{kind=link}
CPU设计之处理器
28 Oct 2019 14712字 50分 次 Digital IC Design打赏作者 CC BY 4.0 (除特别声明或转载文章外)
1 关于CPU
CPU的处理器通常使用流水线处理技术,将处理操作分为多个阶段,然后像流水线作业一样执行。
1.1 流水线的划分
CPU中的各种硬件资源只在处理的相应阶段使用,其他时间大多处于空闲状态,为了搞高效使用这些硬件资源,引入流水线处理技术。流水线处理中,处理的各个阶段被称为流水线级,各个流水线级的处理时间应尽量相等。有关流水线的具体内容可以去硬件算法之流水线结构中查看。
本设计采用的流水线划分为五个阶段,如下图所示:
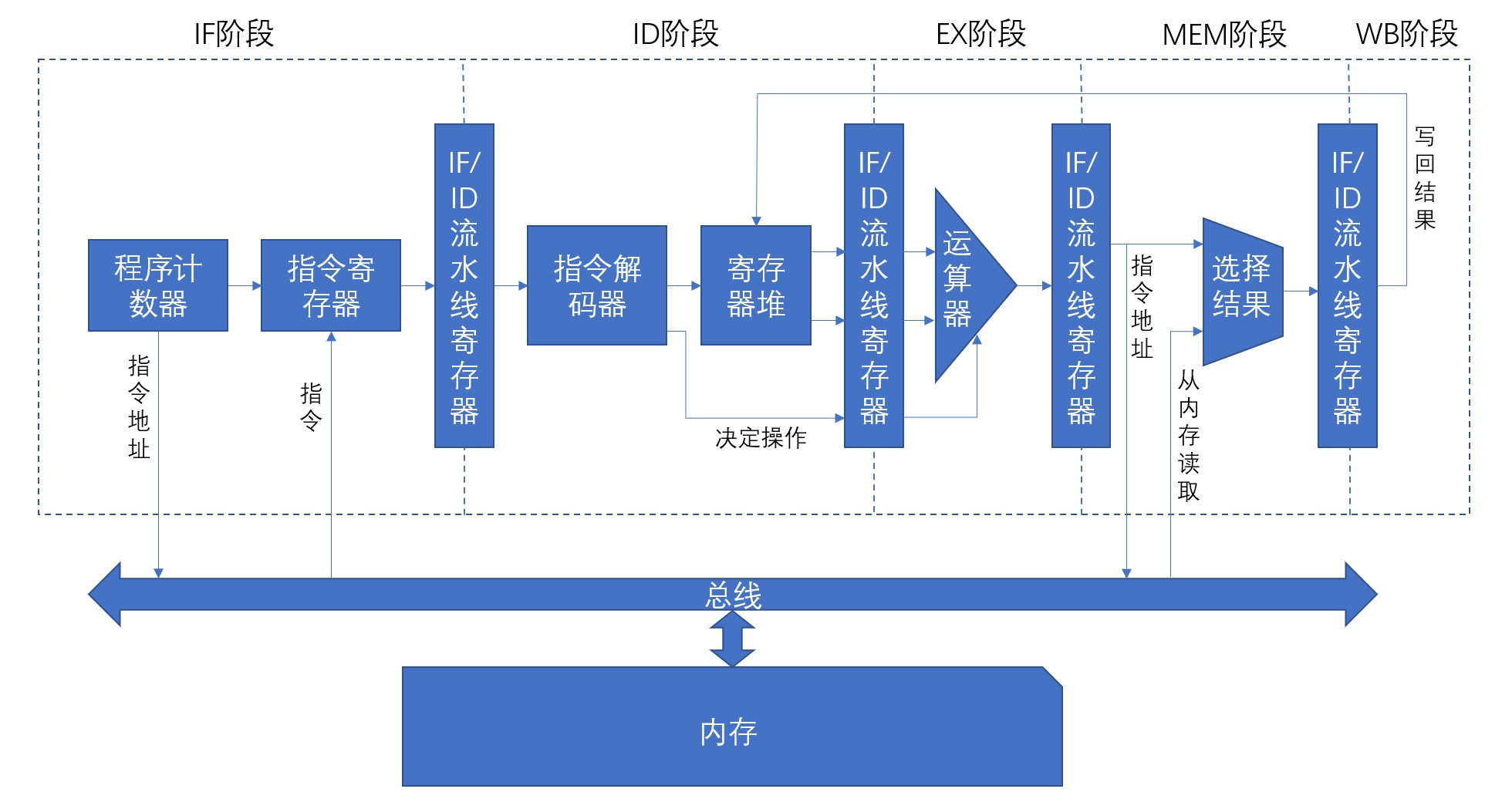
- IF(Instruction Fetch)阶段:将PC的值发送到内存,读取指令;
- ID(Instruction Decode)阶段:将读取的指令解码并决定将要进行的操作,从寄存器堆读取数据;
- EX(Execution)阶段:使用运算器(ALU)执行操作;
- MEM(Memory Access)阶段:进行内存访问;
- WB(Write Back)阶段:将结果写回寄存器堆。
1.2 流水线的冒险
流水线处理中,由于各个阶段的依赖关系、硬件资源的竞争等原因,会出现操作无法执行的情况。造成流水线故障的原因称为冒险,冒险分为构造冒险、数据冒险和控制冒险三种类型。
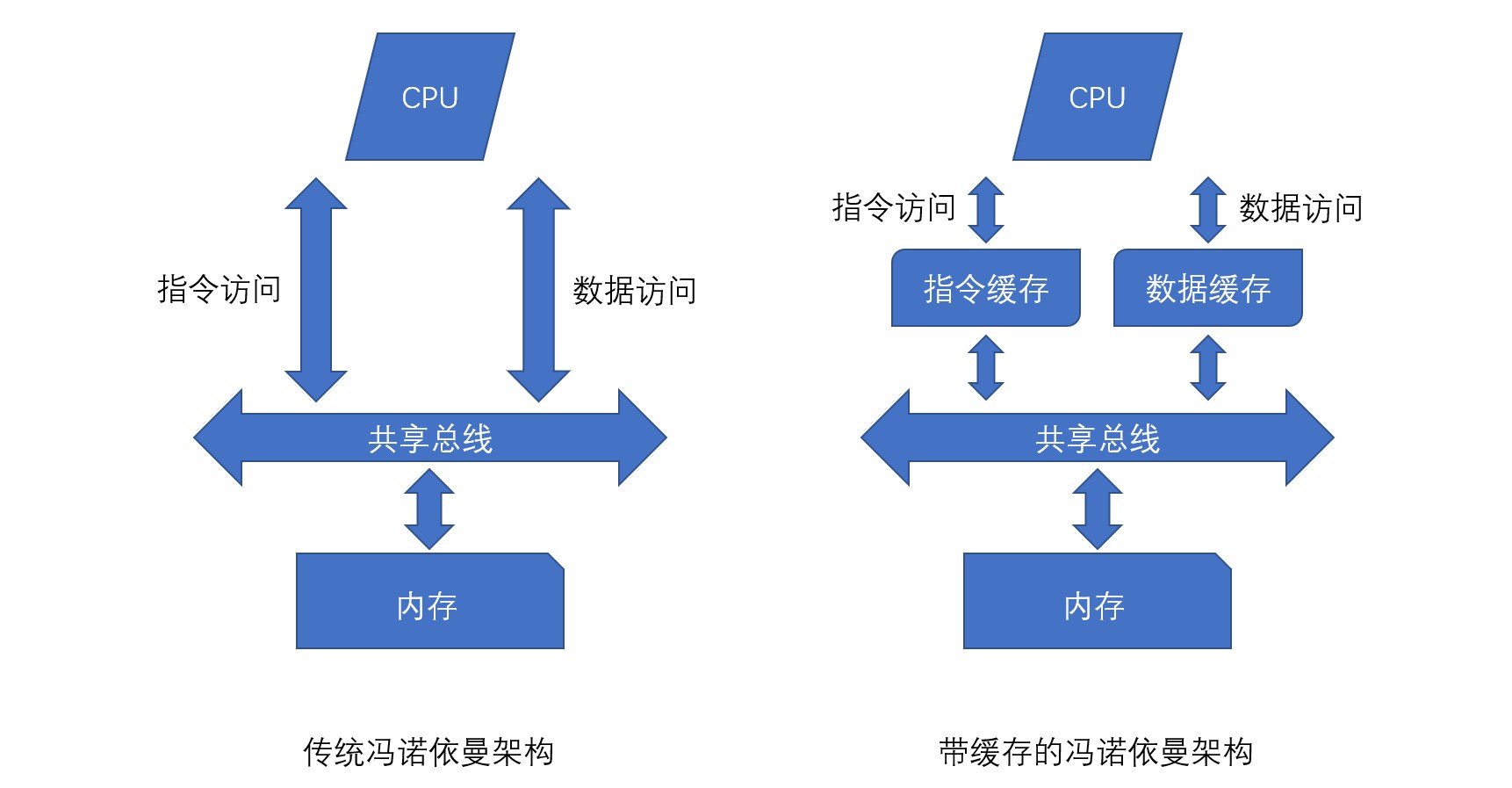
构造冒险是指由于硬件资源的竞争,操作无法同时执行的情况。上图所示的流水线结构中,内存访问会造成构造冒险,因为IF阶段和MEM阶段都要涉及内存访问。这种指令和数据使用同一通道的构造称为冯诺依曼架构,如果指令用的内存和数据用的内存分别设置,即可解决构造冒险,即哈佛架构。
如果导致冒险产生的硬件资源数量足够多的,也可以避免冒险问题的发生。
近年来,大部分CPU的指令和数据都放在同一内存中。但CPU直接访问的换成基本上都分为指令用和数据用两种,称为指令缓存和数据缓存,通过两种缓存的使用,解决了指令访问和数据访问之间发生的构造冒险问题:
数据冒险是指由于指令执行所需要的数据还未准备好所引起的冒险情况。当即将执行的指令依赖于还未处理完成的数据时,会导致指令无法立刻开始执行,引发数据冒险。
为了回避数据冒险,可以使用一组称为直通(Forwarding)的方法。原本回写运算结果是在WB阶段,但实际上觉得运算结果是在EX阶段。因此直通是指在运算结果确定的EX阶段,将数据直接传递给下一个指令。
直通的示例如下图:

图中流水线执行3条有数据依赖关系的指令,以此说明直通的动作原理。第二条指令要使用第一条指令的结果。第一条指令在EX阶段可以确定运算结果后,直接将结果发送到处于ID阶段的第二条指令。第三条指令同时依赖于第一和第二条指令。因此,可以直接从处于MEM阶段的第一条指令和处于EX阶段的第二条指令获取数据。以这种将运算结果直通的方式,可以消除原本需要等待WB阶段完成的依赖关系。
使用直通解决依赖关系的方法仅有一个例外,就是数据需要使用load指令从内存调取的情况。由于内存的访问在MEM阶段执行,因此处理结果要在MEM阶段才能确定。而当前指令执行到MEM结束时,下一条指令已经到达EX阶段执行了。这与直通的机制不吻合。
这种依赖load指令而发生的冒险称为load冒险。load冒险不能从根本上避免,因此要将有依赖关系的指令进行阻塞以解决该问题。阻塞是指让流水线的特定阶段停止一段时间。load冒险发生时的流水线动作如下图:
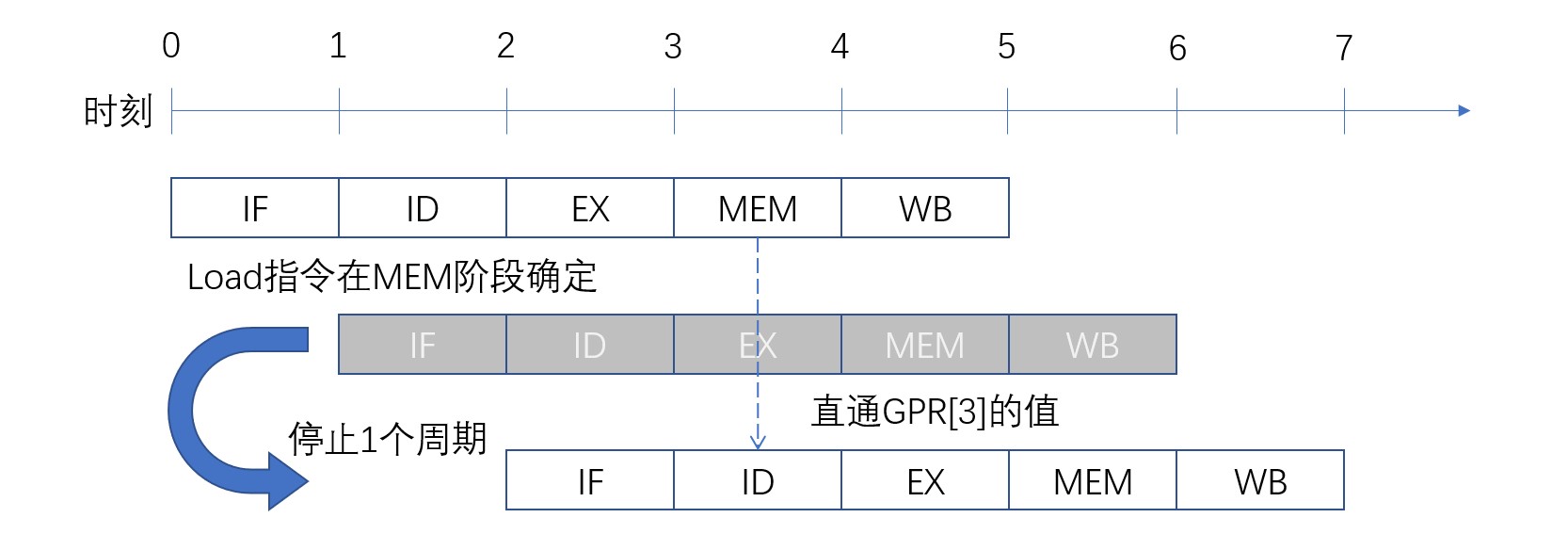
如果有load冒险发生,则将有依赖关系的指令延迟一个周期执行。如果将指令阻塞一个周期,前一条指令在MEM阶段得到的数据就可以直通正在ID阶段的下一条指令。这时候流水线会浪费一个周期,这一周期让其传递无效的数据即可。这个操作称为流水线冒泡。如果load指令与和其有依赖关系的指令相差一条以上指令的距离,则不会发生load冒险。
控制冒险是指无法确定下一条指令而引发的冒险情况。在执行可能会改变下一条指令的分支指令时,在这一条指令执行结果确定之前下一条指令无法开始执行,从而引发控制冒险。
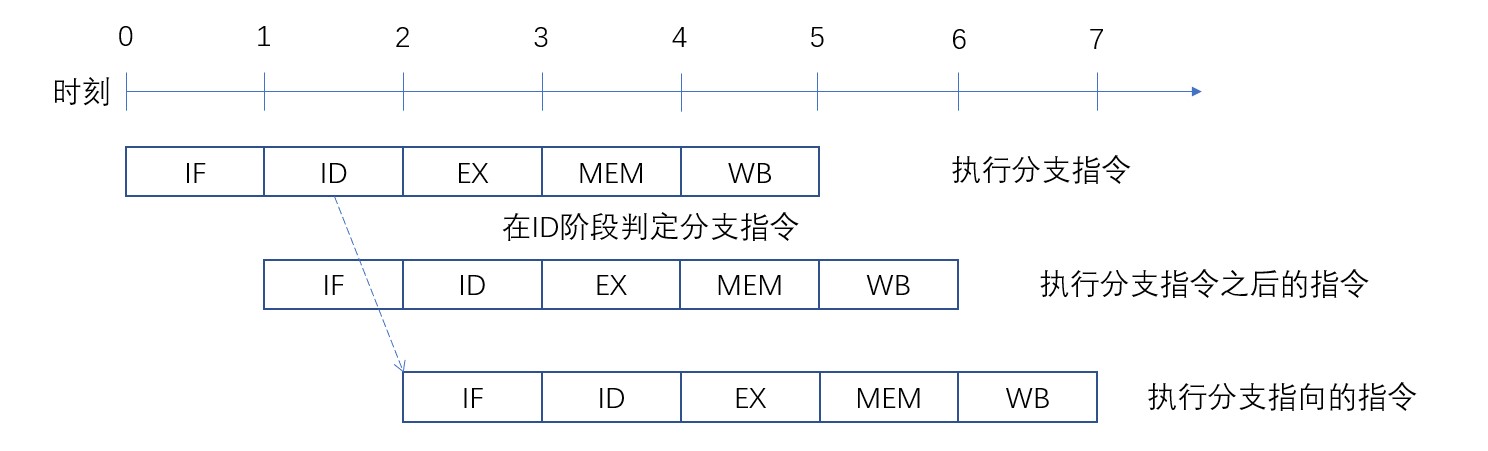
控制冒险也无法从根本上避免,但是可以尽量将分支指令安排到流水线前段,从而减少因为控制冒险而引起的无效指令数量。比如在ID阶段判定分支后,延迟一个周期就可以开始执行分支指向的下一条指令。控制冒险发生时的流水线动作如下图:
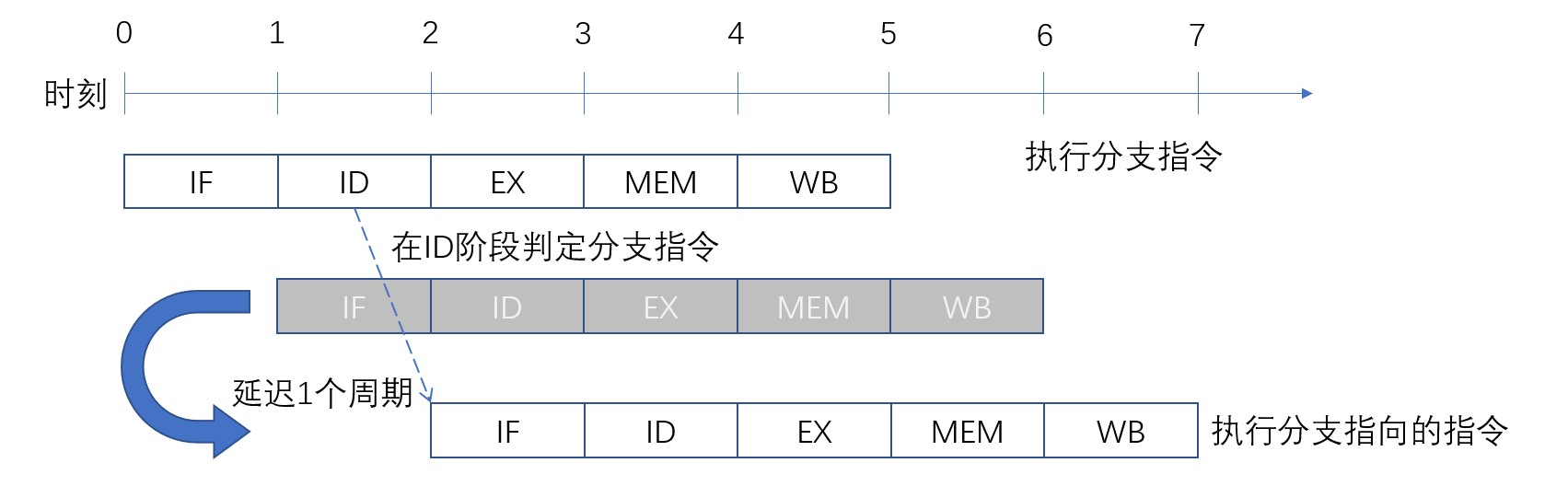
因为在读取下一条指令前需要确定PC寄存器的值,即使在ID阶段判断分支也会产生一个周期的延时。延迟期间会让流水线传送无效数据。流水线冒泡会浪费硬件资源,因此可以采用延迟分支的方法,许可分支指令的下一条指令执行。
延迟分支是指分支指令执行后并不立刻跳转到分支结果指向的指令,在分支指令的下一条指令执行完毕后再进行跳转。分支指令的下一条指令称为延迟间隙,不论分支是否成立都会被执行。使用延迟分支可以避免流水线冒泡,使操作的处理更有效率。一般的分支与延迟分支如下图:
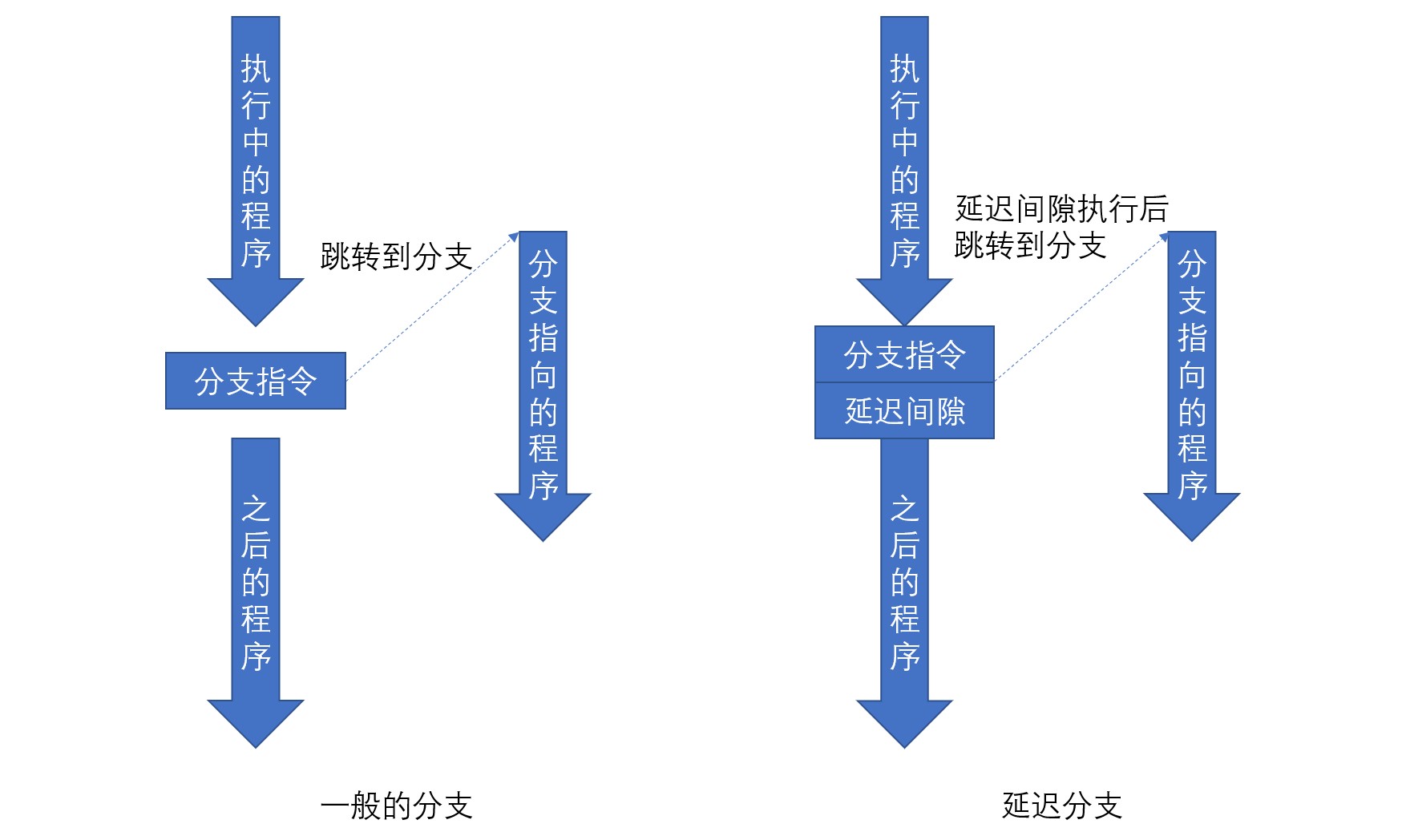
采用了延迟分支的流水线执行过程如下图:
1.3 CPU模式
大部分CPU至少有两种模式。全部指令可以无限制执行的模式称为内核模式(Kernel Mode)或管理者模式(Supervisor Mode);可执行的指令被限制的模式称为用户模式(User Mode),应用软件通常在用户模式下工作。
用户模式中被限制的操作包括CPU控制寄存器的访问、改变CPU状态的指令等等。
CPU的控制寄存器内有可以设置CPU模式的区域。在从高权限的内核模式转换到低权限的用户模式时,可以通过操作控制寄存器来实现。反之,如果要从低权限的用户模式转换到高权限的内核模式,需要使用专用的指令。
1.4 中断和异常
中断经常用在通知来自I/O的事件、处理程序执行中的异步事件等情况。发生中断时,CPU暂停当前操作,并跳转到中断处理程序。这时,CPU模式会变更到内核模式。 中断处理完成后返回到中断处继续执行。
异常是指CPU的执行产生了预期之外的结果。例如,遇到无法解码的指令、运算结果溢出以及操作违反权限等情况。遇到异常发生的情况时,CPU将暂时中断当前程序,跳转到异常处理程序。这时,CPU模式会变更到内核模式。 异常处理完成后,原则上将返回异常中断处。但如果发生致命错误会强制终止执行的程序。
中断和异常最大的区别在于发生的原因。中断是由外部因素引起的与正在执行的操作的异步情况,而异常是在正在执行的操作的内部发生的。由于都是暂停正在进行的操作并跳转到处理程序,有着相同的动作特征,中断和异常的处理本质上是一致的。
1.5 异常发生时的流水线动作
流水线化的CPU在异常发生时的处理稍有复杂。异常发生后,导致异常发生的指令以及其后的指令暂停执行,并跳转到异常处理程序。由于流水线化的CPU中的后续指令也在执行中。需要先将流水线内的所有数据缓存后,再将PC寄存器设置为异常处理程序地址,最后重启流水线。有异常发生时的流水线动作如下图:
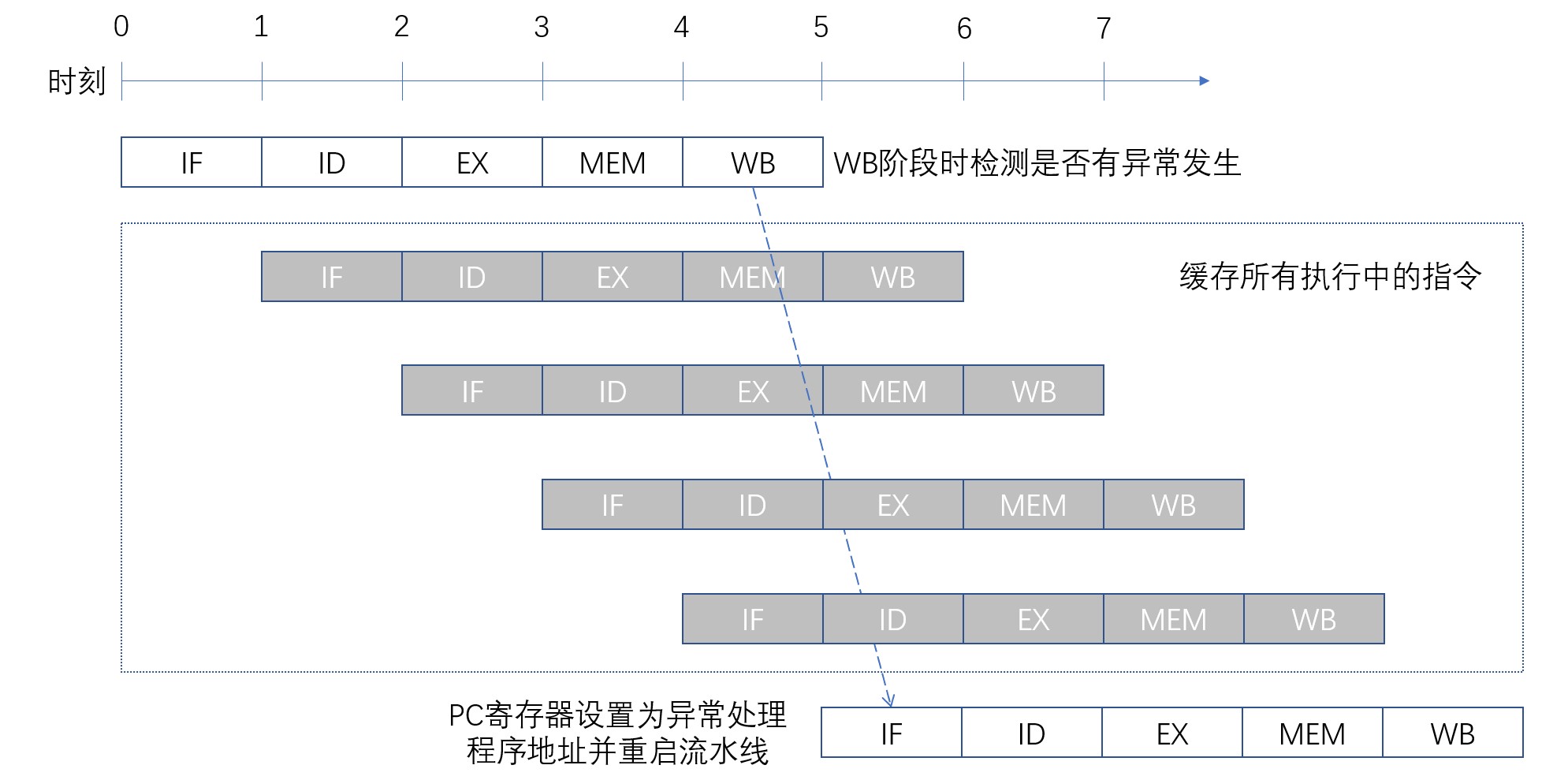
根据异常种类的不同,发生异常的流水线级也不同。因此异常发生时的动作较为复杂。最简便的方式是在流水线寄存器设置专用寄存器以标示异常发生的位置,最后在WB阶段检测是否有异常发生。因为操作结果的写回是在WB阶段,如果在WB级执行前将其内容缓存,指令就可以和从未执行过一样。
但是有一个另外,只有写入内存的存储指令,在MEM阶段就会将结果写入内存。因此为了使存储指令无效,需要判断内存写入前的指令是否发生异常。
2 指令集
2.1 指令格式
指令格式按照二进制代码内信息格式不同分为五类,如图:
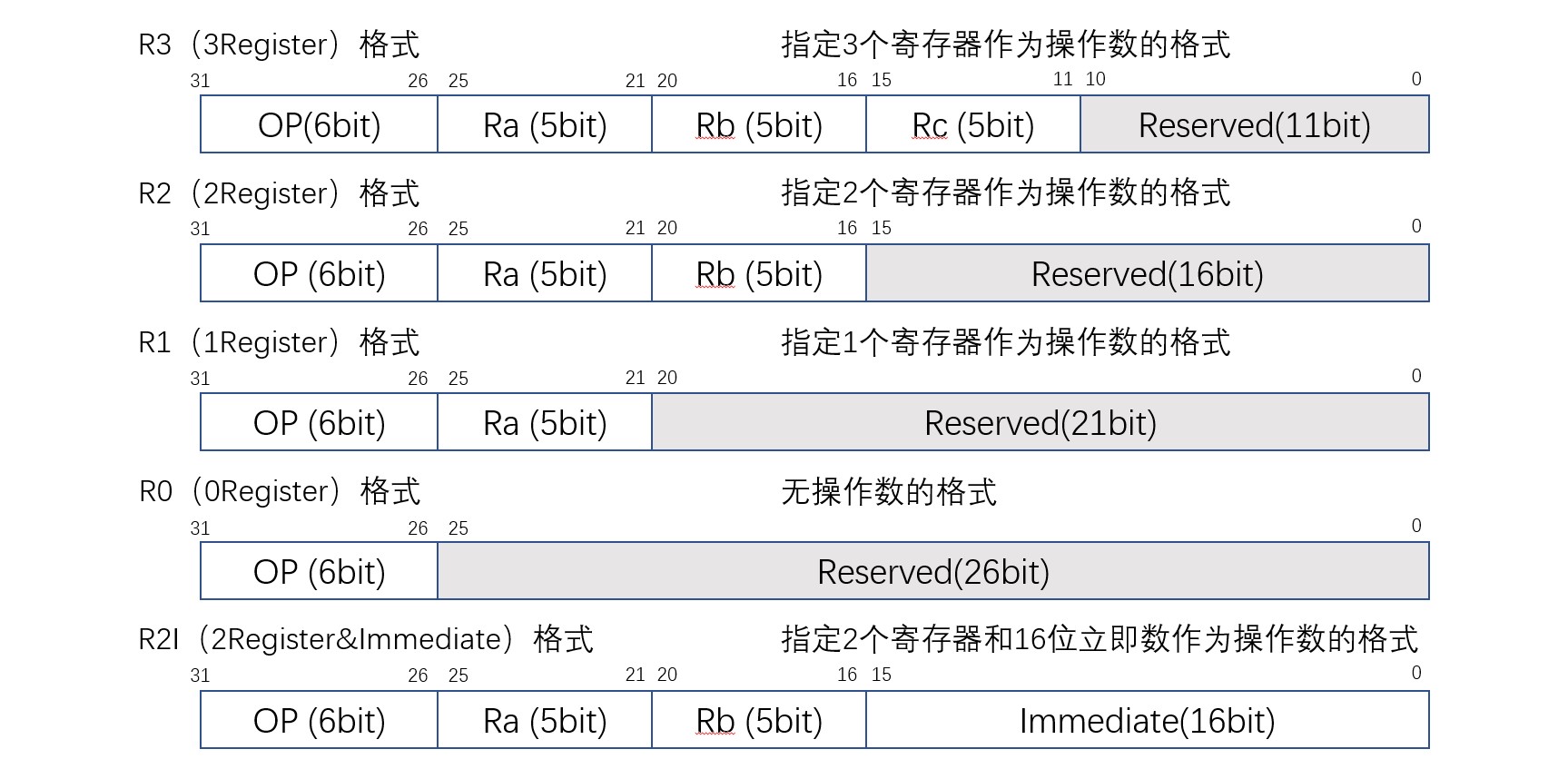
指令代码中各字段的说明如下表:
| 字段名 | 位置 | 位宽 | 含义 |
|---|---|---|---|
| OP(Opecode) | 31:26 | 6 | 操作码 |
| Ra(Register A) | 25:21 | 5 | 寄存器A的地址 |
| Rb(Register B) | 20:16 | 5 | 寄存器B的地址 |
| Rc(Register C) | 15:11 | 5 | 寄存器C的地址 |
| Immediate | 15:0 | 16 | 立即数 |
指令的最高6位用来定义操作码(Operation Code),指示指令进行的操作。剩余的位称为操作数(Operand),用来表示指令使用的寄存器的地址和立即数等。
立即数是指嵌入到指令字段中的常数。程序中经常出现使用常数的运算。例如循环递增、变量初始化等场合。如果CPU的指令只能使用寄存器,则需要将常数存储在内存并每次使用时加载。这种做法复杂且效率低下,因此指令中嵌入立即数这种方法非常有效。
指令如下表:
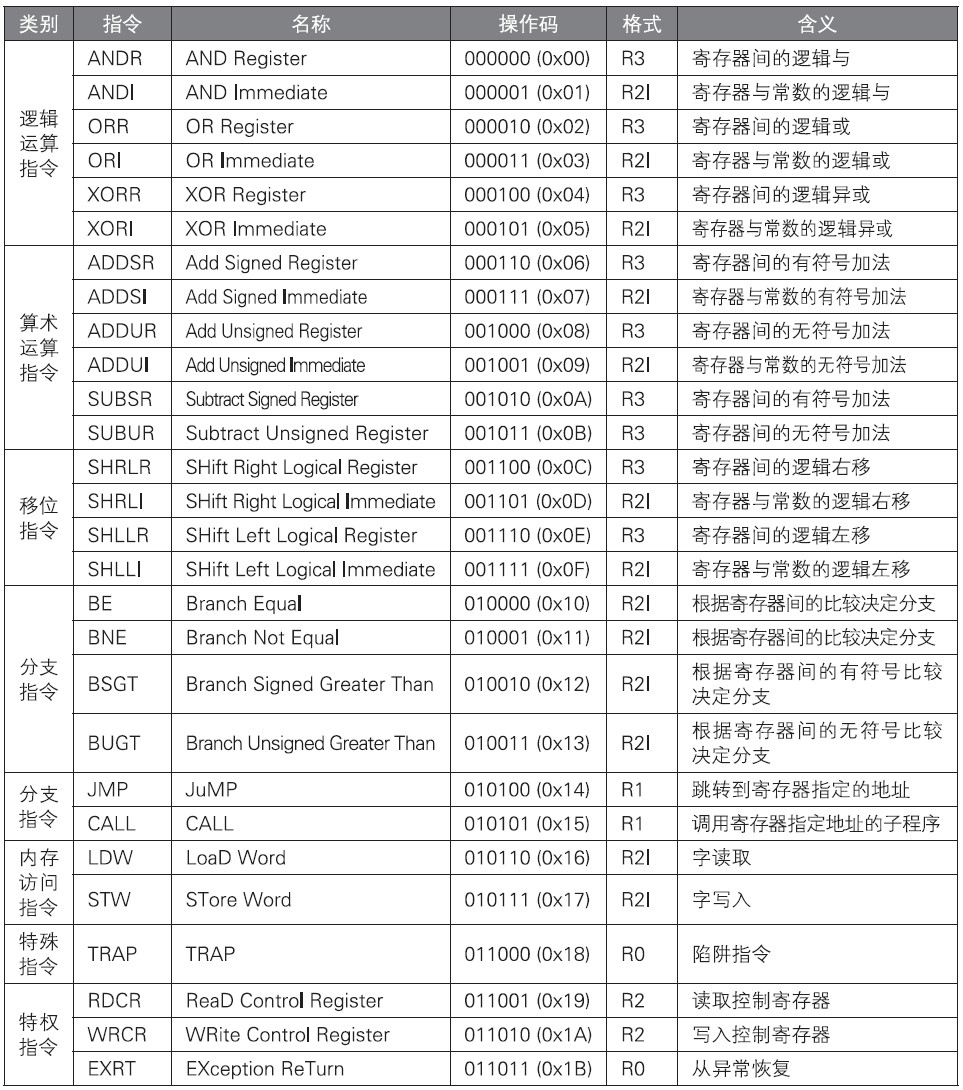
2.2 逻辑运算
逻辑运算指令对作为操作数的寄存器之间,或者寄存器与立即数之间进行逻辑运算,并将结果存入寄存器。逻辑运算指令有针对寄存器间逻辑运算的R3型,也有针对寄存器与立即数间逻辑运算的R2I型。逻辑运算指令如下表:
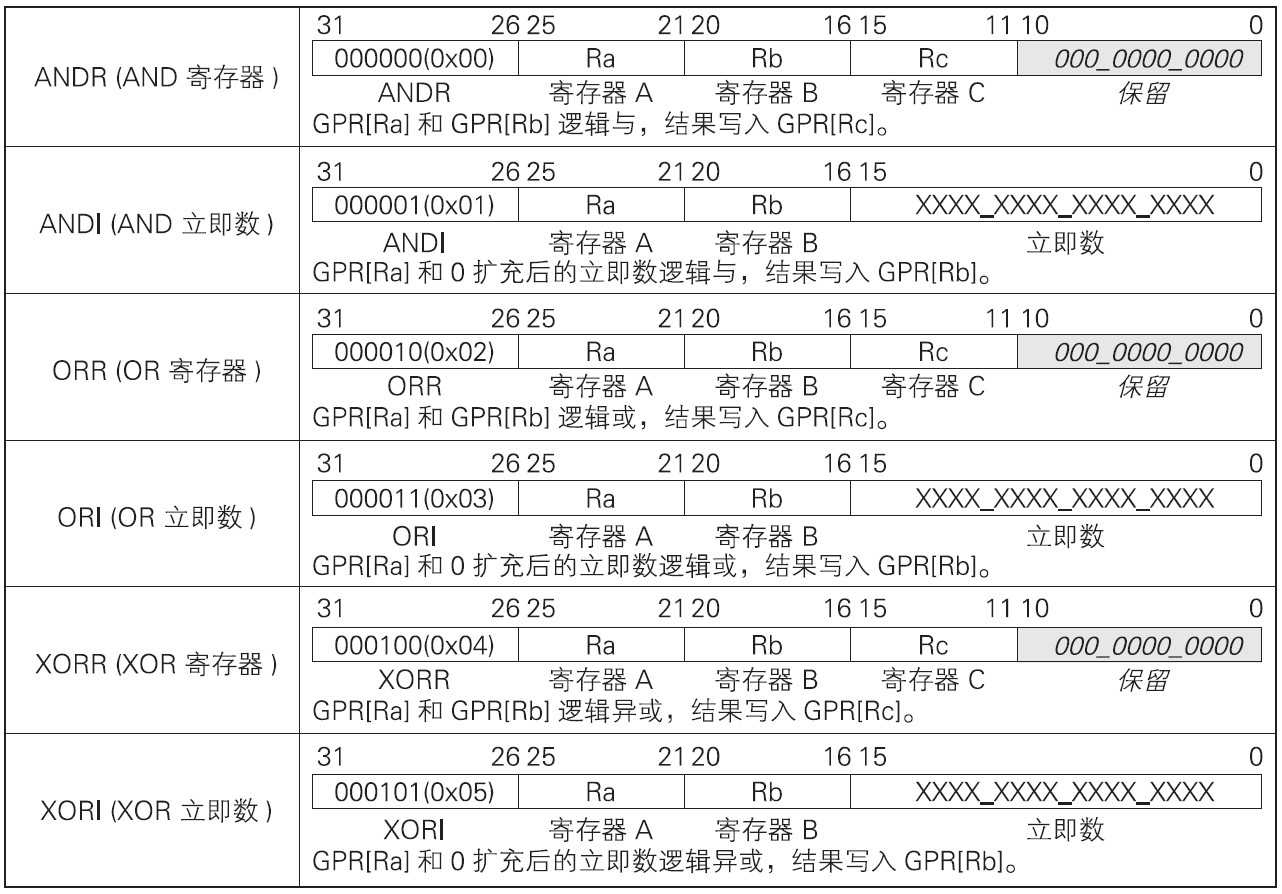
含有立即数的指令需要将16位的立即数扩充到32位后参与运算。扩充的方法有两种,一种是高16位全部用0填充的0扩充,一种是高16位用MSB(符号位)填充的符号扩充。这里使用0扩充。
2.3 算术运算
算术运算指令对作为操作数的寄存器之间,或者寄存器与立即数之间进行算术运算,并将结果存入寄存器。算术指令有针对性寄存器间算术运算的R3型,也有针对寄存器与立即数间算术运算的R2I型。算术指令如下表:
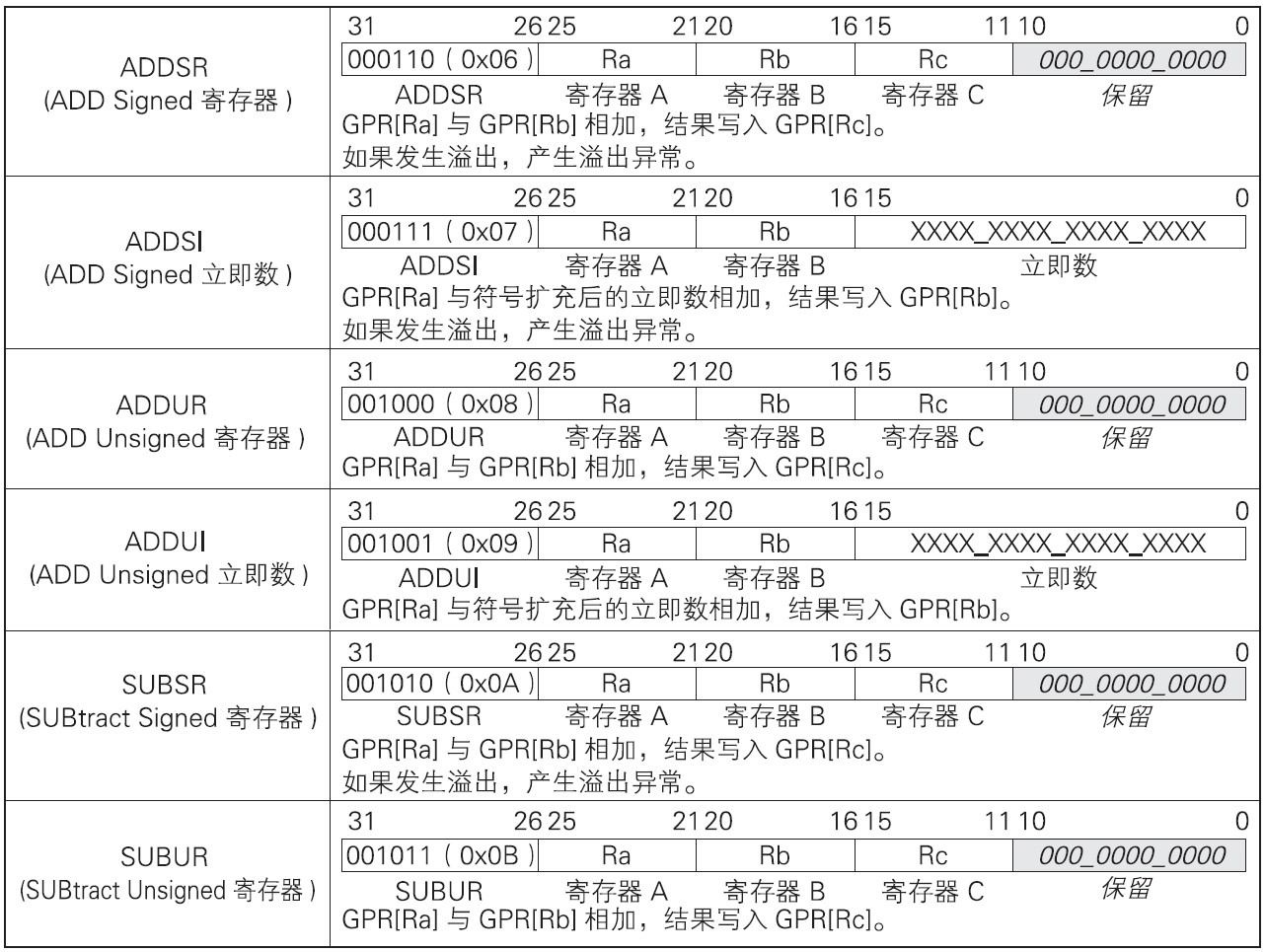
加法指令和减法指令分为有符号与无符号两类。这两种指令的区别在于是否检测溢出。
以八位数据间的加法运算为例进行说明。100(8’b01100100)加64(8’b01000000)结果为164(8’b10100100)。可以发现发生了向MSB(符号位)的进位。补码的8’b10100100十进制值为-92,不是正确答案。有符号8位正数的范围为-128~127,所以正确答案164不在范围内,溢出。
加法运算发生溢出有两种情况:“正数加正数得到负数”或“负数加负数得到正数”。减法运算发生溢出的情况有“负数减正数得到正数”和“正数减负数得到负数”。To summarize,符号位有错误就是溢出。如果运算结果有溢出,则产生溢出异常。
寄存器与立即数间的算术运算指令,立即数采用符号扩充。因此寄存器与立即数的算术指令中没有减法指令,立即数与负数相加和减法运算是等效的。
2.4 移位指令
移位指令对作为操作数的寄存器之间,或者寄存器与立即数之间进行移位,并将结果存入寄存器。
移位指令有针对寄存器间位移的R3型,也有针对寄存器与立即数间位移的R2I型。下表为位移指令:
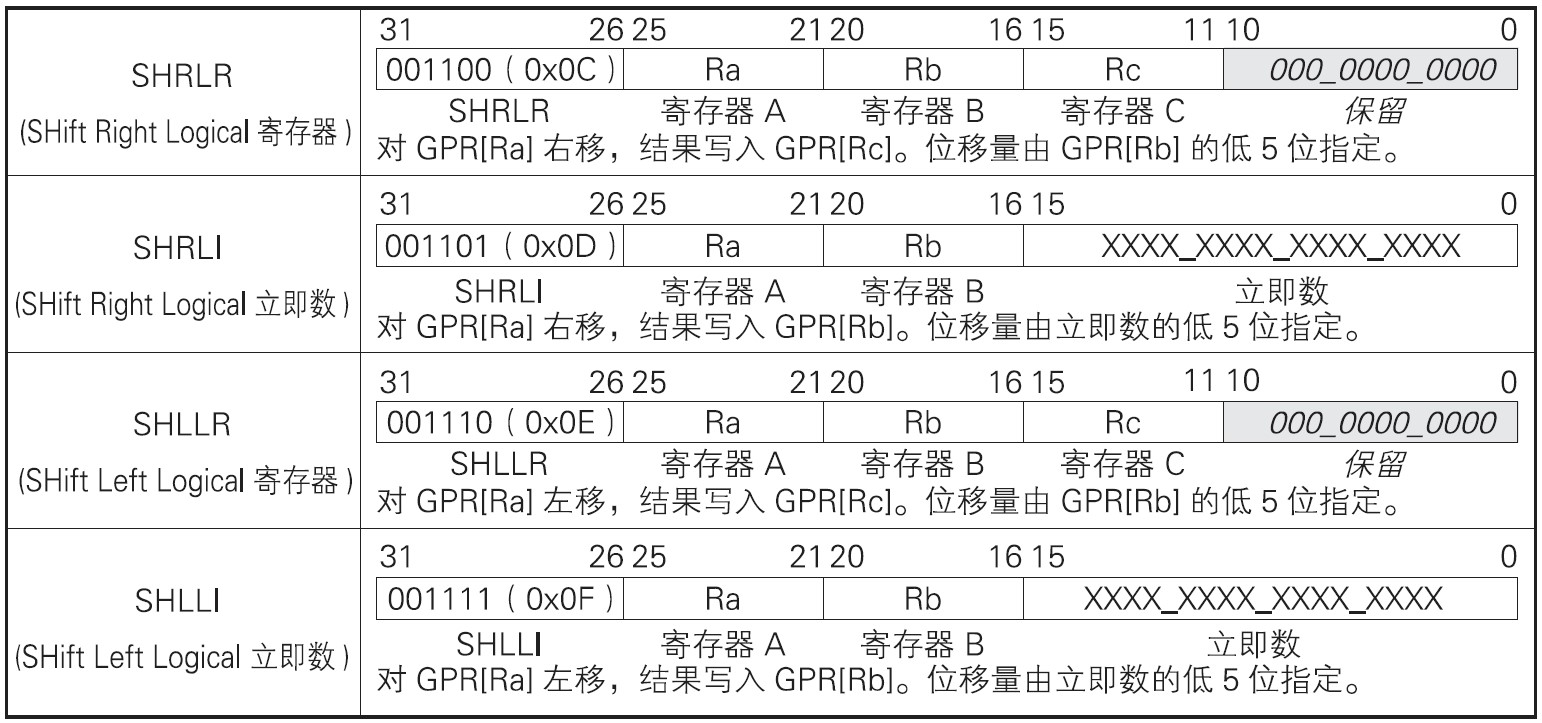
32位的二进制序列最大可移动32位。因此移位量用寄存器或立即数的最低5位(2的5次方为32)表示。
2.5 分支指令
分支指令是改变程序流程的指令。如果分支成立,那么下一条将要执行的指令就会被改变。由于采用了延迟分支处理,如果分支成立,要等到分支指令的下一条指令执行后再跳转到分支指向的指令。分支指令有R2I型条件分支指令和R1型无条件分支指令两种。分支指令如表所示:
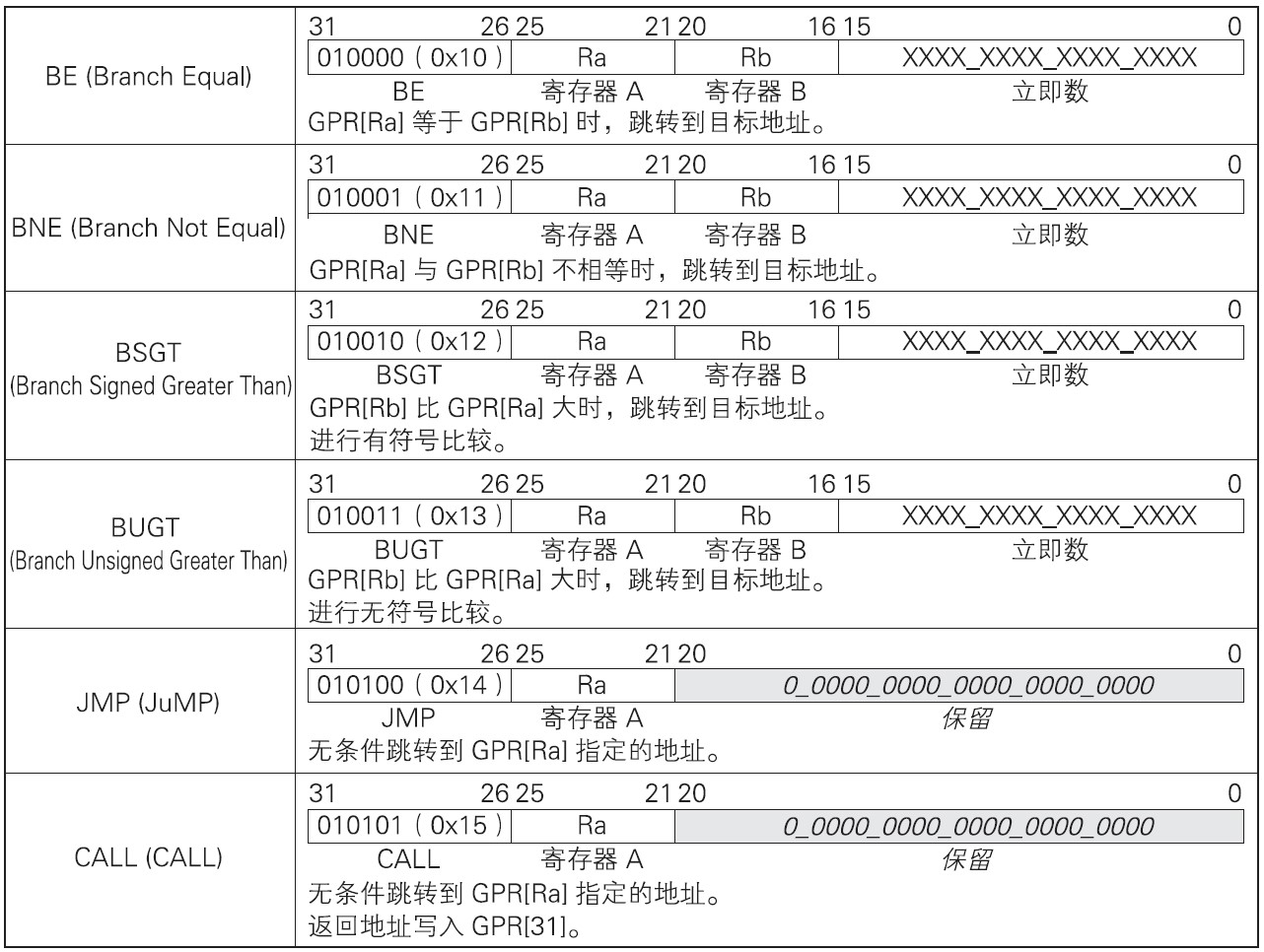
条件指令对寄存器进行比较,如果条件成立则跳转到目标地址。目标地址由PC寄存器与符号扩充后的立即数相加得到。立即数字段中指定的地址基于字(32位)编址方式进行计算,每个字分配一个地址。
目标地址要利用流水线寄存器中PC的值进行计算。因为PC中存放的是下一条指令的地址,所以目标地址为“下一条指令的地址+立即数”。使用PC值分支跳转到相对位置的方法称为PC相对分支。
BE指令在寄存器间的值相等和BNE指令在寄存器间的值不等时分支成立。BSGT指令与BUGT指令对通用寄存器(GPR)间的值进行比较,当条件GPR[Ra]<GPR[Rb]成立时分支成立。只是BSGT指令将寄存器的值作为有符号数值进行比较,而BUGT指令将寄存器的值作为无符号数值进行比较。
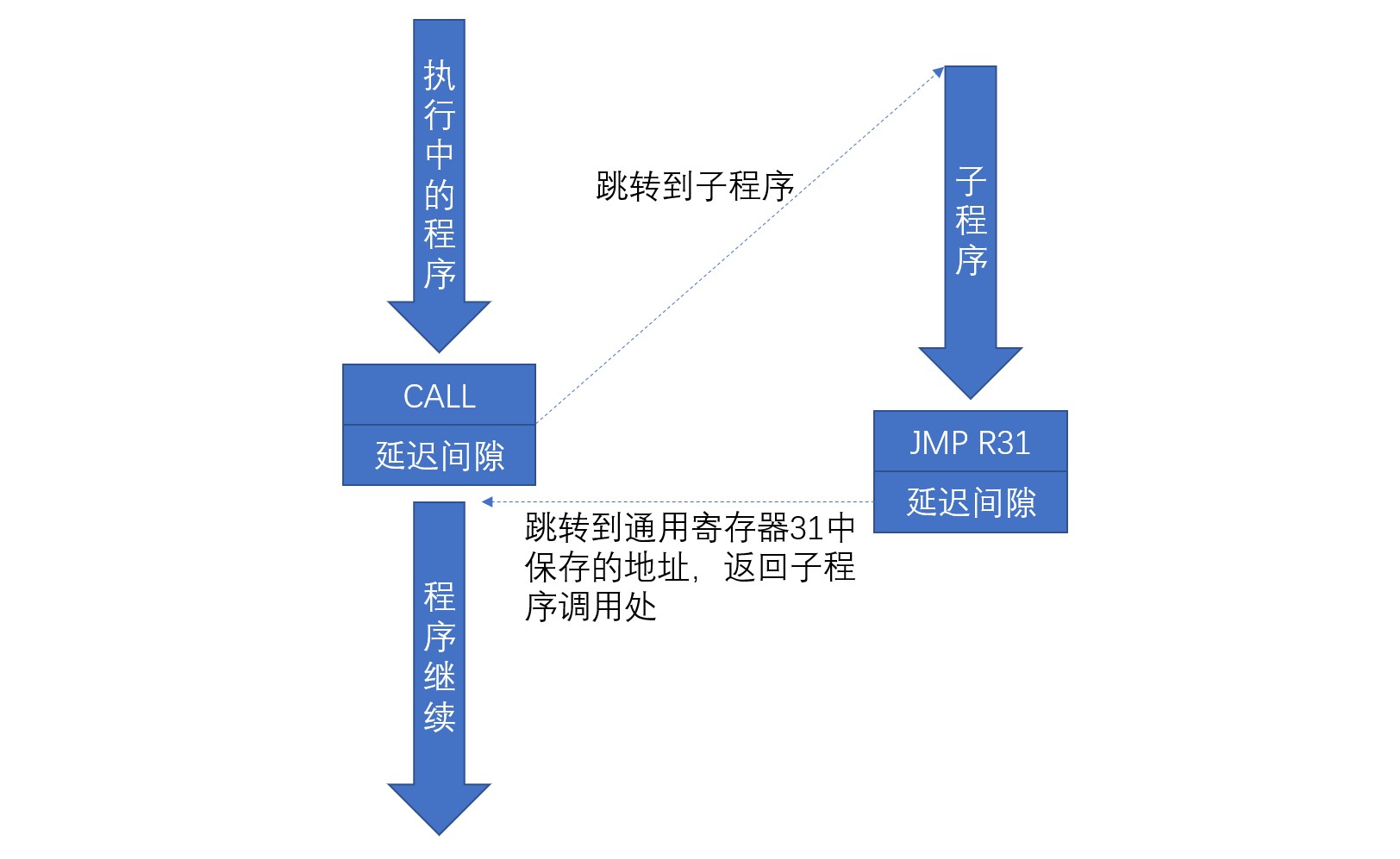
无条件分支指令会强制跳转程序。分支目标地址在寄存器中指定,这种分支称为寄存器间接分支。JMP指令用来强制跳转到寄存器指定的地址。CALL指令用来调用寄存器指定地址处的子程序。子程序的调用是指先执行子程序,处理完成之后返回到调用出的操作。
JMP指令与CALL指令都是无条件跳转语句,在这一点上两者效果是相同的。不同之处在于CALL指令在GPR31寄存器中存放两条之后指令的地址。由于CALL的下一条指令会被当做延迟间隙执行,所以GPR31中存放的地址为“CALL指令地址 +8”。因为存放了子程序调用处的地址,可以在子程序只需完成后返回。在返回时,使用通用寄存器31作为操作数并执行JMP指令。下图为子程序调用流程:
2.6 内存访问指令
内存访问指令用来从内存读取数据或向内存写入数据。内存访问指令格式为R2I型。下表为内存访问指令:
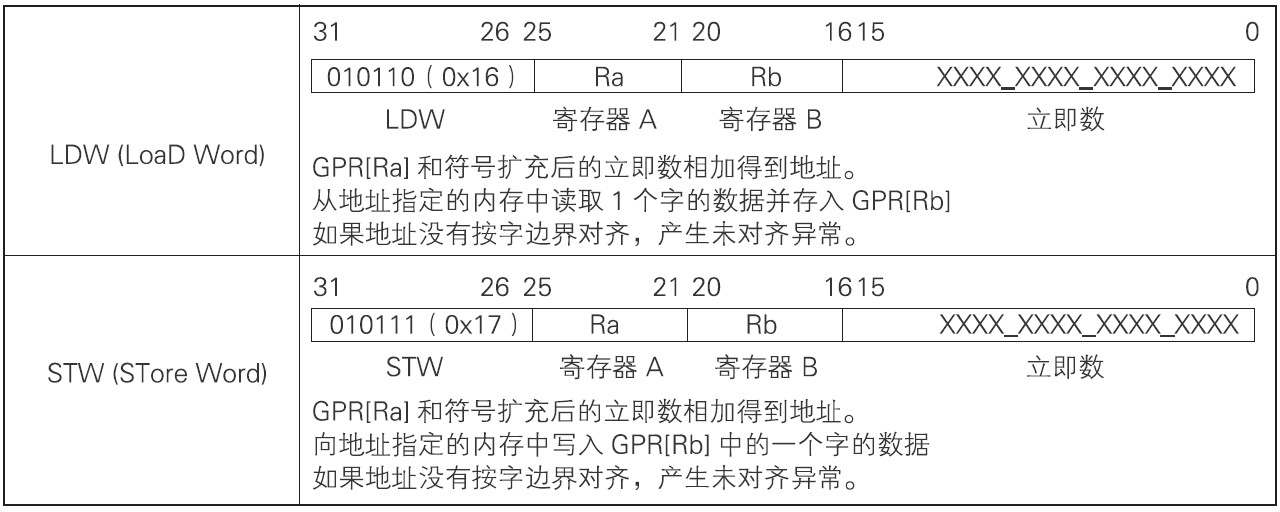
LDW指令用来从内存中读取1个字节的数据并存入寄存器中,读取地址由寄存器与符号扩充后的立即数相加得到。STW指令用来将寄存器中1个字的数值写入内存中,写入地址由寄存器与符号扩充后的立即数相加得到。这种地址指定的方式称为有偏移量的寄存器间接寻址。
执行内存访问指令时要对地址进行对齐检测。如果访问未对齐的地址,则会产生未对齐异常。对齐是指要访问数据的位置在单位数据的边界上。如果访问的地址跨过单位数据的边界线侧称为未对齐。
下图为对齐示例:
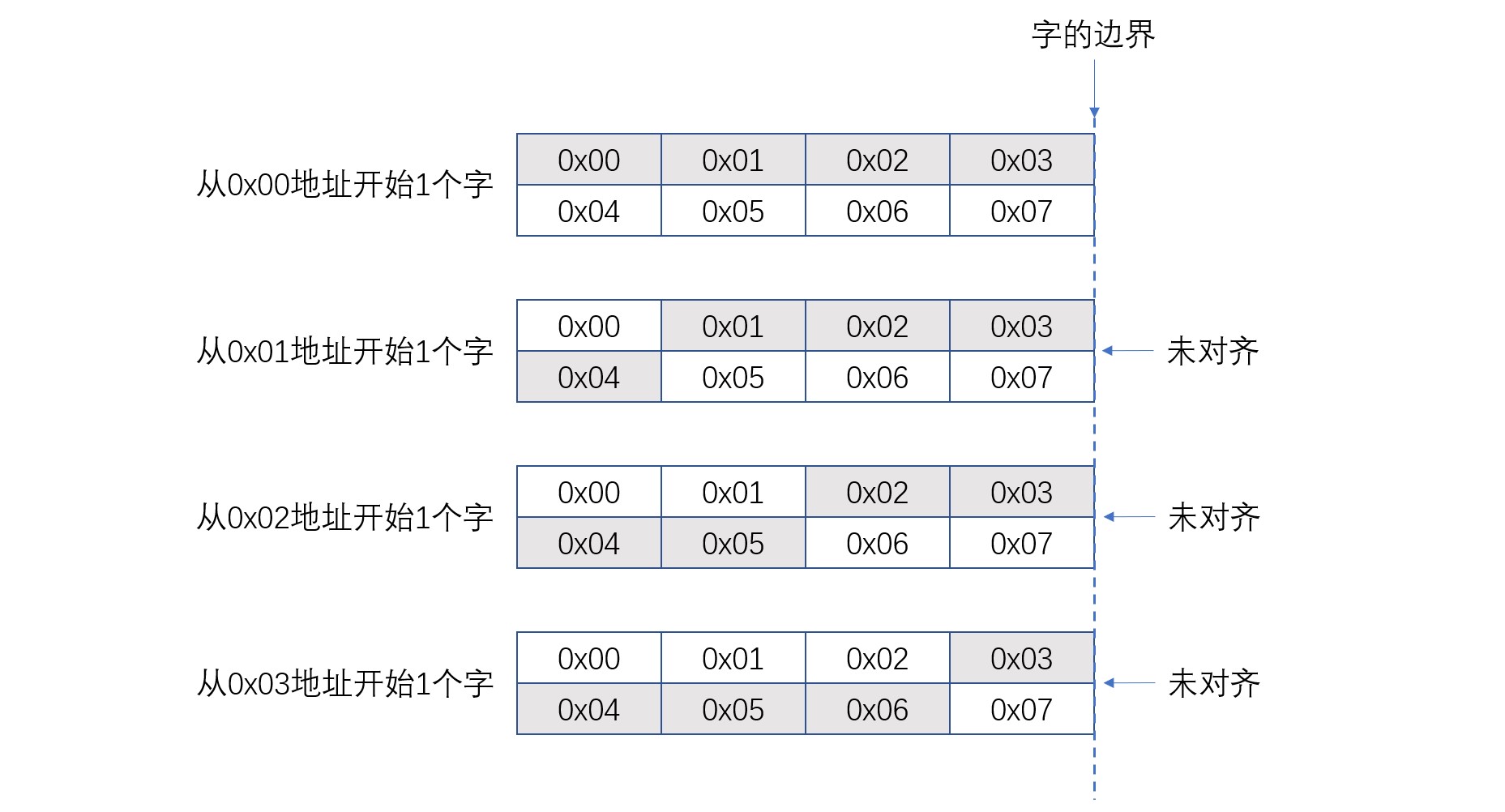
在按照字节对齐的地址空间中访问一个字(4字节)的数据时,如果起始地址为0x00,所访问的数据位于0x00到0x03,这时数据起始于字的边界,是对齐的。字边界是从0开始1个字长的区间。假如从0x01开始访问1个字的数据,所访问的数据位于0x01到0x04,这时,由于0x04属于下一个字的空间,数据跨越了字的边界。这种访问的地址就是未对齐的。同样,从0x02开始的1个字,从0x03开始的1个字都是未对齐的。未对齐会引起多次内存访问的问题。比如要访问从0x01开始访问1个字的数据,而0x01至0x03与0x04存放在不同的内存地址中。因此需要访问内存两次然后将数据进行组合。如果允许这种操作,硬件设计会变得复杂。因此在内存访问指令中进行对齐的检查,如果发生访问未对齐地址的情况,则产生未对齐异常。
2.7 特殊指令
特殊指令是用来故意引发异常的指令,它的主要用途是变更CPU模式。故意引发异常会转移到内核模式。下表为特殊指令:

执行TRAP指令的话会引发陷进异常。TRAP指令只用来引发异常,所以属于没有操作数的R0型指令。
2.8 特权指令
特权指令是只能在内核模式执行的特殊指令。通过特权指令可以实现CPU控制寄存器访问、从异常恢复等控制CPU状态的操作。特权指令如下表:
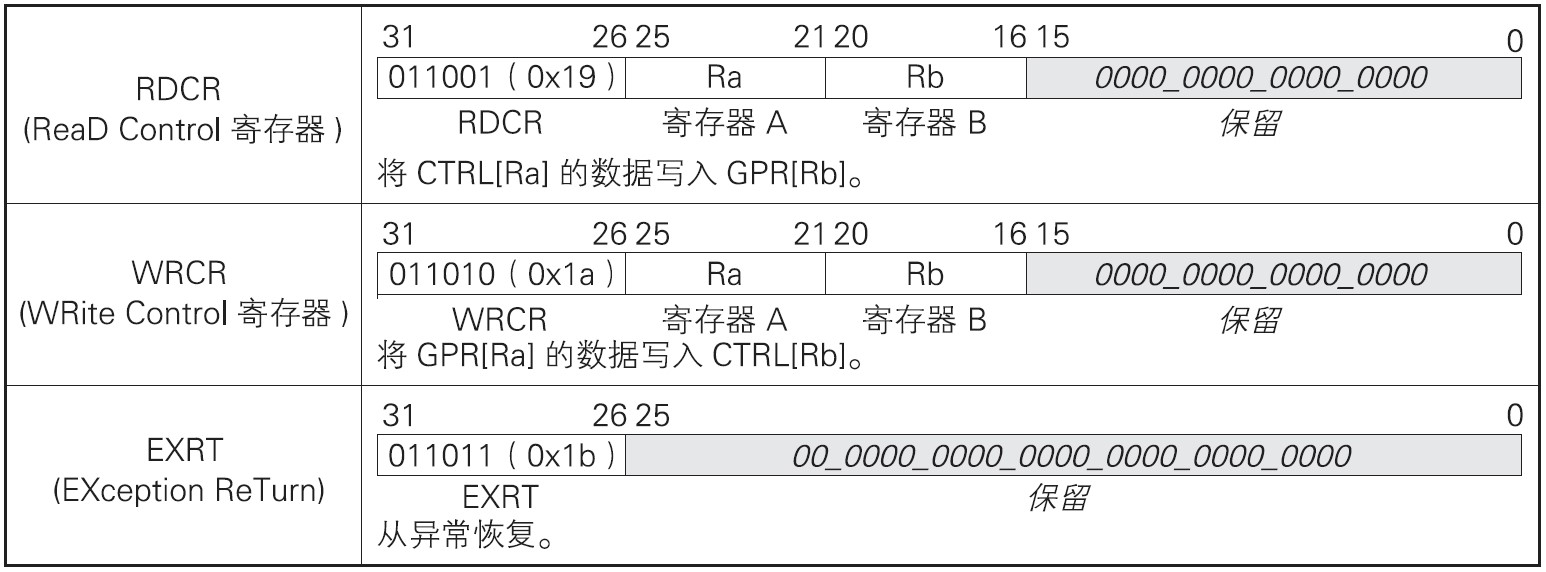
RDCR指令用来读取控制寄存器的值并写入通用寄存器; WRCR指令用来将通用寄存器的值写入控制寄存器; EXRT指令用来从异常恢复。由于特权指令只能在内核模式执行,如果在用户模式执行会引发特权违反异常。
2.9 异常
异常如下表:

中断也与异常一样处理。CPU中发生异常时,先将异常发生处指令的地址写入PC寄存器,再将CPU模式变更到内核模式,最后跳转到异常向量的地址。异常向量是指异常处理程序的起始地址。
3 处理器全局使用的宏
处理器全局使用的宏分为isa.h和cpu.h两个文件。
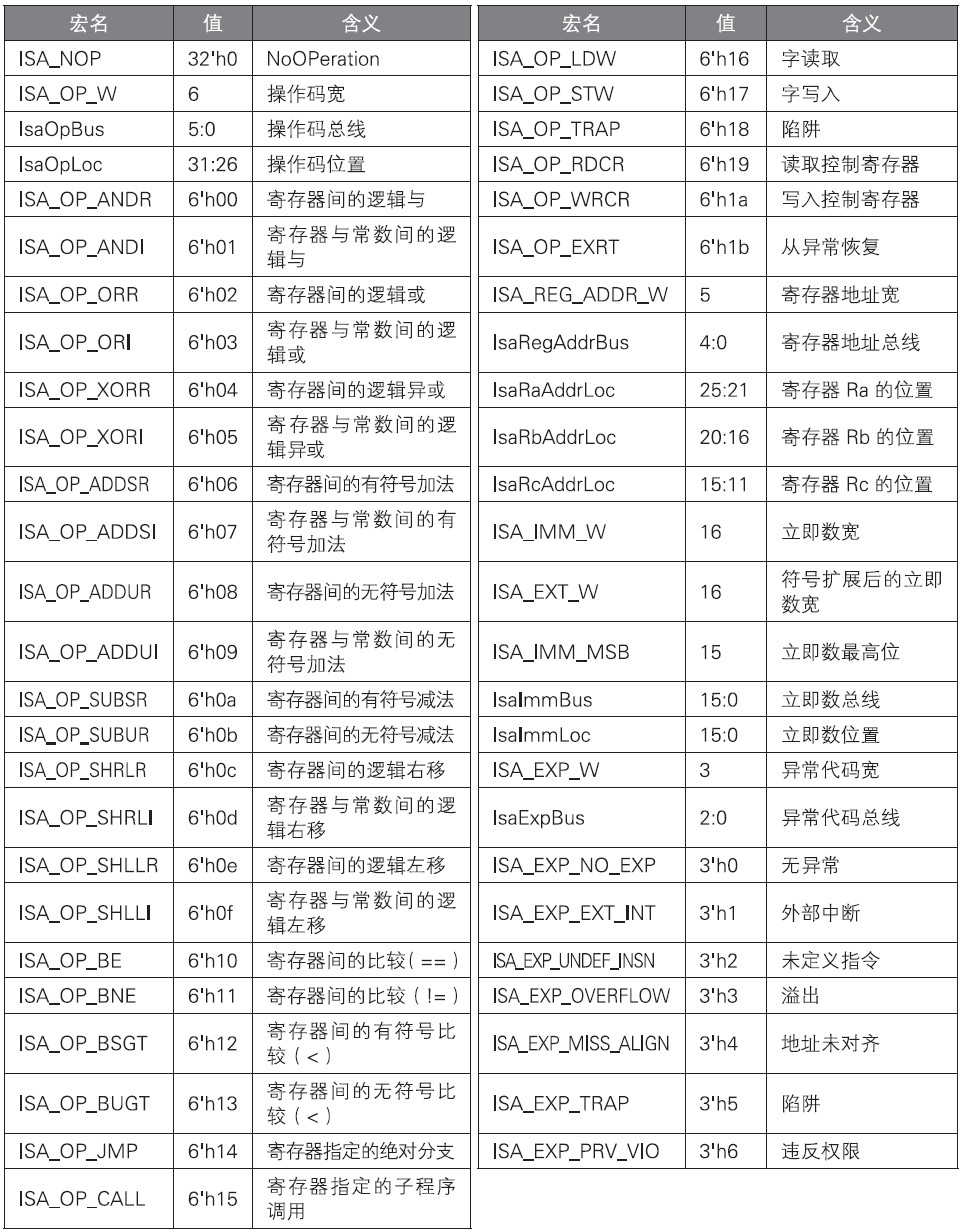
3.1 isa.h
isa.h记载的是与指令集架构有关的宏,内容如下:
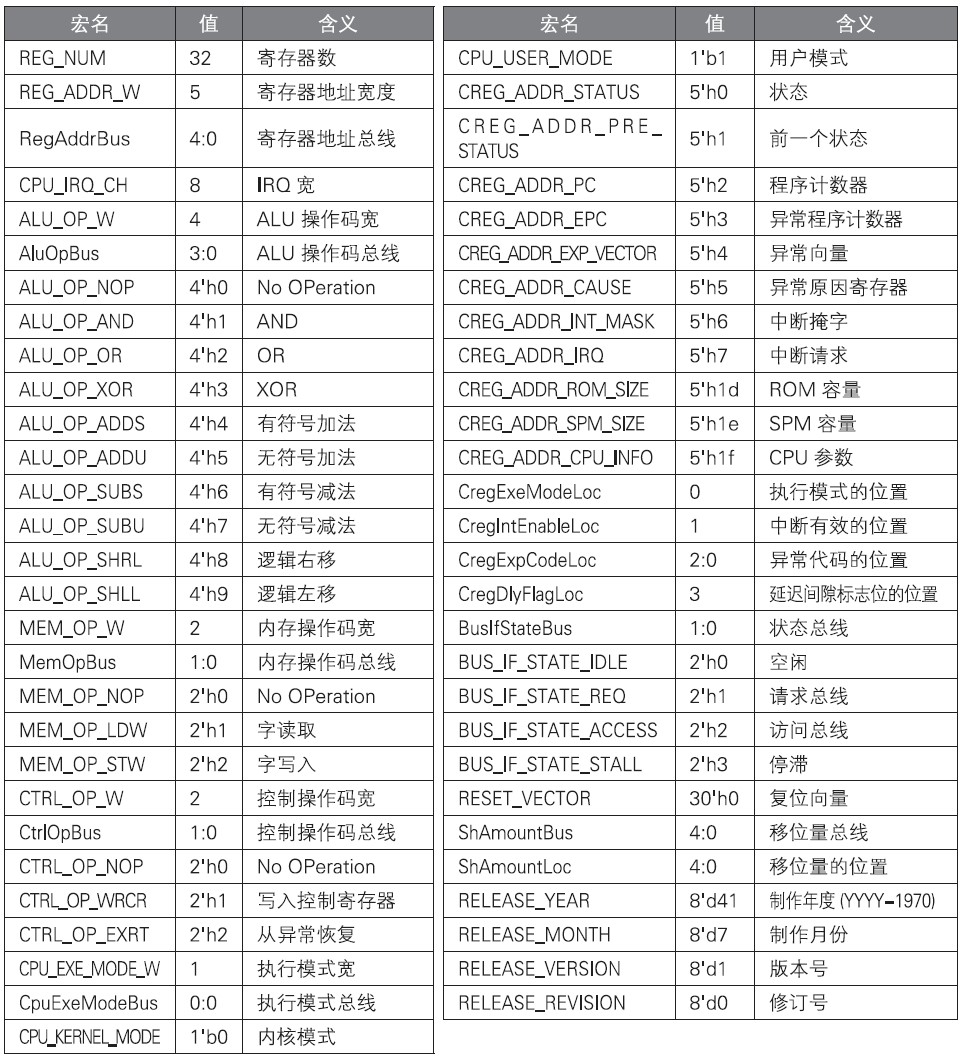
3.2 cpu.h
cpu.h记载的是与微架构有关的宏,内容如下:
4 处理器结构
采用32位RISC架构,使用经典流水线技术制作处理器。处理器框图如下:
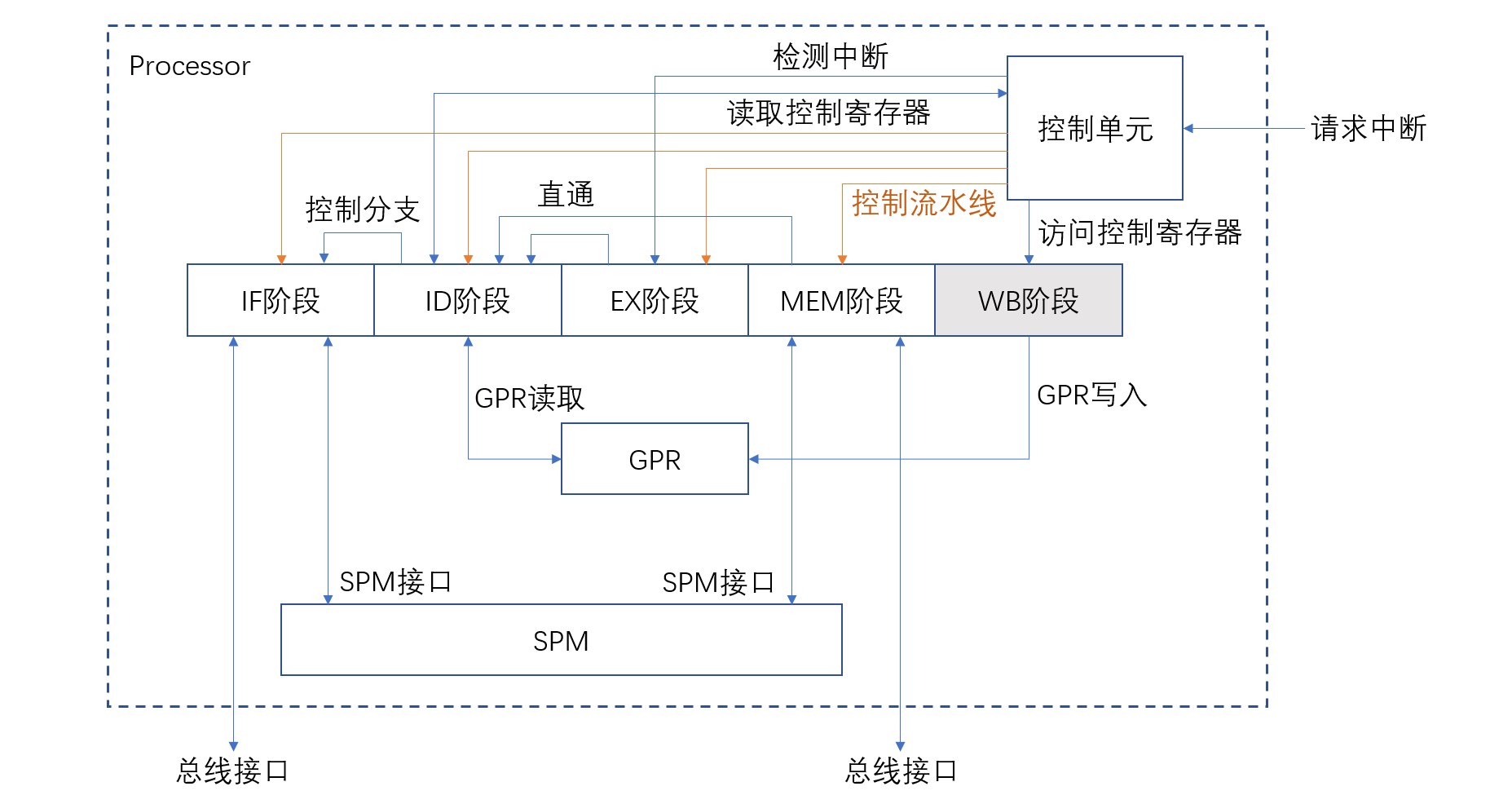
处理器由以下部分组成:流水线中的IF阶段、ID阶段、EX阶段、MEM阶段、CPU中的存储器通用寄存器、控制CPU的CPU控制单元,以及CPU可以直接访问的专用存储器SPM (Scratch Pad Memory),虚线中的wB阶段,实际上在结果写回的通用寄存器或CPU控制单元中实现,这个模块本身并不存在。
IF阶段和MEM阶段通过总线与内存和I/O相连。为了使流水线高效工作,需要每个周期都向流水线提供指令或数据。因此,我们为处理器设置可以高速访问的CPU专用SPM。虽然SPM和其他内存、I/O同样分配有地址间,但CPU可以直接访问而不用通过总线。SPM也有点像缓存,但却是本身分配有地址空间的存储器。
分支的判定在ID阶段进行。我们采用了延迟分支机制,也就是说,分支指令的下一条指令被作为延迟间隙执行,以此规避控制冒险。EX阶段和MEM阶段的处理结果可以直通到ID阶段,以此规避数据冒险。
流水线寄存器的停滞与刷新和流水线的控制等操作由控制单元负责。控制单元还可以接受来自外部的中断请求,并根据CPU的设置输出中断检测信号。中断的检测是在EX阶段进行的。
5 通用寄存器实现
首先制作处理器存储区域的通用寄存器。处理器的指令最大可以指定三个寄存器作为操作数,从其中两个寄存器读取值,然后向另一个寄存器写入值。因此寄存器堆需要有两个读取端口和一个写入端口。
源代码如下:
`timescale 1ns/1ns
/********** 共用头文件 **********/
`include "nettype.h"
`include "global_config.h"
`include "stddef.h"
/********** 单独头文件 **********/
`include "cpu.h"
/********** 模块 **********/
module gpr (
/********** 时钟和复位 **********/
input wire clk, // 时钟
input wire reset, // 异步复位
/********** 读取端口0 **********/
input wire [`RegAddrBus] rd_addr_0, // 读取的地址
output wire [`WordDataBus] rd_data_0, // 读取的数据
/********** 读取端口1 **********/
input wire [`RegAddrBus] rd_addr_1, // 读取的地址
output wire [`WordDataBus] rd_data_1, // 读取的数据
/********** 写入端口 **********/
input wire we_, // 写入有效信号
input wire [`RegAddrBus] wr_addr, // 写入的地址
input wire [`WordDataBus] wr_data // 写入的数据
);
/********** 内部信号 **********/
reg [`WordDataBus] gpr [`REG_NUM-1:0]; // 寄存器序列
integer i; // 初始化用迭代器
/********** 读取访问 (Write After Read) **********/
// 读取端口0
assign rd_data_0 = ((we_ == `ENABLE_) && (wr_addr == rd_addr_0)) ? wr_data : gpr[rd_addr_0]; //如果写地址等于读地址相同,写入数据直接输出
// 读取端口1
assign rd_data_1 = ((we_ == `ENABLE_) && (wr_addr == rd_addr_1)) ? wr_data : gpr[rd_addr_1]; //同上
/********** 写入访问 **********/
always @ (posedge clk or negedge reset) begin
if (!reset) begin
/* 异步复位 */
for (i = 0; i < `REG_NUM; i = i + 1) begin
gpr[i] <= #1 `WORD_DATA_W'h0;
end
end else begin
/* 写入访问 */
if (we_ == `ENABLE_) begin
gpr[wr_addr] <= #1 wr_data;
end
end
end
endmodule
- 读取访问
需要对两个读取端口进行读取访问。如果在读取的同时对相同地址进行写入操作,则直接将写入的数据输出。当写入有效信号(we_)有效,并且写入地址(wr_addr)和读取地址(rd_addr_0和rd_addr_1)一致时,写入的数据(wr_data)输出到输出数据(rd_data_0和rd_data_1)。 - 异步复位
全部寄存器的值初始化为0.使用for语句遍历所有寄存器进行初始化操作。 - 写入访问
当写入有效信号(we_)有效时,向指定的写入地址(wr_addr)写入数据(wr_data)。
6 SPM
SPM(Scratch Pad Memory)是CPU可以不经过总线直接访问的专用内存。SPM设计采用一个spm控制模块和一个双端口RAM的FPGA片上存储资源组成。代码如下:
/********** 通用头文件 **********/
`include "nettype.h"
`include "global_config.h"
`include "stddef.h"
/********** 个别头文件 **********/
`include "spm.h"
/********** 模块 **********/
module spm (
/********** 时钟 **********/
input wire clk, // 时钟
/********** 端口A:IF阶段 **********/
input wire [`SpmAddrBus] if_spm_addr, // 地址
input wire if_spm_as_, // 地址选通
input wire if_spm_rw, // 读/写
input wire [`WordDataBus] if_spm_wr_data, // 写入的数据
output wire [`WordDataBus] if_spm_rd_data, // 读取的数据
/********** 端口B:MEM阶段 **********/
input wire [`SpmAddrBus] mem_spm_addr, // 地址
input wire mem_spm_as_, // 地址选通
input wire mem_spm_rw, // 读/写
input wire [`WordDataBus] mem_spm_wr_data, // 写入的数据
output wire [`WordDataBus] mem_spm_rd_data // 读取的数据
);
/********** 写使能信号 **********/
reg wea; // 端口A
reg web; // 端口B
/********** 产生写使能信号 **********/
always @(*) begin
/* 端口A */
if ((if_spm_as_ == `ENABLE_) && (if_spm_rw == `WRITE)) begin
wea = `MEM_ENABLE; // 写入有效
end else begin
wea = `MEM_DISABLE; // 写入无效
end
/* 端口B */
if ((mem_spm_as_ == `ENABLE_) && (mem_spm_rw == `WRITE)) begin
web = `MEM_ENABLE; // 写入有效
end else begin
web = `MEM_DISABLE; // 写入无效
end
end
/********** Intel FPGA Block RAM : 双口RAM **********/
SPM_RAM SPM_RAM_inst (
/********** 端口A : IF阶段 **********/
.clock_a ( clk ), // 时钟
.address_a ( if_spm_addr ), // 地址
.data_a ( if_spm_wr_data ), // 写入的数据(未连接)
.wren_a ( wea ), // 写入有效(无效)
.q_a ( if_spm_rd_data ), // 读取的数据
/********** 端口B : MEM阶段 **********/
.clock_b ( clk ), // 时钟
.address_b ( mem_spm_addr ), // 地址
.data_b ( mem_spm_wr_data ), // 写入的数据
.wren_b ( web ), // 写入有效
.q_b ( mem_spm_rd_data ) // 读取的数据
);
endmodule
- A端口写入有效信号的生成
当来自IF阶段得到地址有效信号(if_spm_as_)有效、读/写信号(if_spm_rw)为写入(WRITE)时,写入有效信号(wea)为有效。基本上IF阶段只进行指令的读取,因此只有储存器读取操作。 - B端口写入有效信号的生成
当来自MEM阶段得到地址有效信号(mem_spm_as_)有效、读/写信号(mem_spm_rw)为写入(WRITE)时,写入有效信号(wea)为有效。 - 存储器实例化
- 容量:16384;
- 深度:4096;
- 地址宽度:12。
7 总线接口
总线接口用来对总线的访问进行控制。CPU在IF阶段和MEM阶段访问内存。总线接口接受来自CPU的内存访问请求,并控制其对总线的访问。
因为处理器内置了SPM,总线接口要根据访问的地址选择总线和SPM的访问。因为CPU与SPM直接连接,CPU对SPM进行读写只需要一个周期。访问总线时需要遵循总线协议进行访问控制。
在总线空闲状态的前提下,当未在执行刷新流水线操作、地址选通有效以及对1号之外的总线从属进行访问时,可以进行总线访问。当正在执行刷新操作时流水线寄存器无效,无法进行访问。CPU要访问总线时总线接口转移到总线请求状态,对总线控制权进行请求。如果总线许可信号有效,则表明总线控制权申请成功,总线接口转移到总线访问状态进行总线访问。最后,总线访问完成后使能就绪信号。这时,如果流水线在延迟状态,则总线接口转移到延迟状态等待延迟的解除。如果未发生延迟,则返回空闲状态。
总线接口的状态迁移如下图:
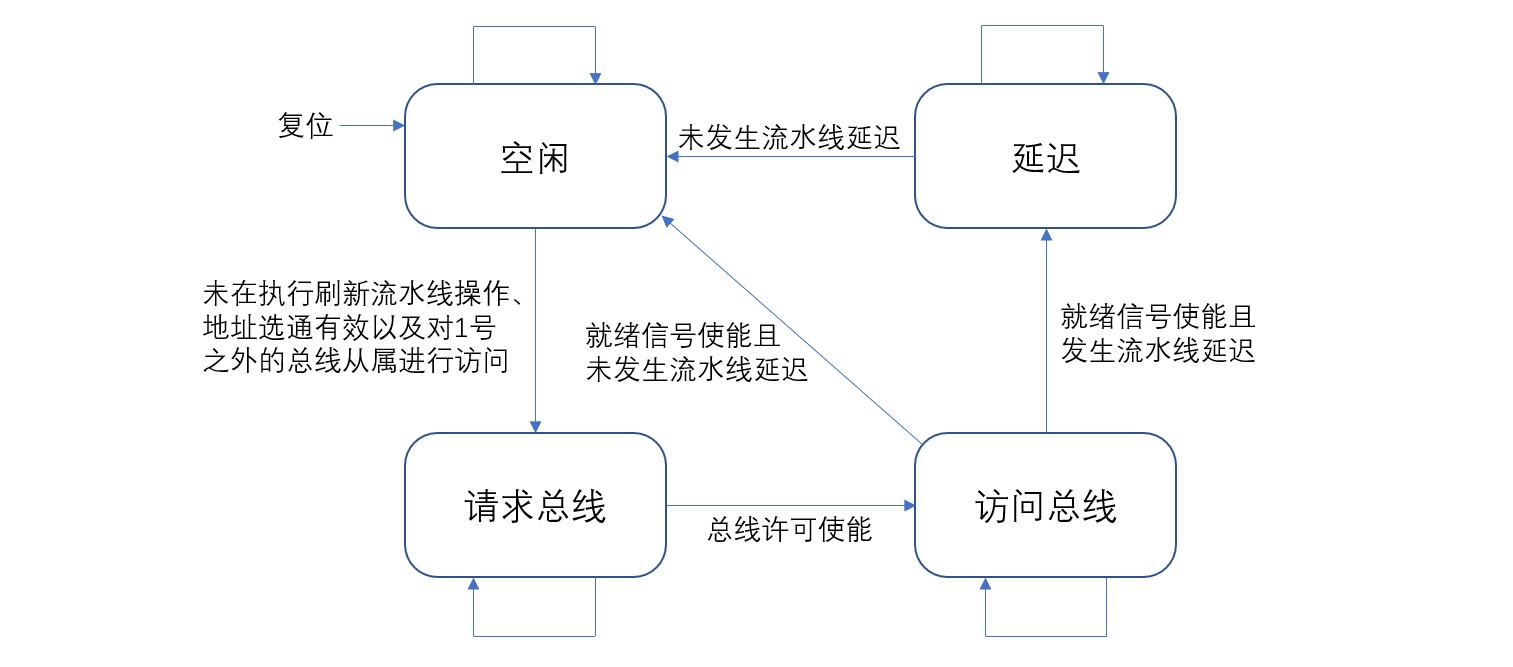
总线接口由两部分组成,一部分是控制内存访问的组合电路,另一部分是控制总线接口状态的时序电路。代码如下:
/********** 通用头文件 **********/
`include "nettype.h"
`include "global_config.h"
`include "stddef.h"
/********** 单个头文件 **********/
`include "cpu.h"
`include "bus.h"
/********** 模块 **********/
module bus_if (
/********** 时钟 & 复位 **********/
input wire clk, // 时钟
input wire reset, // 异步复位
/********** 流水线控制信号 **********/
input wire stall, // 延迟信号
input wire flush, // 刷新信号
output reg busy, // 总线忙信号
/********** CPU接口 **********/
input wire [`WordAddrBus] addr, // 地址
input wire as_, // 地址有效
input wire rw, // 读/写
input wire [`WordDataBus] wr_data, // 写入数据
output reg [`WordDataBus] rd_data, // 读取数据
/********** SPM接口 **********/
input wire [`WordDataBus] spm_rd_data, // 读取数据
output wire [`WordAddrBus] spm_addr, // 地址
output reg spm_as_, // 地址选通
output wire spm_rw, // 读/写
output wire [`WordDataBus] spm_wr_data, // 写入数据
/********** 总线接口 **********/
input wire [`WordDataBus] bus_rd_data, // 读取的数据
input wire bus_rdy_, // 就绪
input wire bus_grnt_, // 许可
output reg bus_req_, // 请求
output reg [`WordAddrBus] bus_addr, // 地址
output reg bus_as_, // 地址选通
output reg bus_rw, // 读/写
output reg [`WordDataBus] bus_wr_data // 写入的数据
);
/********** 内部信号 **********/
reg [`BusIfStateBus] state; // 总线接口状态
reg [`WordDataBus] rd_buf; // 读取缓冲
wire [`BusSlaveIndexBus] s_index; // 总线从属索引
/********** 总线从属索引 **********/
assign s_index = addr[`BusSlaveIndexLoc];
/********** 输出的赋值 **********/
assign spm_addr = addr;
assign spm_rw = rw;
assign spm_wr_data = wr_data;
/********** 内存访问的控制 **********/
always @(*) begin
/* 默认值 */
rd_data = `WORD_DATA_W'h0;
spm_as_ = `DISABLE_;
busy = `DISABLE;
/* 总线接口的状态 */
case (state)
`BUS_IF_STATE_IDLE : begin // 空闲
/* 内存访问 */
if ((flush == `DISABLE) && (as_ == `ENABLE_)) begin
/* 选择访问的目标 */
if (s_index == `BUS_SLAVE_1) begin // 访问SPM
if (stall == `DISABLE) begin // 检测延迟的发生
spm_as_ = `ENABLE_;
if (rw == `READ) begin // 读取访问
rd_data = spm_rd_data;
end
end
end else begin // 访问总线
busy = `ENABLE;
end
end
end
`BUS_IF_STATE_REQ : begin // 请求总线
busy = `ENABLE;
end
`BUS_IF_STATE_ACCESS : begin // 访问总线
/* 等待就绪信号 */
if (bus_rdy_ == `ENABLE_) begin // 就绪信号到达
if (rw == `READ) begin // 读取访问
rd_data = bus_rd_data;
end
end else begin // 就绪信号未达到
busy = `ENABLE;
end
end
`BUS_IF_STATE_STALL : begin // 延迟
if (rw == `READ) begin // 读取访问
rd_data = rd_buf;
end
end
endcase
end
/********** 总线接口的状态控制 **********/
always @(posedge clk or negedge reset) begin
if (!reset) begin
/* 异步复位 */
state <= #1 `BUS_IF_STATE_IDLE;
bus_req_ <= #1 `DISABLE_;
bus_addr <= #1 `WORD_ADDR_W'h0;
bus_as_ <= #1 `DISABLE_;
bus_rw <= #1 `READ;
bus_wr_data <= #1 `WORD_DATA_W'h0;
rd_buf <= #1 `WORD_DATA_W'h0;
end else begin
/* 总线接口的状态 */
case (state)
`BUS_IF_STATE_IDLE : begin // 空闲
/* 内存访问 */
if ((flush == `DISABLE) && (as_ == `ENABLE_)) begin
/* 选择访问目标 */
if (s_index != `BUS_SLAVE_1) begin // 访问总线
state <= #1 `BUS_IF_STATE_REQ;
bus_req_ <= #1 `ENABLE_;
bus_addr <= #1 addr;
bus_rw <= #1 rw;
bus_wr_data <= #1 wr_data;
end
end
end
`BUS_IF_STATE_REQ : begin // 请求总线
/* 等待总线许可 */
if (bus_grnt_ == `ENABLE_) begin // 获得总线使用权
state <= #1 `BUS_IF_STATE_ACCESS;
bus_as_ <= #1 `ENABLE_;
end
end
`BUS_IF_STATE_ACCESS : begin // 访问总线
/* 使地址选通无效 */
bus_as_ <= #1 `DISABLE_;
/* 等待就绪信号 */
if (bus_rdy_ == `ENABLE_) begin // 就绪信号到达
bus_req_ <= #1 `DISABLE_;
bus_addr <= #1 `WORD_ADDR_W'h0;
bus_rw <= #1 `READ;
bus_wr_data <= #1 `WORD_DATA_W'h0;
/* 保存读取到的数据 */
if (bus_rw == `READ) begin // 读取访问
rd_buf <= #1 bus_rd_data;
end
/* 检测是否发生延迟 */
if (stall == `ENABLE) begin // 发生延迟
state <= #1 `BUS_IF_STATE_STALL;
end else begin // 未发生延迟
state <= #1 `BUS_IF_STATE_IDLE;
end
end
end
`BUS_IF_STATE_STALL : begin // 延迟
/* 检测是否发生延迟 */
if (stall == `DISABLE) begin // 解除延迟
state <= #1 `BUS_IF_STATE_IDLE;
end
end
endcase
end
end
endmodule
- 生成总线从属索引 使用PC寄存器
告辞。