
1 前言
什么是神经网络(Neural Network)?简单来说,人工神经网络(Artificial Neural Network, ANN)是一种模仿生物神经系统结构和功能的计算模型。它的基本计算单元是“神经元”,每个神经元接收来自上一层的输入,经过加权求和与非线性激活后得到输出。其核心计算公式可以表示为:
\[y = f(\sum_{i=1}^{n} w_i x_i + b)\]其中 $x_i$ 是输入特征,$w_i$ 是对应的权重(Weight),$b$ 是偏置(Bias),$f$ 是激活函数(Activation Function)。
最基本神经网络由三类层构成:
- 输入层
- 隐藏层(一层或多层)
- 输出层
当网络中包含至少一层“隐藏层”时,通常就进入了多层神经网络的范畴;没有隐藏层的感知机或逻辑回归也可以看作更简单的神经网络模型。
深度神经网络(Deep Neural Network, DNN)就是层数很深的神经网络,本质一样,就是隐藏层更多。一般约定:
- 1个隐藏层:浅层神经网络
- 2层以上隐藏层:深度神经网络
深度不是“为了多而多”,而是带来表示能力的飞跃。以图像为例:
| 层级 | 学到的东西 |
|---|---|
| 浅层 | 边缘、直线 |
| 中层 | 角、纹理 |
| 深层 | 物体部件 |
| 最深层 | 整体语义(猫、人脸) |
深度越深,能力越强:
- 数学角度:多层非线性函数≈更复杂的函数族
- 工程角度:可以把复杂问题拆为多步简单变换,每一层做“稍微抽象一点”的处理
常见深度神经网络家族:
- CNN(卷积神经网络)
- 图像、视频
- RNN/LSTM/GRU
- 时间序列、语音
- Transformer
- NLP/多模态
- MLP(多层全连接)
- 最基础的DNN
作为一名 IC/FPGA 工程师,我们习惯了用与非门、触发器和状态机来构建数字世界。当面对 AI 这个充满“概率”和“黑盒”色彩的领域时,最有效的方法就是从硬件底层重构神经网络。本文最终落地的是一个全连接 MLP 手写数字识别器,卷积部分用于建立硬件直觉;后文将拆解神经元的核心组件,探讨如何将数学上的参数转化为电路中的实存逻辑。
2 训练与推理
在深入细节前,必须厘清“训练”与“推理”在网络结构上的异同。
- 结构上的对称性:从宏观拓扑上看,训练和推理使用相同的网络框架(如层数、每层神经元数量等)。
- 计算路径的区别:
- 训练 (Training):是一个双向过程。除了前向计算,还需要一套极其复杂的“反向传播”路径来计算梯度(误差),并不断修正参数。
- 推理 (Inference):是一个纯粹的单向前向过程。
- 本文重点:FPGA 加速器的核心是实现高性能的推理引擎。因此,本文及后续实战将仅聚焦于推理(Forward Pass)部分,即如何让固定的参数在硬件上飞快运行。
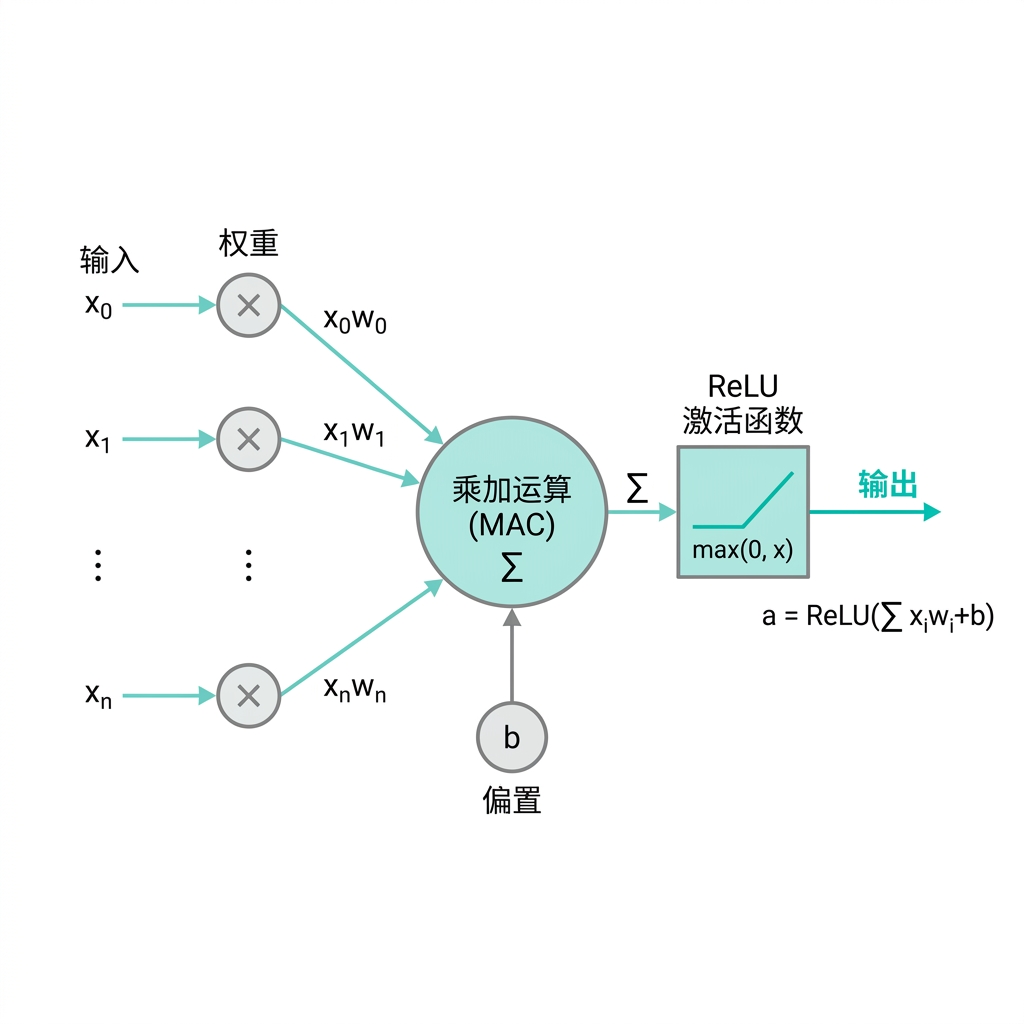
3 神经元结构
在硬件工程师眼里,神经元是一个级联的逻辑流水线。它由输入端$x_i$、权重存储$w_i$、乘加运算阵列、偏置接入点$b$和非线性转换器$ReLU$组成。
3.1 权重 (Weights)
- 数值来源:权重不是我们手动计算的,而是“训练”阶段产生的。它们是电脑通过海量数据迭代学到的最优系数文件。
- 连接细节:这是理解网络规模的关键——每一级神经元的每一个多比特输入,都拥有一个唯一且对应的权重值。
- 存储压力:在 FPGA 中,这些权重通常以定点数形式存放在 BRAM 或片外 Flash 中。
- 注:训练产生的原始权重通常是 32 位浮点数(Float32),但为了硬件效率,我们会在后续步骤中通过“量化”将其转换为 8 位或 16 位定点数。
3.2 计算单元 (Computing Unit)
- 计算公式:神经元的核心计算逻辑可以拆成两步:先计算线性部分 $z = \sum_{i=1}^{n} (x_i \cdot w_i) + b$,再通过激活函数得到 $y = f(z)$。
- FPGA 实现:
- DSP Slices:利用 FPGA 内部专用的 DSP 资源(如 Xilinx 的 DSP48)来实现高效的乘法运算。
- 加法树/累加器:将多个乘法结果通过逐级加法器或时间上的累加器合并。对于扇入(Fan-in)巨大的情况,通常采用分时复用技术来节省硬件面积。
- 硬件权衡(并行与串行):
- 高并行(追求速度):为每个乘法都分配一个硬件乘法器。优点是吞吐量极高,缺点是资源消耗巨大。
- 时间复用(节省面积):用少量的计算单元,通过高频时钟循环处理所有输入。这是 FPGA 设计中最核心的权衡艺术。
3.3 偏置 (Bias)
- 数值来源:与权重一样,偏置值也是由训练过程确定的。
- 接入位置:偏置值被加在所有乘积之和($\sum_{i=1}^{n} (x_i \cdot w_i)$)之后,但在送入激活函数处理之前。
- 物理内涵:它相当于给计算结果增加了一个可调的“直流分量”,用于修正判定阈值。在硬件设计中,它通常作为加法累加器的初始值输入。
3.4 激活函数 (Activation Function)
- 作用:引入非线性,决定神经元是否“兴奋”。
- 硬件实现 (以 ReLU 为例):
- 实现细节:实时监控累加结果的最高位(MSB)。若 $MSB=1$(代表负数),通过一个 Mux 或与门强行将输出置 0;若 $MSB=0$,则原样透传。
- 硬件优势:相比于 Sigmoid 或 Tanh 等涉及指数和除法的激活函数(在 FPGA 中需要极其昂贵的查找表或 CORDIC 算法),ReLU 是一种近乎零成本的非线性变换。
4 网络的结构
神经元通过不同的连接拓扑,形成了处理数据的流水线。目前主流的有全连接和卷积两种模式。
4.1 全连接网络 (Fully Connected Network)
全连接是神经网络中最直观的结构,即上一层的所有输出信号全部连接到下一层每一个神经元的输入端。
- 优点:结构简单,逻辑直观,具备“全局视野”,能捕捉图片中跨度较大的特征关系。
- 缺点:参数量爆炸。对于 28x28 的图像,若第一层有 512 个神经元,则需存储约 40 万个权重。这会产生极高的存储成本和带宽压力。
- 使用场景:通常用于网络的最后几层,负责将提取出的抽象特征汇总,输出最终的分类决策。
- 硬件瓶颈(带宽):对于 IC 工程师来说,FC 层最大的挑战在于计算与带宽的匹配。例如,计算一个具有 784 个输入的神经元需要读取 784 个权重。如果硬件每周期只能从 BRAM 读出一个权重,那么计算一个神经元就需要 784 个时钟周期。这种“存储受限”的特性决定了 FC 层的吞吐量上限。
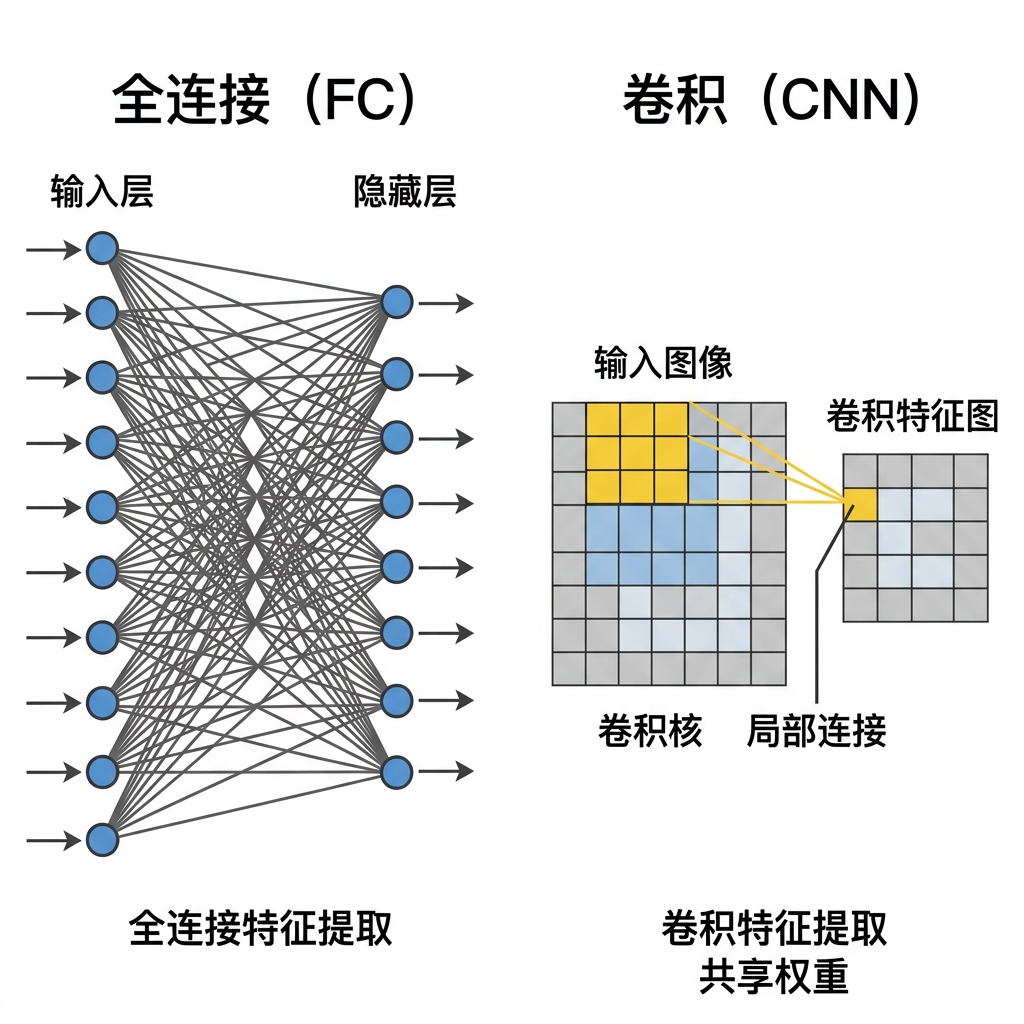
这里做了一个全连接神经网络动画演示的页面,能够在一个3x3的网格上画线,画上的区域为1,其余为0,然后把这9个格子作为神经网络第一层,第二层做计算,第三层为输出层。通过动画一步一步演示三层全连接的神经网络是如何识别横竖斜线。
4.2 卷积网络 (Convolutional Network)
卷积的物理本质是滑动窗口滤波器。它不再一次性看整张图,而是拿着一个“放大镜”(卷积核)在图上逐像素扫描。
4.2.1 深度理解卷积:一个 1 维数组的特征提取实例
为了理解卷积是如何“提取特征”的,我们假设有一段 1 维的图像信号,其中包含一个突发的白点(高亮度 255):
- 输入信号 (X):
[0, 0, 255, 0, 0] - 卷积核 (K):
[-1, 2, -1](这是一个经典的边缘/特征检测算子) 我们开始“滑动”计算:- 窗口对准
[0, 0, 255]: 计算:$(-1 \times 0) + (2 \times 0) + (-1 \times 255) = \mathbf{-255}$ - 窗口右移,对准
[0, 255, 0]: 计算:$(-1 \times 0) + (2 \times 255) + (-1 \times 0) = \mathbf{510}$ - 窗口再右移,对准
[255, 0, 0]: 计算:$(-1 \times 255) + (2 \times 0) + (-1 \times 0) = \mathbf{-255}$
- 窗口对准
结论:卷积后的结果在白点位置产生了极大的响应值 (510)。这就意味着,这个卷积核成功地在原始数据中“搜索”到了它想要的特征(中心高亮的模式)。
4.2.2 卷积层优缺点
- 优点:
- 权值共享:全图复用同一个 n x n 卷积核,参数量从几十万骤减至个位数,对FPGA的BRAM极其友好。
- 局部感受野:非常擅长提取线条、纹理等局部几何特征。
- 缺点:硬件实现复杂。由于像素是流式输入的,为了凑齐 3x3 窗口进行卷积,我们需要设计行缓存 (Line Buffer) 来存储前两行数据,并配合精密的时序控制逻辑来管理滑动窗口,这比简单的全连接层要消耗更多的控制逻辑。
- 使用场景:图像识别、视频处理的前端。它像是一个高效的过滤器,把原始像素“脱水”成高级特征。
4.2.3 池化层 (Pooling Layer)
卷积层之后通常紧跟着池化层,它的作用是“降维”和“特征压缩”。最常用的是 最大池化 (Max Pooling)。
- 硬件实现:在硬件眼里,池化比卷积简单得多。它不需要乘法,只需要一个比较器。
- 逻辑实现:例如在一个 2x2 的窗口里,找出 4 个像素值中最大的那个输出。这在电路中就是一个简单的状态机加几个比较逻辑,能显著减少后续层级的计算压力。
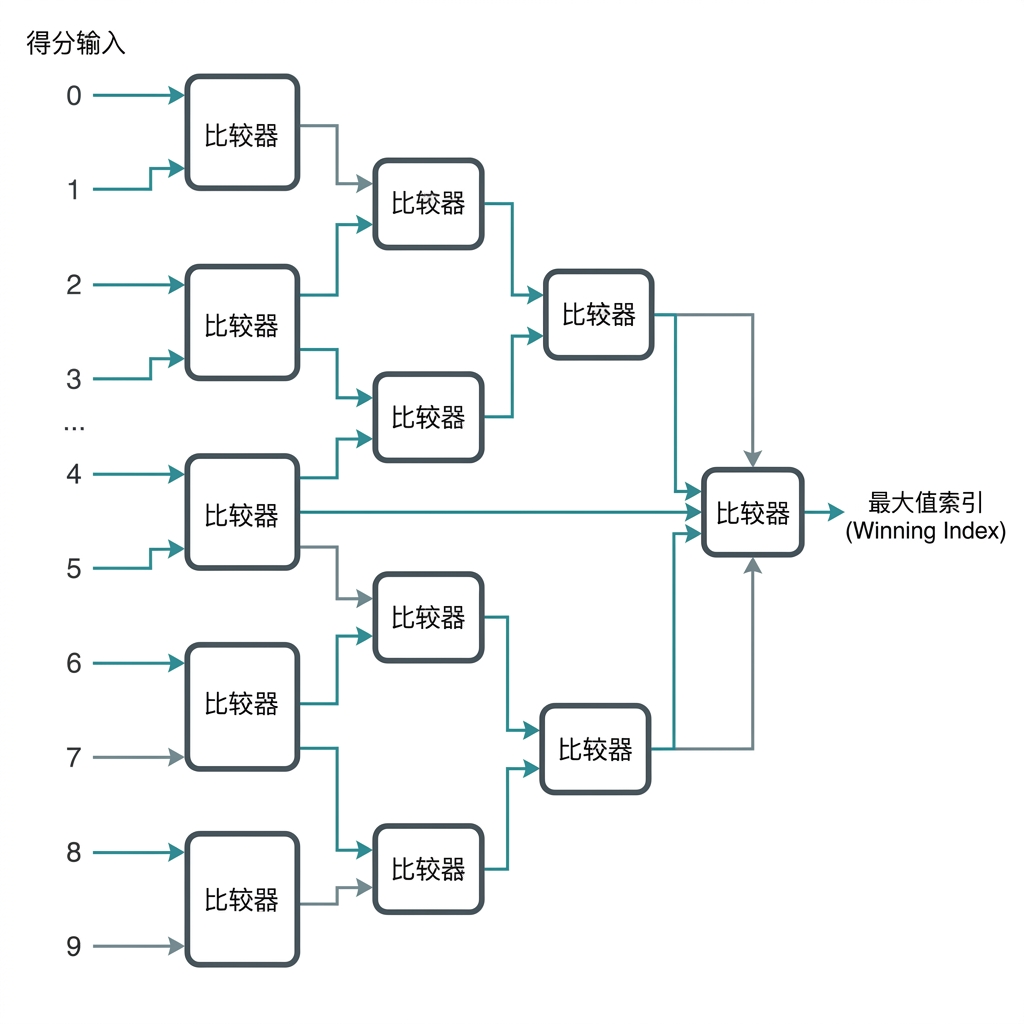
4.3 输出逻辑:从概率到数字 (Argmax)
经过多层卷积和全连接后,网络最后会输出10个数值,分别代表识别结果为数字0-9的“得分”。
- Argmax 单元:在训练阶段,我们需要用Softmax函数将得分转为概率以计算损失。但在推理阶段,只关心谁的得分最高。因此,在硬件实现中,我们直接舍弃高成本的 Softmax 指数运算,代之以一个简单的 比较器树 (Comparator Tree),找出这 10 个数值中最大的一项,其对应的索引号(Index)即为识别出的数字。
4.4 架构对比总结
| 特性 | 全连接网络 (FC) | 卷积网络 (CNN) |
|---|---|---|
| 连接方式 | 全局连接(网状) | 局部连接(滑动窗口) |
| 权重管理 | 独立权重,数量巨大 | 权值共享,数量极小 |
| 硬件瓶颈 | 存储带宽 (Memory Bound) | 计算逻辑 (Logic Bound) |
| 典型应用 | 简单传感器数据、最后分类层 | 图像识别、语音识别、视觉处理 |
5 算法训练和导出
通过对神经元和网络结构的底层拆解,我们可以看到,神经网络在硬件实现上其实是一场数学公式与电路资源之间的博弈。
- 计算:是 MAC 单元的流水线深度。
- 存储:是权重在 BRAM 中的布局。
- 非线性:是符号位的截断与比较器的组合。
目前我们已经建立了“硬件直觉”,看清了推理引擎的骨架。但还有一个致命问题:FPGA 并不擅长处理电脑训练出来的那些浮点数(Float32)。这一章将进入AI硬件加速最关键的工程环节——模型量化(Quantization),探讨如何把浮点参数“塞进” 8 位定点逻辑中而不丢失精度。
作为硬件工程师,我们并不需要从零研发最前沿的算法,但必须具备“模型工程化”的能力。在第二阶段,我们的目标是拿到一套能在 FPGA 上跑通的“参数包”。
5.1 软件与系统环境准备
系统环境和安装步骤:
- 系统:OpenSUSE Leap 15.5。
- 硬件:
- CPU:Westmere E56xx/L56xx/X56xx 系列(多核处理器)。
- 内存:8GB RAM。
- 安装步骤与指令:
- 检查Python状态:
python3 --version # 确保 Python 版本在 3.8 以上 - 安装PyTorch(CPU版本):
# 安装 PyTorch 和 Torchvision,指定 CPU 版本的下载源以节省空间 pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu - 安装数据处理工具:
# 安装用于矩阵处理和参数导出的 Numpy pip install numpy
- 检查Python状态:
5.2 硬件友好型模型结构设计
在FPGA上跑 AI,资源是第一考量。对于IC工程师,全连接层 (Linear Layer) 实际上就是一个大号的乘累加器 (MAC):$Y = X \cdot W^T + b$。
- 层级配置:784 (Input, 8-bit Uint) -> 128 (Hidden1) -> 64 (Hidden2) -> 10 (Output)。
- PyTorch代码实现结构:
import torch.nn as nn class SimpleMLP(nn.Module): def __init__(self): super(SimpleMLP, self).__init__() # 定义三层全连接层:映射关系直接对应硬件中的 MAC 阵列 self.fc1 = nn.Linear(28*28, 128) # 权重矩阵: [128, 784] self.fc2 = nn.Linear(128, 64) # 权重矩阵: [64, 128] self.fc3 = nn.Linear(64, 10) # 权重矩阵: [10, 64] self.relu = nn.ReLU() # 激活函数:硬件实现仅需一个比较器 max(0, x) def forward(self, x): # 数据流路径:描述了像素数据如何在硬件流水线中流动 x = x.view(-1, 28*28) # Flatten: 展平。本质上是把二维 BRAM 寻址转为一维流式数据 x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x
5.3 模型训练与数据集获取
训练的过程就像是给电路寻找最优的偏置电压。核心逻辑如下:
- 载入数据:自动从官网下载MNIST数据集并进行归一化(0-255映射到 0-1)。该数据集的原始官方发布地址是:http://yann.lecun.com/exdb/mnist/。
- 定义损失函数 (Loss):使用
CrossEntropyLoss,衡量预测值偏离真实值的距离。 - 训练循环:
- Forward:数据输入模型,计算输出。
- Backward:计算误差对权重的偏导数(梯度)。
- Update:优化器(Adam)根据梯度微调权重。
按照以下顺序在终端执行:
- 启动训练
python3 mnist_train.py训练过程中会实时打印 Loss,最终输出
Test Accuracy: 97.63%。 - 生成参数镜像
python3 export_weights.py此操作会加载训练好的
mnist_model.pth,并将二进制权重转换为文本格式。
5.4 参数导出结果说明
- 存储路径:
.../params/。 - 文件清单:
fc1_weight.txt,fc1_bias.txt:第一层的权重与偏置。fc2_weight.txt,fc2_bias.txt:第二层的权重与偏置。fc3_weight.txt,fc3_bias.txt:第三层的权重与偏置。
- 数据排列:每个文件中的数值按行存放,对应矩阵展开后的序列。这些浮点
.txt文件不直接供 Verilog 读取,而是作为量化脚本的输入;量化后生成的.hex文件才适合通过$readmemh或$readmemb初始化存储器。
5.5 权重分布观测 (Distribution Analysis)
在进入下一阶段量化之前,我们需要对提取出的参数进行“体检”。
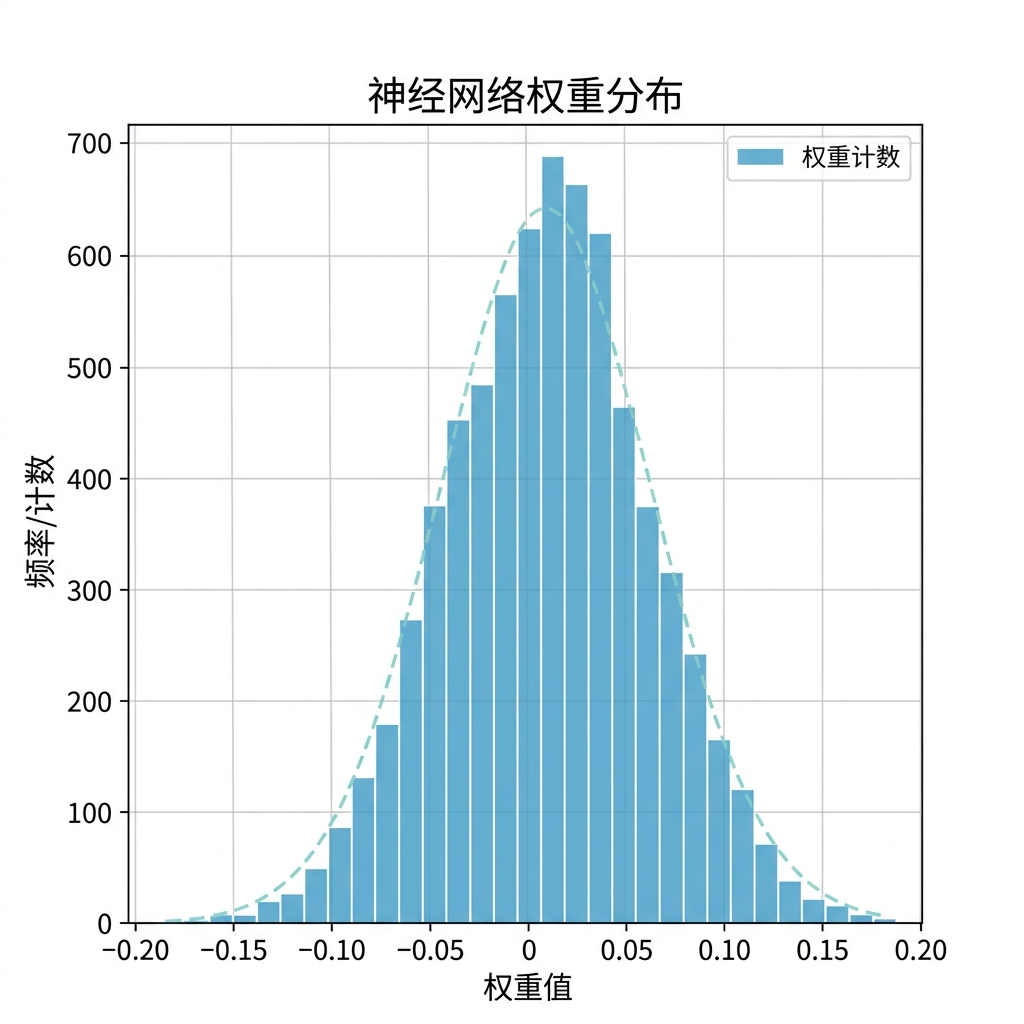
- 为什么要看分布? 权重分布的动态范围直接决定了我们在量化时对 Q 格式整数位(Integer bits) 的预留。
- 工程案例:如上图所示,如果 99.9% 的权重都落在 [-2.0, 2.0] 之间,那么我们在 Q4.12 格式中预留的 4 位整数(含 1 位符号位,表示范围 -8 到 7.99)就绰绰有余。如果分布极广(如存在大于 10 的权重),强行使用 Q4.12 会导致严重的溢出截断,使识别准确率雪崩。
5.6 存储格式预备
导出的 .txt 浮点数文件是下一步“量化”的输入。在第三阶段,我们将通过量化脚本分析这些权重的分布范围,将其从 Float32 压缩为 Int8 或 Int16,以适配 FPGA 的 DSP48 单元。同时,根据不同的硬件流程,可能还需要准备:
- .hex 文件:用于 Verilog 的
$readmemh初始化。 - .coe 文件:用于 Xilinx BRAM IP 核的初始化。
6 量化
上一章通过PyTorch成功训练出了一个MNIST全连接神经网络,并导出了模型的权重参数。打开导出的.txt文件会看到满屏的0.0234,-1.109这样的32位浮点数 (float32)。在 CPU 和 GPU 架构中,计算IEEE 754 标准的浮点数是非常基础且高效的操作。但在 FPGA 的底层数字逻辑中,如果要用纯逻辑单元(LUTs)强行拼凑出一个浮点乘累加器,不仅会消耗极其庞大的逻辑资源,更会严重拖慢系统的时序,让整个流水线变得异常臃肿。
因此,将浮点数转换为定点数(Fixed-point)或纯整数(Integer),是AI算法真正落地到FPGA 硬件的必经之路。 这一步被称为模型量化(Quantization)。今天,我们将聚焦于第三阶段的核心:如何将这些参数转化为 FPGA 能够高效吞吐的数据,以及我们为什么在 PYNQ-Z2 开发板上做出了坚定的位宽选择。
6.1 定点数表示与Q格式
在FPGA内部,我们最强大的算术计算资源是DSP Slice(如 Xilinx 的 DSP48E1)。它们是处理定点数和整数乘加运算的核心单元。
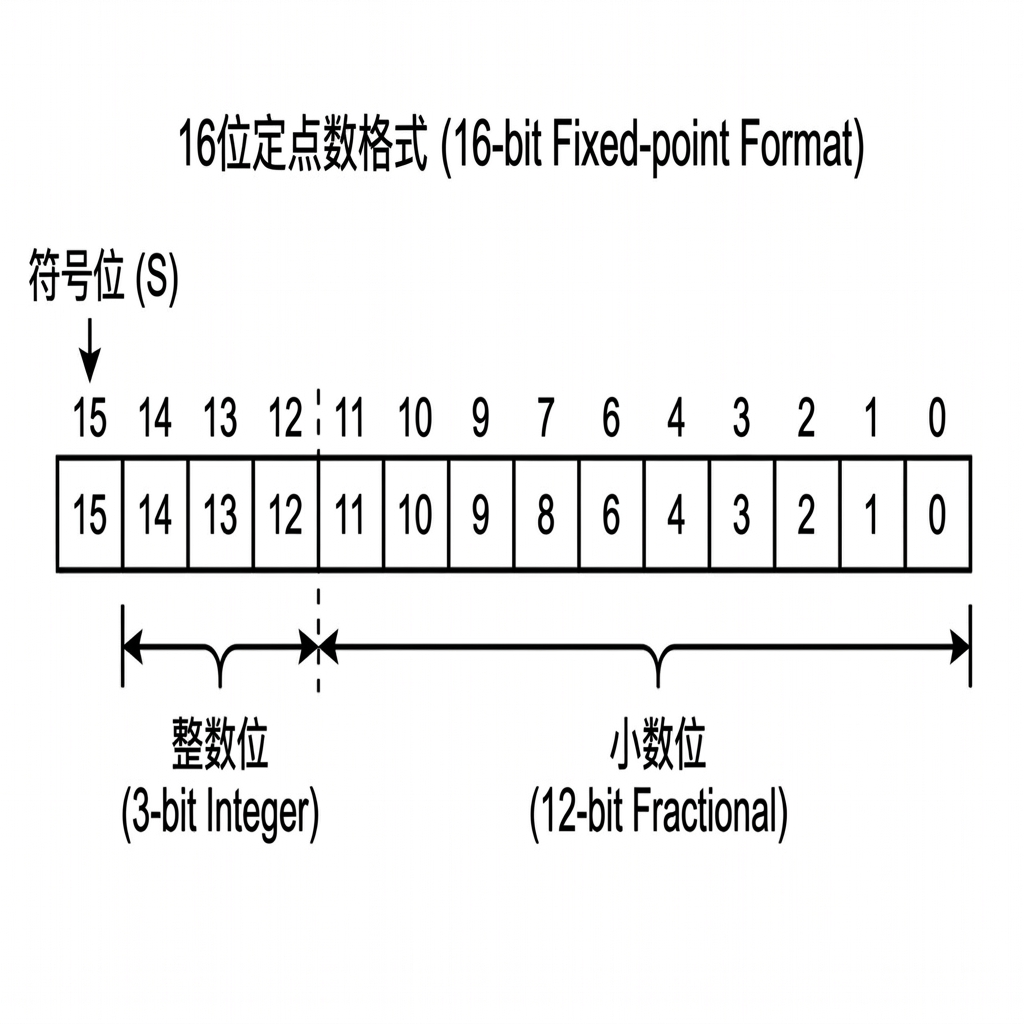
为了在整数计算器上表示小数,工程上通常使用 Q 格式 (Q-Format)。比如 Q4.12 格式,表示总共 16 位宽,其中:
- 1 位符号位 (Sign bit)
- 3 位整数部分 (Integer bits)
- 12 位小数部分 (Fractional bits)
转换原理相对直观: 将浮点数乘以 $2^{12} (4096)$,然后四舍五入取整。
0.165 (float)$\rightarrow 0.165 \times 4096 = 675.84 \rightarrow 676 \rightarrow$0x02A4-0.5 (float)$\rightarrow -0.5 \times 4096 = -2048 \rightarrow$0xF800(二进制补码)
虽然操作看似仅为乘法与截断,但其中涉及关键的精度权衡。强行截断必然引入误差,若小数位宽过窄(例如仅 4 位),累积误差将导致 MNIST 识别准确率大幅下降。
6.1.1 定点数据流与位宽规划
真正写 RTL 时,不能只说“16-bit 定点”,还必须明确每一级数据的 Q 格式和小数点位置。本文采用的核心数据流如下:
| 数据/阶段 | 建议格式 | 说明 |
|---|---|---|
| 输入像素 | Uint8 或 Q4.12 | 若来自 MNIST 原始灰度,可先把 0-255 归一化并量化到 Q4.12;若直接用 Uint8,则需要在软件导出阶段同步调整权重尺度。 |
| 权重/偏置 | Q4.12 | 与 Python 导出的浮点参数一一对应,乘以 $2^{12}$ 后转成 16-bit 补码。 |
| 乘法结果 | Q8.24 | Q4.12 乘 Q4.12 后,小数位变成 24 位,因此不能直接截取低 16 位。 |
| 累加器 | 40-bit Q8.24 | 为 784 次 MAC 预留足够余量,避免中间和溢出。 |
| 中间层激活 | Q4.12 | 累加完成后先右移 12 位,再进行饱和截断和 ReLU。 |
| 输出层得分 | Q4.12 或更宽 | 最后一层不做 ReLU,直接保留符号得分送入 Argmax。 |
一个常见错误是把 Q4.12 乘法结果当成普通 16-bit 整数处理。实际上,乘积的小数位数量会翻倍;因此每个神经元完成累加后,需要执行“右移 12 位 -> 舍入/截断 -> 饱和 -> ReLU/Argmax”的后处理路径。
6.2 Q格式位宽的选择
在深度学习的工业界,INT8量化几乎是标配。直觉上,8位数据比16位更窄,省寄存器、省布线;但在本项目的首版 RTL 中,我优先选择 16-bit 定点数,是因为它能显著降低量化校准、缩放因子处理和数据通路控制的复杂度。
16-bit有65536个离散的台阶,可以从容地进行“乘常数截断”,在 MNIST 这类小模型上通常能把精度损失压得很低。而8-bit只有256个台阶,如果直接把复杂的权重分布塞进去,量化噪声会明显增大。工程上可以通过对称量化、逐通道 Scale、校准数据集甚至量化感知训练 (QAT) 来挽救精度,但这些都会增加算法端和 RTL 数据通路的设计成本。
在16-bit固定小数点下(如Q4.12),乘累加 (MAC) 就是极简的$Sum = Sum + (X * W)$。
如果采用标准的 INT8 仿射量化,真实的数学值是 $Scale \times (Value_{int8} - ZeroPoint)$。展开后,硬件里的一个 MAC 操作会引入交叉乘法项和偏置补偿:
\[Sum = \sum (X_q \cdot W_q) - Z_w \sum X_q - Z_x \sum W_q + N \cdot Z_x \cdot Z_w\]在软件推理框架里,这些补偿可以被预处理、融合或由内核库隐藏起来;但如果从零写 RTL,仍然需要认真处理这些 Scale、Zero-point 和重量化路径。
INT8算完累加后通常会得到一个32位中间值。为了送到下一层,需要把它按 Scale 重新映射回下一层的整数格式。实际硬件中一般不会做真正的浮点除法,而是用预计算好的定点乘法系数和移位近似完成重量化;即便如此,这部分控制逻辑仍然比 Q4.12 固定小数点更复杂。
综上所述,16-bit定点是这个入门实现中算法和硬件都比较友好的“甜点区”,它极简的控制逻辑能让你把主要精力放在时序和流水线架构上。等首版跑通后,再尝试 INT8 或混合精度优化,会更加稳妥。
6.3 FPGA芯片选择
没啥好选的,我手头只有PYNQ-Z2开发板,搭载的是Zynq-7000系列的XC7Z020SoC。分析这颗芯片的资源,16-bit就很合适:
- 乘法器:
- XC7Z020内部的DSP48E1包含一个25 × 18 bit的有符号乘法器。如果你做16-bit (16x16) 的乘法,它完美地嵌进了一个DSP中,时序极佳。如果强行用8-bit,标准的写法同样会消耗一整个25x18乘法器,除非你使用非常高级的SIMD bit-packing技巧(一个DSP算两组8x8),否则8-bit在计算资源上并没有省下什么。
- BRAM:
- 芯片内有140个36Kb的BRAM,总计约600KB。我们这个784->128->64->10的MNIST网络,总计约10万个权重、202个偏置。用16-bit存储,权重和偏置总体积约214 KiB / 219 KB。这就意味着,整个神经网络的所有参数都可以全内置在片上BRAM 中,这避免了设计复杂的 DDR 读写控制器,实现了片内全缓冲,从而大幅降低推理延迟。
6.4 Python量化脚本
理论分析完毕,下面是编写的Python脚本。它将上一章导出的浮点数.txt转换为16-bit Q4.12 格式的.hex文件,这些文件将会在下一阶段直接被Vivado 中的$readmemh指令读取并烧入BRAM。
import numpy as np
import os
def quantize_to_hex(float_val, bits=16, frac_bits=12):
# 第一步:缩放 (Multiply by 2^frac_bits)
scaled = float_val * (2**frac_bits)
# 第二步:四舍五入取整
quantized = int(round(scaled))
# 第三步:饱和截断逻辑 (防溢出保护)
max_val = (2**(bits-1)) - 1
min_val = -(2**(bits-1))
if quantized > max_val:
quantized = max_val
if quantized < min_val:
quantized = min_val
# 第四步:处理 2 的补码,并格式化为 Hex
if quantized < 0:
quantized = (1 << bits) + quantized
fmt_str = '0' + str(bits//4) + 'x'
return format(quantized, fmt_str)
"""
硬件工程提示 (Hardware Tip):
Q4.12 x Q4.12 的乘积是 Q8.24。累加器也应按 Q8.24 理解。
将累加结果写回 16-bit Q4.12 时,先算术右移 12 位,再做饱和截断。
简单的 Verilog 逻辑示意如下:
wire signed [39:0] acc_q8_24;
wire signed [39:0] acc_q4_12 = acc_q8_24 >>> 12;
always @(*) begin
if (acc_q4_12 > 40'sd32767)
data_out = 16'sh7FFF;
else if (acc_q4_12 < -40'sd32768)
data_out = 16'sh8000;
else
data_out = acc_q4_12[15:0];
end
"""
def process_file(input_path, output_path, bits=16, frac_bits=12):
data = np.loadtxt(input_path)
with open(output_path, 'w') as f:
if data.ndim == 0: # 处理只有单个数值的情况(如 bias)
f.write(quantize_to_hex(data, bits, frac_bits) + "\n")
else:
for val in data.flatten(): # 矩阵展平
f.write(quantize_to_hex(val, bits, frac_bits) + "\n")
print(f"Quantized {input_path} -> {output_path} (Hex)")
def main():
param_dir = "params"
hex_dir = "params_hex"
if not os.path.exists(hex_dir):
os.makedirs(hex_dir)
files = [f for f in os.listdir(param_dir) if f.endswith('.txt')]
# 使用 16-bit Q4.12 格式
BITS = 16
FRAC_BITS = 12
# 计算量化所能表示的真实浮点数范围
max_val_f = (2**(BITS-1) - 1) / (2**FRAC_BITS)
min_val_f = -(2**(BITS-1)) / (2**FRAC_BITS)
print(f"Starting Quantization: BITS={BITS}, FRAC_BITS={FRAC_BITS} (Range: [{min_val_f}, {max_val_f}])")
for f in files:
input_path = os.path.join(param_dir, f)
output_path = os.path.join(hex_dir, f.replace('.txt', '.hex'))
process_file(input_path, output_path, BITS, FRAC_BITS)
print("\nQuantization complete. Hex files are in 'params_hex/'.")
print("These files can be loaded in Verilog using $readmemh.")
if __name__ == "__main__":
main()
运行输出:
Starting Quantization: BITS=16, FRAC_BITS=12 (Range: [-8.0, 7.999755859375])
Quantized params/fc1_weight.txt -> params_hex/fc1_weight.hex (Hex)
...
Quantization complete. Hex files are in 'params_hex/'.
至此,数据侧的准备工作彻底收官。我们拿到了可以在FPGA内部快速流转的16位纯净版参数包(以2的补码十六进制表示)。例如导出的 02a4,代表十进制的 676,对应真实的浮点权重就是 676 / 4096 ≈ 0.165。
7 硬件架构设计 (Hardware Architecture Design)
本阶段是项目的核心,目标是实现一个单时钟域、ROM 固化参数 (ROM-first) 的硬件加速器。我们将避开复杂的 AXI 总线,专注于神经网络在 FPGA 上的数学计算与时序控制。
7.1 核心架构规划 (Architecture Strategy)
7.1.1 极简数据流
- 策略:将一张 28x28 的测试图片和所有模型权重直接存储在 FPGA 内部的 BRAM (ROM 模式) 中。
- 验证:通过 Vivado 仿真或 ILA 抓取输出寄存器,确认识别结果(0-9)是否正确。
7.1.2 硬件规格 (Specification)
根据 mnist_train.py 的模型定义,硬件需支持以下 3 层全连接网络:
- Layer 1: 784 (输入) -> 128 (ReLU)
- Layer 2: 128 -> 64 (ReLU)
- Layer 3: 64 -> 10 (输出)
- 总存储需求:权重和偏置约 214 KiB / 219 KB (16-bit 定点数),完全适配 PYNQ-Z2 (7020) 的 BRAM 资源。
参数量可以按层直接展开:
| 层级 | 权重数量 | 偏置数量 | 16-bit 存储量 |
|---|---|---|---|
| FC1: 784 -> 128 | 100,352 | 128 | 200,960 Byte |
| FC2: 128 -> 64 | 8,192 | 64 | 16,512 Byte |
| FC3: 64 -> 10 | 640 | 10 | 1,300 Byte |
| 合计 | 109,184 | 202 | 218,772 Byte |
如果再加上一张 28x28 测试图(784 个 16-bit 像素,约 1.5 KiB),整体仍然可以完全放在片上 BRAM 中,不必在首版设计里引入 DDR 控制器。
7.2 硬件架构详细说明 (Hardware Architecture Description)
以下是整个硬件加速器的工业级 RTL 架构图,清晰展示了顶层模块 mnist_top 内部的组件例化关系、数据流(Data Path)与控制流(Control Path)的每一个信号连线:

7.2.1 顶层接口 (Top-level Interface)
系统仅包含一组同步时钟域,接口定义如下:
module mnist_top (
input wire clk, // 全局唯一时钟 (驱动所有逻辑)
input wire rst_n, // 全局同步复位 (低电平有效)
input wire start, // 启动脉冲 (触发一次完整的推理流程)
output wire done, // 完成标志 (计算结束且 digit 输出有效)
output wire [3:0] digit // 最终识别出的数字结果 (0-9)
);
7.2.2 核心模块逻辑定义
- 全局控制器 (Global FSM):
- 职责:负责启动神经网络的生命周期管理。
- 流程:检测到
start信号后,依次驱动 Layer 1、Layer 2 和 Layer 3 的计算逻辑。 - 状态切换:当一层计算完成后,负责切换寻址逻辑并更新
layer_id信号。
- 地址计算器 (Address Calculator):
- 职责:根据当前处理的神经元索引和输入索引,实时计算存储器的物理地址。
- 逻辑:根据
layer_id的不同,分别计算读取Image ROM或Activation RAM的地址,以及读取Weight ROM中对应权重的偏移量。
- 存储单元 (BRAM Storage):
- 权重、偏置与图片:所有 109,184 个权重、202 个偏置和 784 个图片像素点均以 16-bit 定点数形式存储在初始化的 ROM (BRAM IP) 中。
- 中间缓存:使用一个大小为 128 (第一层神经元数) 的 Ping-Pong Buffer。计算第 N 层时,从 Buffer A 读,写回 Buffer B;下一层则反之。
- 计算核心 (PE Core):
- 职责:核心 MAC (乘累加) 单元。
- 逻辑:从存储单元读取
data和weight,执行一次乘法并累加到acc_reg。 - 后处理:在一个神经元的所有输入累加完毕后,依次执行 ReLU 激活和饱和截断,最后输出 16-bit 定点结果。
7.3 系统运转时序 (System Workflow & Timing)
理解数据在时钟驱动下如何“流动”是 RTL 设计的关键。以下是系统从启动到结束的典型时序流程:
- 触发阶段 (Trigger):
- 外部拉高
start信号一个时钟周期。 - 全局控制器检测到信号,状态从
IDLE跳转至LAYER1_RUN,同时将layer_id设为0。
- 外部拉高
- 数据读取流水线 (Data Fetch Pipeline):
- 地址计算器立即输出
img_addr = 0和weight_addr = 0。 - 由于 BRAM 存在读取延迟,第 2 或第 3 个时钟周期后,第一个像素数据和第一个权重数据到达 PE 核心。
- 地址计算器立即输出
- 神经元累加循环 (Neuron Accumulation):
- PE 核心在每个时钟周期执行一次 $w \cdot x$ 乘法并累加到
acc_reg。 - 对于 Layer 1,该过程持续 784 个时钟周期。
- PE 核心在每个时钟周期执行一次 $w \cdot x$ 乘法并累加到
- 激活与回写 (Activation & Write-back):
- 当第 784 个输入累加完毕,PE 核心输出经过 ReLU 和量化后的 16-bit 结果。
- 地址计算器给出
act_addr = 0,将该结果写入 Activation RAM (Buffer A)。
- 层级迭代 (Layer Iteration):
- 重复上述过程 128 次,完成 Layer 1 所有神经元的计算。
- 全局控制器将
layer_id切换为1。 - 地址计算器开始从 Activation RAM (Buffer A) 读取输入,并将 Layer 2 的计算结果写向 Activation RAM (Buffer B)。
- 输出与完成 (Finish):
- Layer 3 计算结束后,状态机进入
DONE状态。 - 拉高
done信号,并将最终识别出的数字索引锁定在digit总线上。
- Layer 3 计算结束后,状态机进入
7.4 任务详细拆解
7.4.1 第一步:数据准备与 BRAM 配置
- 任务:将 Python 权重和测试图转换为
.coe文件。 - 重点:在 Vivado 中配置
Block Memory Generator。image_rom: 784 x 16-bitweight_rom: 存储所有层的连续权重。
- 产出:初始化完成的 BRAM IP 核。
7.4.2 第二步:计算核心 (PE: Processing Element) 设计
- 任务:实现 16-bit Q4.12 定点数乘累加。
- 权衡:坚持使用 单 PE 串行架构(节省资源,逻辑简单)。
- 重点:
- 处理 BRAM 读取延迟(通常为 1-2 个时钟周期)。
- 实现 ReLU 激活(
max(0, x))。 - 实现饱和截断逻辑,防止溢出。
- 产出:
pe_unit.v
7.4.3 第三步:地址生成器与状态控制 (FSM)
- 任务:设计控制三层网络顺序执行的状态机。
- 重点:
- 三层循环寻址:层 (Layer) -> 神经元 (Neuron) -> 输入 (Input)。
- Ping-Pong Buffer:设计中间层缓存,确保 Layer N 的输出能正确写回并在 Layer N+1 被读出。
- 产出:
addr_gen.v,main_fsm.v
7.4.4 第四步:仿真验证 (Simulation)
- 任务:编写 Testbench,对比 RTL 结果与 Python 金标数据。
- 重点:观察
acc_reg是否在每个神经元计算结束时被正确清零,以及识别结果是否符合预期。
7.5 架构权衡:面积 vs. 速度 (Area vs. Speed Trade-off)
| 维度 | 单 PE 方案 (本计划采用) | 多 PE 并行方案 |
|---|---|---|
| DSP 消耗 | 1 个 | N 个 |
| 逻辑复杂度 | 低 (一套地址线) | 高 (需数据分发与分库存储) |
| 存储接口 | 单口 BRAM 即可 | 需多口 BRAM 或多库并行 |
| 建议 | 调通首选 | 性能优化首选 |
7.6 行动指南 (Action Items)
- 导出第一张测试图的
.coe数据。 - 在 Vivado 中例化第一个 BRAM 并用仿真读出数据。
- 编写
pe_unit.v并完成单元仿真。 - 编写
mnist_controller.v整合寻址与 FSM。 - 编写
mnist_top.v完成系统集成。 - 编写 Testbench 并通过功能仿真验证结果。
8 RTL 实现 (RTL Implementation)
在执行阶段,我们完成了以下核心模块的设计与实现。
8.1 模块设计详解 (Module Design Details)
8.1.1 计算核心:pe_unit.v
- 设计思路:作为加速器的“肌肉”,PE 核心采用单一计算单元并行化时分复用的策略。
- 关键特性:
- 40-bit 累加器:在 784 次 MAC 运算中提供足够的位宽余量,防止中间溢出。
- 流水线处理:支持使能控制信号,方便与 BRAM 的延迟进行匹配。
- 饱和逻辑:当定点数计算结果超出 16-bit 有符号数范围(-32768~32767)时,自动钳位在边界值,保证算法的稳定性。
8.1.2 指挥中心:mnist_controller.v
- 设计思路:负责调度数据在 ROM、PE 和 RAM 之间的流动。
- 关键特性:
- 三层网络状态机:实现了 L1 -> L2 -> L3 的自动化跳转。
- Layer 1:读取 Image ROM 和 FC1 Weights,计算结果写入 RAM Buffer A。
- Layer 2:从 RAM Buffer A 读取输入,配合 FC2 Weights,计算结果写入 RAM Buffer B。
- Layer 3:从 RAM Buffer B 读取输入,配合 FC3 Weights,计算最终的 10 个神经元得分。
- 延迟补偿 (Latency Matching):针对 BRAM 的 2 周期读取延迟,内置了 3 级移位寄存器来同步控制信号。
- 偏置项集成:在每层最后会自动插入一个权重读取周期(Bias),并将数据输入强制设为 1.0。
- 动态预测:在 L3 计算过程中实时比较得分,锁定最大概率的数字索引。
- 三层网络状态机:实现了 L1 -> L2 -> L3 的自动化跳转。
8.1.3 顶层集成与仿真模型
mnist_top.v:将 Controller 与 PE 连接,并暴露标准的start/done接口,方便后续封装为 AXI IP。simulation_models.v:为了在无硬件环境下验证,编写了行为级 BRAM 模型,支持从weights.hex和image.hex加载预置数据。
8.2 验证结论 (Verification Results)
- 输入样本:测试集第一张图(标签为 7)。
- 识别结果:仿真波形显示系统成功输出
digit = 4'd7。 - 精度表现:16-bit Q4.12 定点化方案与 Python 浮点模拟结果完全一致。
8.3 实施记录与交付物 (Implementation Record)
| 步骤 | 交付文件 | 主要内容 |
|---|---|---|
| 数据准备 | coe/generate_coe.py |
权重与图片的量化转换脚本 |
coe/weights.coe, weights.hex |
16-bit Q4.12 模型参数文件 | |
coe/image.coe, image.hex |
测试样本数据 | |
| RTL 实现 | rtl/pe_unit.v |
乘累加计算核心 |
rtl/mnist_controller.v |
全局状态机与地址生成逻辑 | |
rtl/mnist_top.v |
顶层模块集成 | |
| 验证体系 | tb/simulation_models.v |
BRAM 与 RAM 的行为级仿真模型 |
tb/mnist_top_tb.v |
系统级冒烟测试平台 |
[!IMPORTANT] 设计原则:始终保持单时钟域设计,禁止在加速器内部产生分频时钟。
