直串扰到最前一级造成严重的时序问题,需要使用一些比较高级的技巧来解决此类反压时序问题。
由于在流水线的取指令阶段无法得知条件跳转的结果到底是跳还是不跳,因此只能进行预测,而到了流水线的末端才能够通过实际的运算得知该分支是真的该跳还是不该跳。如果发现真实的结果真实结果与预测结果不相符,则意味着预测失败,需要将所有预取的错误指令流全部丢弃,重新取正确的指令流,这个过程叫做“流水线冲刷”。虽然可以用分支预测器来保证前期的分支预测尽可能准确,但也无法做到万无一失。流水线的深度越深,意味着已经预取了更多的错误指令流,意味着浪费和损失越严重。
2 处理器流水线中的反压
流水线越深,由于每一级都要进行握手,流水线最后一级的泛亚信号可能会一直串扰到最前一级造成严重的反压时序问题,需要使用一些比较高级的技巧来解决这些时序问题,在现代处理器设计中,通常由如下三种方法:
- 取消握手:杜绝反压的发生,时序表现非常好,但流水线中的每一级并不会与其下一级进行握手,可能会造成功能错误或者指令丢失。因此这种方法往往需要配合其他的机制,譬如重执行、预留大缓存等。
- 加入乒乓缓存:是一种用面积换时序的方法,也是在解决反压的最简单方法。通过使用乒乓缓存(有两个表项)替换掉普通的一级流水线(只有一个表项),可以使得此级流水线向上一级流水线的握手接收信号仅关注乒乓缓存中是否有一个以上有空的表项即可,而无需将下一级的握手接受信号串扰至上一级。
- 加入向前旁路缓存:也是一种用面积换时序的方法,是在解决反压时的一种非常巧妙的方法。是在解决反压时的一种非常巧妙的方法。旁路缓存仅只有一个表项,由于增加了这一个额外的缓存表项,可以将后向的握手信号时序路径砍断,但是对前向路径不受影响,因此可以广泛使用于握手接口。
以上解决反压的技术方法,不仅在处理器设计中能够用到,而且在普通的ASIC电路设计中也会经常用到。
3 处理器流水线中的冲突
3.1 流水线中的资源冲突
资源冲突是指流水线中硬件资源的冲突,最常见的是运算单元的冲突,譬如除法器需要多个时钟周期才能完成运算。因此在前一个除法指令完成运算之前,新的除法指令如果也需要除法器,则会存在着资源冲突。在处理器的流水线中硬件资源冲突种类还有较多,在此不一一赘述。解决资源冲突可以通过复制硬件资源或者流水线停顿等待硬件资源的方法解决。
3.2 流水线中的数据冲突
数据冲突是指不同的指令之间的操作数存在着数据相关性造成的冲突,常见的数据相关性如下:
- WAR(Write-After-Read)相关性,又称先读后写相关性,表示“后序执行的指令需要写回的结果寄存器索引”与“前序执行的指令需要读取的源操作数寄存器索引”,相同造成的数据相关性。因此从理论上来讲,在流水线中“后序指令”一定不能比和它有WAR相关性的“前序指令”先执行,否则“后序指令”先写回了结果至通用寄存器组中,“前序指令”再读取操作数时,就会读到错误的数值。
- WAW(Write-After-Write)相关性,又称先写后写相关性,表示“后序执行的指令需要写回的结果寄存器索引”与“前序执行的指令需要写回的结果寄存器索引”相同,造成的数据相关性。因此从理论上来讲,在流水线中“后序指令”一定不能比和它有WAW相关性的“前序指令”先执行,否则“后序指令”先写回了结果至通用寄存器组中,“前序指令”再写回结果至通用寄存器组中就会将其覆盖。
- RAW(Read-After-Write)相关性,又称先写后读相关性,表示“后序执行的指令需要读取的源操作数寄存器索引”与“前序执行的指令需要写回的结果寄存器索引”。相同造成的数据相关性。因此从理论上来讲,在流水线中“后序指令”一定不能比和它有RAW相关性的“前序指令”先执行,否则“后序指令”便会从通用寄存器组中读回错误的源操作数。
以上的3种相关性中,RAM属于真数据相关。
解决数据冲突的常见方法如下:
- WAW 和WAR 可以通过寄存器重命名的方法将相关性去除,从而无须担心其执行顺序。
- 之所以称RAW为真数据相关,是因为其没有办法通过寄存器重命名的方法将相关性去除。一旦产生RAW相关性,后序的指令一定要使用和它有RAW数据相关性的前序指令执行完成的结果,从而造成流水线的等待停顿。为了能够尽可能减少流水线停顿带来的性能损失,可以使用“动态调度”的方法。动态调度的思想本质上可以归结于以下方面:
- 一方面采用数据旁路传播(Data Bypass and Forward)技术,尽可能让前序指令的计算结果更快地旁路传播给后序相关指令的操作数。
- 另一方面尽可能地让后序相关指令在等待的过程中不阻塞流水线,而让其他无关的指令继续顺利执行。
- 早期的Tomasulo算法中通过保留站可以达到这两方面的功效,但是保留站由于保存了操作数,无法做到很大的深度(否则面积和时序的开销巨大)。
- 最新的高性能处理器普遍采用在每个运算单元前配置乱序发射队列(Issue Queue)的方式,发射队列仅追踪RAW相关性,而并不存放操作数,因此可以做到很深(譬如16个表项)。在发射队列中的指令一旦相关性解除之后,再从发射队列中发射出来读取物理寄存器组(Physical Register File),然后发送给运算单元开始计算。
4 E200处理器的流水线
4.1 流水线总体结构
蜂乌E200处理器的总体结构如图所示:
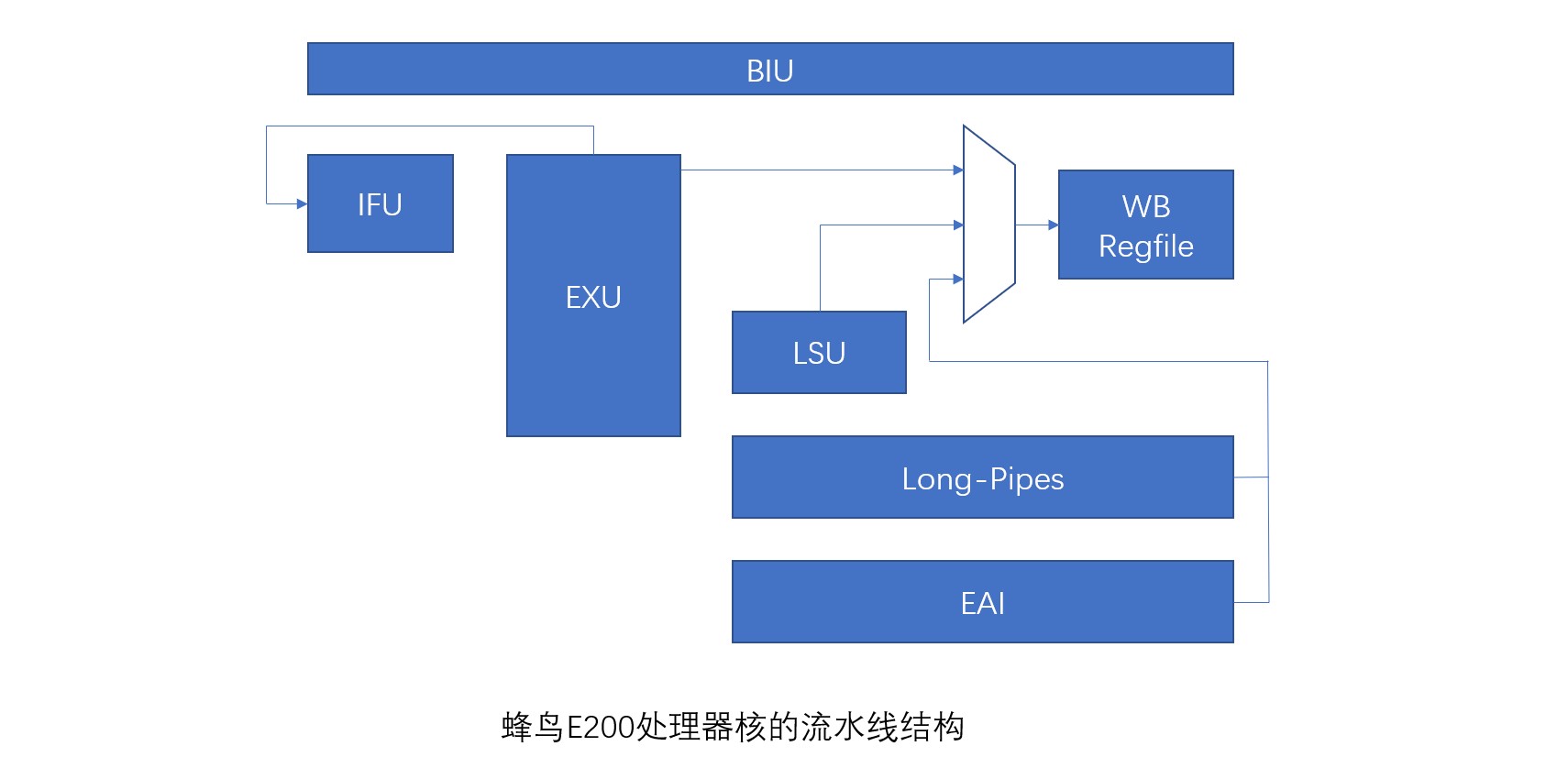
要点如下:
- 流水线的第一级为“取指(由IFU 完成)”。
- 蜂鸟E200处理器核很难严谨界定它的完整流水线级数为几级,原因如下:
- “译码(由EXU 中完成)”“执行(由EXU中完成)”和“写回(由WB 完成)”均处于同一个时钟周期,位于流水线的第二级。
- 而“访存(由LSU 完成)”阶段处于EXU之后的第三级流水线,但是LSU写回的结果仍然需要通过WB 模块写回通用寄存器组(Register File, Regfile)。
- 因此严格来讲,峰鸟E200是一个变长流水线结构。
- 由于蜂鸟E200 处理器核的流水线的按序主体是位于第一级的“取指”和位于第二级的“执行”和“写回”,因此我们非严谨地定义蜂鸟E200 处理器核的流水线深度为二级。
告辞。