{kind=link}
Design Compiler入门
26 Jan 2020 9326字 32分 次 Digital IC Design Synthesis打赏作者 CC BY 4.0 (除特别声明或转载文章外)
1 前言
只找到了Design Compiler 2016,凑合用吧。如果之前破解过Synopsys的其他EDA的话,破解这个是很方便的,就是换成Linux环境而已。 支持正版!
- 开发环境:
- Design Compiler 2016
- 操作系统:
- Ubuntu 18.04 LTS
2 综合概述
但凡玩过FPGA都知道综合是干啥。Design Compiler(以下简称DC)是Synopsys公司用于做电路综合的核心工具,可以将HDL描述的电路转换为基于工艺库的门级网表。
逻辑综合分为三个阶段:
- 转译(Translation):把电路转换为EDA内部数据库,这个数据库跟工艺库是独立无关的;
- 优化(Optimozation):根据工作频率、面积、功耗来对电路优化,来推断出满足设计指标要求的门级网表;
- 映射(Mapping):将门级网表映射到晶圆厂给定的工艺库上,最终形成该工艺库对应的门级网表。
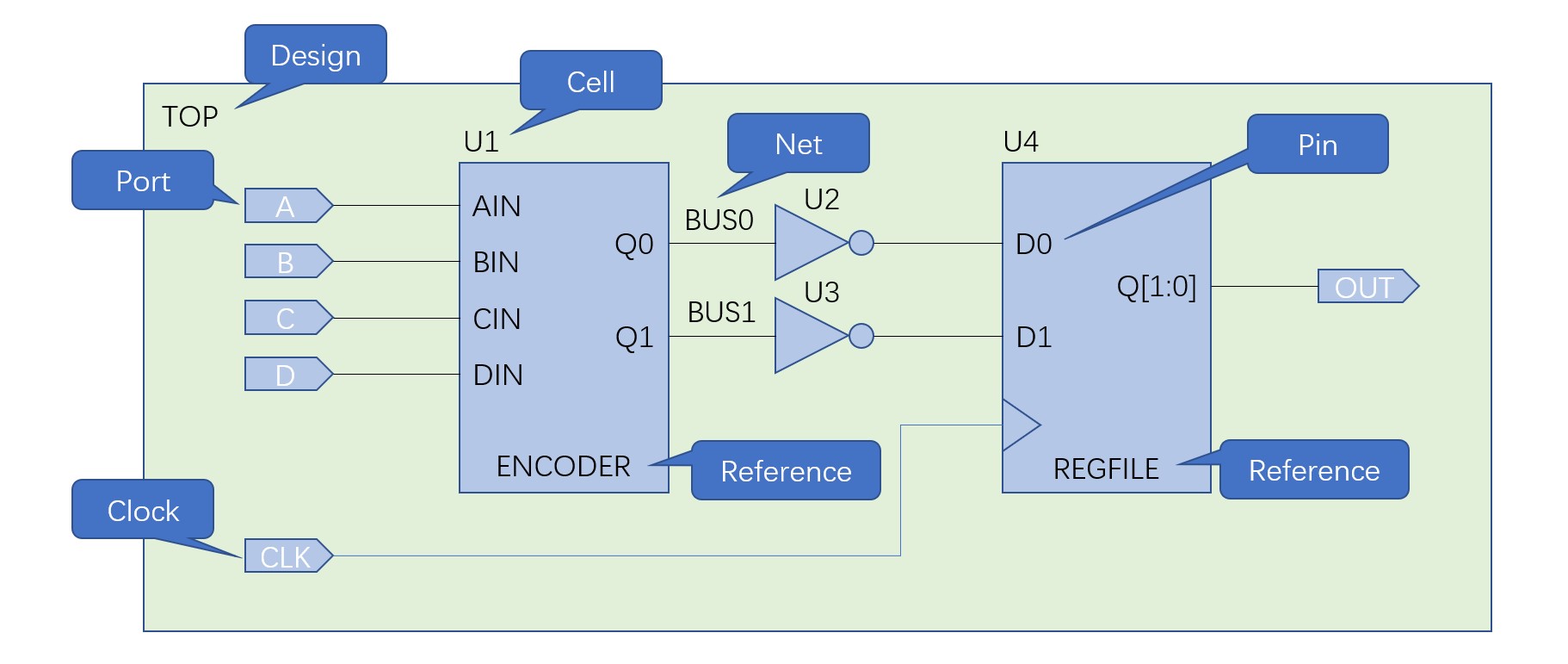
DC在综合过程中会把电路划分为以下处理对象:
- Design:待综合的对象(module);
- Port:Design最外部的端口;
- Clock:时钟;
- Cell:被例化的模块;
- Reference:例化的原电路。
举例说明:
使用DC综合的流程如下图所示:
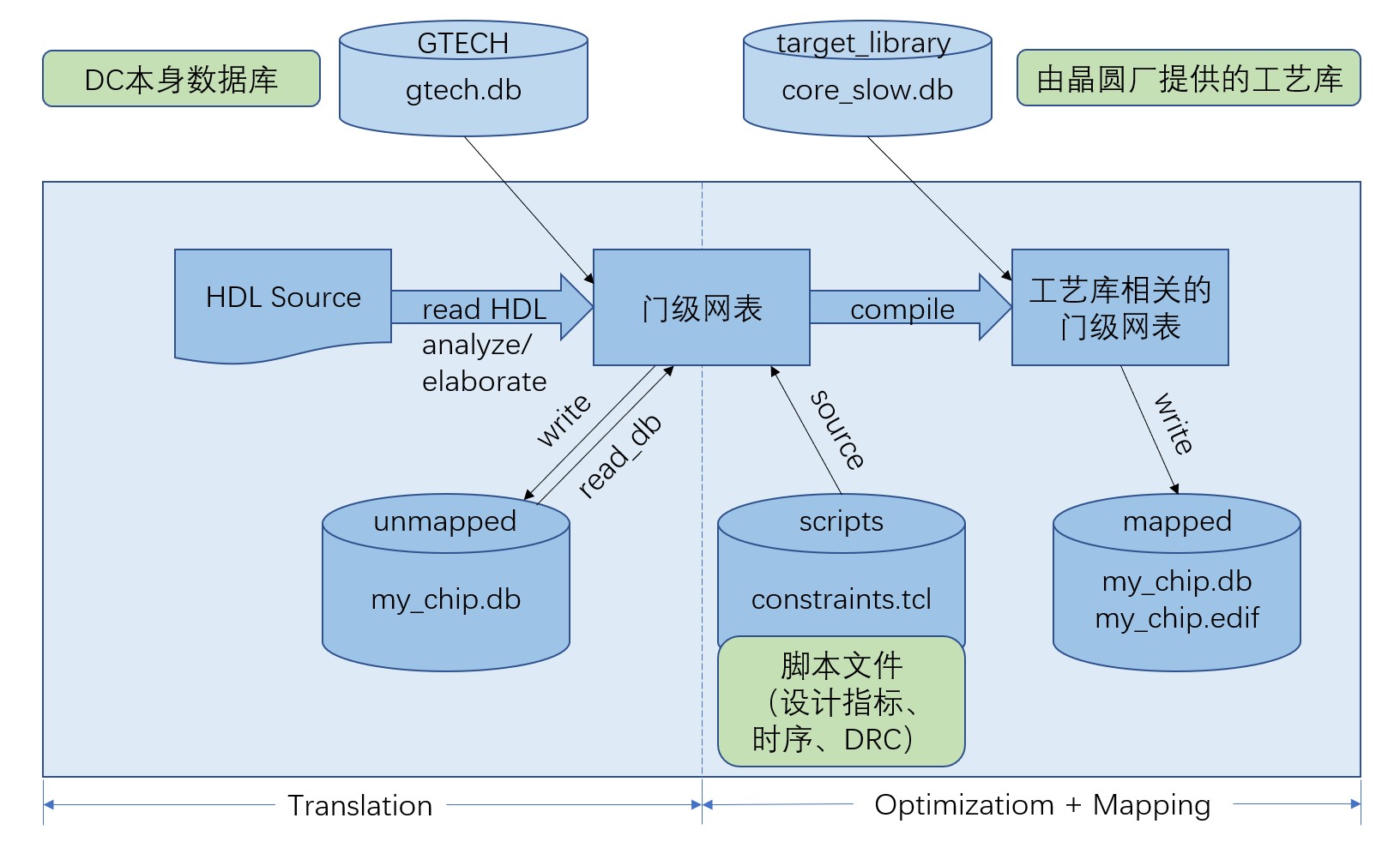
使用DC逻辑综合的流程大致可以分为以下几个部分:
- 预综合过程(Pre-Synthesis Processes):在综合过程之前的一些为综合做准备的步骤:
- DC启动;
- 设置各种库文件:
- link_library;
- target_library;
- symbol_library;
- 创建启动脚本文件;
- 读入设计文件;
- analyze;
- elaborate;
- read_file;
- DC中的设计对象;
- 各种模块划分;
- Verilog的编码。
- 施加设计约束:
- 设置环境约束:
- set_operating_coditions;
- set_wire_load;
- set_drive;
- set_driving_cell;
- set_load;
- set_fanout_load;
- 设置时序约束:
- 设计规则的约束:
- set_max_transition;
- set_max_fanout;
- set_max_capacitance;
- 优化的约束:
- create_clock;
- set_clock_skew;
- set_input_delay;
- set_output_delay;
- set_max_area;
- 设计规则的约束:
- 设置环境约束:
- 设计综合;
- 后综合。
3 Design Compiler的使用
3.1 启动Design Compiler
可以通过四种方式启动Design Compiler:
- dc_shell命令行;
- dc_shell_t命令行:
- 以tcl为基础;
- 在该脚本语言上扩展了实现DC的命令;
- 用户可以在shell提示符下输入指令“dc_shell_t”来运行;
- 也可以在启动dc_shell_t时直接调用tcl脚本“dc_shell_t -f script”来执行。
推荐
- design_analyzer图形方式(基于dc_shell命令行);
- design_vision图形方式:
- 与tcl对应的图形方式,用户可以在shell提示符下输入“design_vision”来运行。
DC在启动时会自动在启动目录下创建“command.log”和“view_command.log”两个文件,用于记录用户在使用DC时所执行的命令及设置的参数。还会创建“filenames.log”,用于记录DC访问过的目录,包括库、源文件等,退出DC时会被自动删除。
启动dc_shell只产生“command.log”日志文件。
3.2 读入设计文件
有两种读入方式:
- 使用read指令来读入;
- 同时使用analyze和elaborate指令。
DC的read指令支持多种硬件描述格式,不同模式下读取不同格式文件有以下区别:
- dc_shell工作模式:读取不同的文件格式只需要带上不同的参数:
read -format verilog[db、vhdl etc.] file - tcl工作模式:读取不同的文件格式需要使用不同的命令:
read_db file.db read_verilog file.v read_vhdl file.vhd
同时使用analyze和elaborate指令:
- analyze:分析HDL的源程序并将分析产生的中间文件存于work(或用户指定)的目录下;
analyze -format sverilog {a.sv b.sv chip_top.sv} - elaborate:在产生的中间文件中生成verilog的模块或VHDL的实体,缺省状态下读取的是work目录中的文件。
elaborate chip_top
analyze&elaborate允许设计者在设计的GTECH建立之前,首先分析设计的语法错误和进行HDL代码转换。analyze做语法检查,产生“.syn”文件存储在work路径下的定义设计库内,可供elaborate使用,不必重复分析;read不行。
analyze&elaborate之后没必要设置顶层文件,也没必要进行link操作。
另外只有elaborate可以设定顶层文件的parameter:
elaborate chip_top -parameter "DATA_WIDTH = 8,ADDR_WIDTH = 8"
3.3 连接
读取完所要综合的模块之后,需要用link命令将读到DC存储区中的模块或实体连接起来。在“.synopsys_dc.setup”文件中添加link_library,告诉DC到哪去找这些模块,同时还要注意search_path中的路径是否指向该模块或单元电路所在的目录。
4 标准单元工艺库
4.1 常见库文件
Design Compiler运行中要用的几种库文件:
- 目标库(target_library)(标准单元)(db格式);
- 链接库(link_library)(购买的付费IP、存储器、IO、PAD)(db,ddc格式);
- 符号库(symbol_library)(sdb);
- 算术运算库(synthetic_library)(synopsys自带的库)。
4.2 目标库
目标库是综合后电路网表要最终映射到的库。
读入的HDL代码首先由Synopsys自带的GTECH库转成DC内部交换的格式,然后经过映射到目标库,最后生成优化的门级网表。
目标库一般是db格式,由lib格式转化而来。lib库具有可读性,db库是给工具读的。
目标库包含了各个门级单元的行为、引脚、面积、时序信息等,有的还包含了功耗方面的参数。
DC在综合时就是根据目标库中给出的单元路径的延迟信息来计算路径的延时,并根据各个单元的延时、面积和驱动能力的不同选择合适的单元来优化电路。
4.3 链接库
链接库是设置模块或单元电路的引用。
对于所有DC可能用到的库,我们都需要在link_library中指定,也包括要用到的IP。
在link_library的设置中必须包含“*”,表示DC在引用实例化模块或者单元电路时首先搜索已经调进DC memory的模块和单元电路。
4.4 符号库
符号库是定义了单元电路显示的原理图库。
查看分析电路图时,需要设置sdb格式的符号库。
4.5 算术运算库
在初始化DC时,不需要设置标准的DesignWare库standard.sldb用于实现verilog描述的运算符,DC会把加法、乘法等运算综合成性能较差的电路。
如果需要扩展DesignWare,需要在synthetic_library中设置,同时需要在link_library中设置相应的库以使得在链接的时候FC可以搜索到相应运算符的实现。
需要高级的lisence。
4.6 工艺库:单元时序信息
单元时序模型旨在为设计环境中的单元的各种实例提供精确的时序。
标准单元时序模型分为两种:
- 线性模型:
- 简单的时序模型是线性延迟模型,其中单元的延迟和输出转换时间表示为两个参数的线性函数:输入转换时间和输出负载电容;
- 线性延迟模型在亚微米技术的输入转换时间和输出电容范围内不准确。
- 非线性模型:
- 延迟的非线性时序模型以二维形式呈现;
- 实际分析中常用非线性模型。
也可以分为组合逻辑单元和时序逻辑单元的内部时序模型。
5 DC施加时序约束
5.1 面积约束
定义面积:
de_shell-t> current_design PRGRM_CNT_TOP
dc_shell-t> set_max_area 100
上例中的100有三种定义:
- 两输入与非门个数;
- 晶体管个数;
- 平方微米。
5.2 时序约束
时序路径(Timing Path)可分为以下四类:
- 输入到寄存器的路径;
- 寄存器到寄存器之间的路径;
- 寄存器到输出的路径;
- 输入直接到输出全組合邏輯的路径。
时序路径(Timing Path)的起點和终点:
- 起点:
- Input Port;
- Clock pin of Flip-Flop or register;
- 終點:
- Output Port;
- No clock pin of Flip-Flop or register。
定义时钟:
- 用户必须定义的值:
- clock source;
- clock period;
- 用户可能定义的值:
- duty cycle;
- offset/skew;
- clock name;
例如:
dc_shell-t> create_clock -period 10 [get_port clk]
dc_shell-t> set_dont_touch_network [get_port clk] //对所有定义的时钟网络设置为dont_touch,
//既综合的时候不对clk信号优化
//因为实际电路设计中时钟数综合有自己特别的方法,
//需要考虑实际布线后的物理信息。
定义输入延迟,例如:
dc_shell-t> set_input_delay -max 4 -clock clk [get_port A]
//设置A端输入口满足建立时间的最大延迟为4
定义输入延迟,例如:、
dc_shell-t> set_output_delay -max 5.4 -clock clk [get_port B]
//设置B端输出口满足建立时间的最大延迟为4
具体指令可以查看我之前总结的文章:时序约束之时钟
5.3 DRC约束
常用的DRC约束有以下三种:
- set_max_transition:约束design中的信号、端口、net最大transition不能超过这个值,值越小越苛刻;那天的transition time取决于net的负载(fanout),负载越大,transition time越大;
- set_max_fanout:对design、net、output port进行操作,设定的不是具体的电容值。扇出负载值是用来表示单元输入引脚相对负载的数目,它并不表示真正的电容负载,而是个无量纲的数字;
- set_max_capacitance:基于工艺库的信息设定最大电容。
这三个约束由工艺厂商提供,但我们可以约束的更紧一些。
第一条和第三条在数字IC设计中必须约束,否则无法流片。
6 DC施加环境约束
如果当外界温度变换,或者供电电压发生变换,延时也会相应的改变。所以需要对电路施加环境约束。
6.1 设置操作条件
在工作库中提供了几种工作条件的模型以供选择:
- 最好情况(best case):用于基于保持时间的时序分析;
- 典型情况(typical case):一般不考虑;
- 最坏情况(worst case):用于基于建立时间的时序分析。
6.2 驱动强度
为了精确计算输入电路的时序,DC需要知道input port的transition 时间,“set_driving_cell”允许用户可以自定义一个实际的外部驱动cell。
6.3 线载模型
在DC综合的过程中,连线延时是通过设置连线负载模型(wire load model)确定的。连线负载模型基于连线的扇出,估计它的电阻电容等寄生参数,它也是由晶圆厂提供的。晶圆厂根据这个工艺流片的芯片的连线延时进行统计,从而得到这个值。
设置输入驱动是通过“set_wire_load_model”命令完成,例如:
dc_shell-t> set current_design addtwo
dc_shell-t> set_wire_load_model -name 160KGATES
也可以让DC自动根据综合出来的模块的大小选择负载模型,这个选项在默认下是打开的。
以上是模块内部的连线负载模型。模块间的连线负载模型需要选择连线负载模式(set_wire_load_mode),有以下三种:
- 围绕(enclosed):连接两个模块的连线的负载模型用围绕它们的模块的负载模型代替,即用SUB的负载模型;
- 顶层(top):用顶层模块的负载模型代替;
- 分段(segment):分别根据穿过的三段的模型相加得到。
例如:
dc_shell-t> set_wire_load_mode enclosed
6.4 load
为了更准确的入籍模块输出的时序,除了要知道输出延时之外,还需要知道输出所接电路的负载情况。如果输出负载过大会加大电路的transition time,影响时序特性。如果DC默认输出负载为0,即相当于不接负载的情况,这样综合出来的电路时序显然过于乐观,不能反映实际工作情况。
使用set_load设定load值,例如:
set_load [load_of my_lib/and2a0/A] [get_ports OUT1]
set_load [expr [load_of my_lib/inv1a0/A]*3] OUT1
6.5 判断环境约束是否施加成功
在定义完环境属性之后,我们可以使用下面的命令检查约束是否施加成功:
- check_time:检查设计是否有路径没有加入约束;
- check_design:檢查设计中是否有悬空脚或输出短接的情况;
- write_script:将施加的约束和属性写出到一个文件夹中,可以检查这个文件看看是否正确。
7 综合结果输出
综合后的结果包括:
- 整个工程以ddc格式保存下来以供后续查看和修改;ddc文件里包含了sdf时序信息和sdc约束信息,ddc约等于网表+sdc约束;
- 网表netlist,用于布局布线和仿真;
- sdf文件,标注了用到的标准单元的延迟值,后仿真也需要用到;
- 面积报告,包含时序电路、组合电路和总电路面积;
- 约束报告,给出了综合过程中哪些,没有满足要求;
- 时序报告,包含建立时间和保持时间。
8 综合中优化电路的常用方法
DC进行优化的目的是权衡timing和area约束,以满足用户对功能、速度和面积的要求。
优化过程是基于用户为design所加载的约束:
- design rule constraint:
优先- transition;
- fanout;
- capacitance;
- optimiza constraint:
- delay;
- area。
8.1 creating path groups
默认情况下,DC根据不同的时钟划分path group。但是如果设计存在复杂的时钟、复杂的时序要求或者复杂的时序,用户可以将关心的几条路径划分为一个path group,指定DC专注于该组路径的优化。
也可以对不同的组设置不同的权重,权重的值范围为0.0-100.0。例如:
dc_shell> group_path -name group3 -from in3 -to FF1/D -weight 2.5
8.2 optimizing near-critical paths
默认情况下,DC只优化关键路径,即负slack最差的路径。如果在关键路径附近指定一个范围,那么DC就会优化指定范围之内的所有路径。若指定范围较大,会增大DC运行时间,因此一般情况该范围设定为时钟周期的10%。例如:
dc_shell-t> set_critical_range 3.0 $current_design
8.3 performing high-effort compile
High-effort compile能够使DC更加努力的达到所约束的目标,该措施在关键路径上进行重新综合,同时对关键路径周围的逻辑进行了restructure和remap。
High-effort指令有两种:
- compile_ultra,附带两个option:
- -area_high_effort_script:面积优化;
- -timing_high_effort_script:时序优化;
- compile,附带一个option:
- map_effort -high。
High-effort对关键路径的重新优化包括:逻辑复制和映射为大扇入的门单元。
8.4 performing a high-effort incremental compile
通常使用incremental可以提高电路优化的性能。如果电路在compile之后不满足约束,通过incremental也许能达到要求的结果。
Incremental只进行门级的优化,而不是逻辑功能级的优化。他的优化结果可能是电路的性能和之前一样或更好。
Incremental会导致大量的计算时间,但是对于将最差的slack减为0,这是最有效的方法。为了减少DC运算时间,可将那些已经满足时序要求的模块设置为dont_touch属性:
dc_shell> dont_touch noncritical_blocks
对于那些有很多违例逻辑模块的设计,通常incremental最有效:
dc_shell> compile -map_effort high -incremental_mapping
8.5 gate-level optimizations
门级优化主要通过选择库中合适的标准单元来对电路进行优化,它分为三个阶段:
- delay optimization:
- DC对电路进行局部调整;
- DC已经开始考虑DRC,同样条件下,会选择DRC代价最小的方案;
- design rule fixing:
- DC主要通过插入buffer,调整单元的大小等措施来满足各种DRC约束;
- 一般不会影响时序和面积结果,但是会引起optimiza consrtaints违例;
- area recovery:
- 不会引起DRC和delay的违例,一般只是对非关键路径进行优化;
- 如果没有设置面积约束,那么优化的幅度会很小。
8.6 automatic ungrouping
Ungrouping取消设计中的层次,移除层次的边界,并且允许DC ultra通过减少逻辑级数改进时序,以及通过共享资源减少面积。实现该功能有两条指令:
- compile_ultra:
需要单独的license- delay-based auto-ungrouping:
- 默认情况下,compile_ultra执行该种策略,它主要是围绕关键路径进行一些优化;
- 在该情况下,DesignWare中的结构是不会被优化,因为DC认为他们已经被优化的非常好,在时序和面积上都没有可以再优化的可能;
- area-based auto-ungrouping:
- mapping之前运行;
- DC会估算unmapped的层次,然后移除一些小的子设计;
- 目的是降低面积和提升时序性能;
- delay-based auto-ungrouping:
- compile -auto_ungroup:
- compile -auto_ungroup area:
- 相当于area-based auto-ungrouping。
- compile -auto_ungroup area:
8.7 adaptive retiming
在逻辑综合过程中,发现设计的流水线划分不平衡,就可以使用retiming策略。可在时序路径上前后移动寄存器,以提高电路的时序性能。
Retiming在优化过程中,如果有违例的路径,则调整寄存器的位置。如果没有违例的路径,则可用来减少寄存器的数量。
DC在移动寄存器的优化中,只有对有相同时序约束的寄存器进行调整,如果两个寄存器约束不同,则不能一起移动。
移动后的寄存器在网表中,名字通常带有一个R的前缀,和一个系列号,如:
R_xxx
且retime策略不能和compile_ultra的以下option一起使用:
- -incremental;
- -top;
- -only_design_rule。
除此之外其他option都可以同时使用。
8.8 high-level optimization and datapath optimization
DC对数据通路的优化,主要通过以下手段:
- 采用树形结构的运算逻辑,比如:a+b+c+d,优化为(a+b)+(c+d);
- 逻辑上的简化,比如:(a*3*5)简化为(a*15);
- 资源共享。
DC ultra对数据的优化主要通过以下手段:
- 使用Design Ware库;
- 数据路径提取:使用多个树形阵列的CSA的加法器代替数据通路中的加法运算,可大大提高电路的运算速度。但是,这只适合多个运算单元之间没有任何逻辑。同时,Design Ware中的单元不能被提取。
- 对加乘进行重新分配,比如:(a*c+b*c)优化为(a+b)*c;
- 比较器共享,比如a>b,a<b,a≤b会调用同一个减法器;
- 优化并行的常数相乘;
- 操作数重排。
8.9 verifying function equivalence
以下优化均会引起网表和RTL Design不一致,因此需要使用formality工具进行一致性检查,确认不一致的地方是否由DC优化造成:
- 由ungroup、group、uniquify、rename_design等造成部分寄存器、端口名字改变;
- 等效和相反的寄存器被优化,常量寄存器被优化;
- Retiming策略引起的寄存器,电路结构不一致;
- 数据通路优化引起的不一致;
- 状态机的优化。
因此,DC在综合过程中必须生成formality的setup文件(默认为default.svf)。
8.10 partitioning for synthesis
把一个设计分割成几个相对简单的部分,称为设计划分(Design Partition)。再平常的电路设计中这是一种普遍使用的方法,一般在编写HDL代码之前都需要对所要描述的系统做一个系统划分,根据功能或者其他的原则将一个系统层次化的分成若干个子模块,这些子模块下面再进一步细分。这是一种设计划分,模块(module)就是一个划分的单位。
在运用DC作逻辑综合的过程中,默认情况下各个模块的层次关系是保留着的,保留着的层次关系会对DC综合造成一定的影响。比如在优化的过程中,各个子模块的管脚必须保留,这势必影响到子模块边界的优化效果。
设计划分原则:
- 不要让一个组合电路穿越过多的模块;
- 输出用寄存器;
- 根据综合时间长短控制模块大小;
- 将同步逻辑部分与其他部分分离。
告辞