1 前言
FIFO(First In First Out)是数字系统中最常见的 Buffer 结构之一,广泛用于流水线解耦、速率匹配、突发流量吸收、总线桥接以及跨时钟域数据传输。对于数字 IC 和 FPGA 设计而言,FIFO 看似简单,但真正容易出错的地方往往集中在:
full/empty边界判断;- 读写指针回绕;
- 同周期读写行为;
- FIFO 深度 sizing;
- peek / non-peek 行为差异;
- 异步 FIFO 的 CDC 安全性;
- reset 释放和跨域指针同步。
本文按照“先概念、再单时钟域、再边界问题、再跨时钟域”的顺序展开。阅读时可以先建立 FIFO 的基本模型,再理解 full / empty、深度 sizing、peek / non-peek 行为,最后进入异步 FIFO 和 CDC 设计。文中保留了完整 RTL、testbench、波形说明和工程 checklist,方便从原理一路对应到实现与验证。
2 阅读路线与文章结构
FIFO 文章很容易变成“概念、RTL、CDC、验证”混在一起。为了更系统地学习,建议把它拆成五层,可以按如下路径展开:
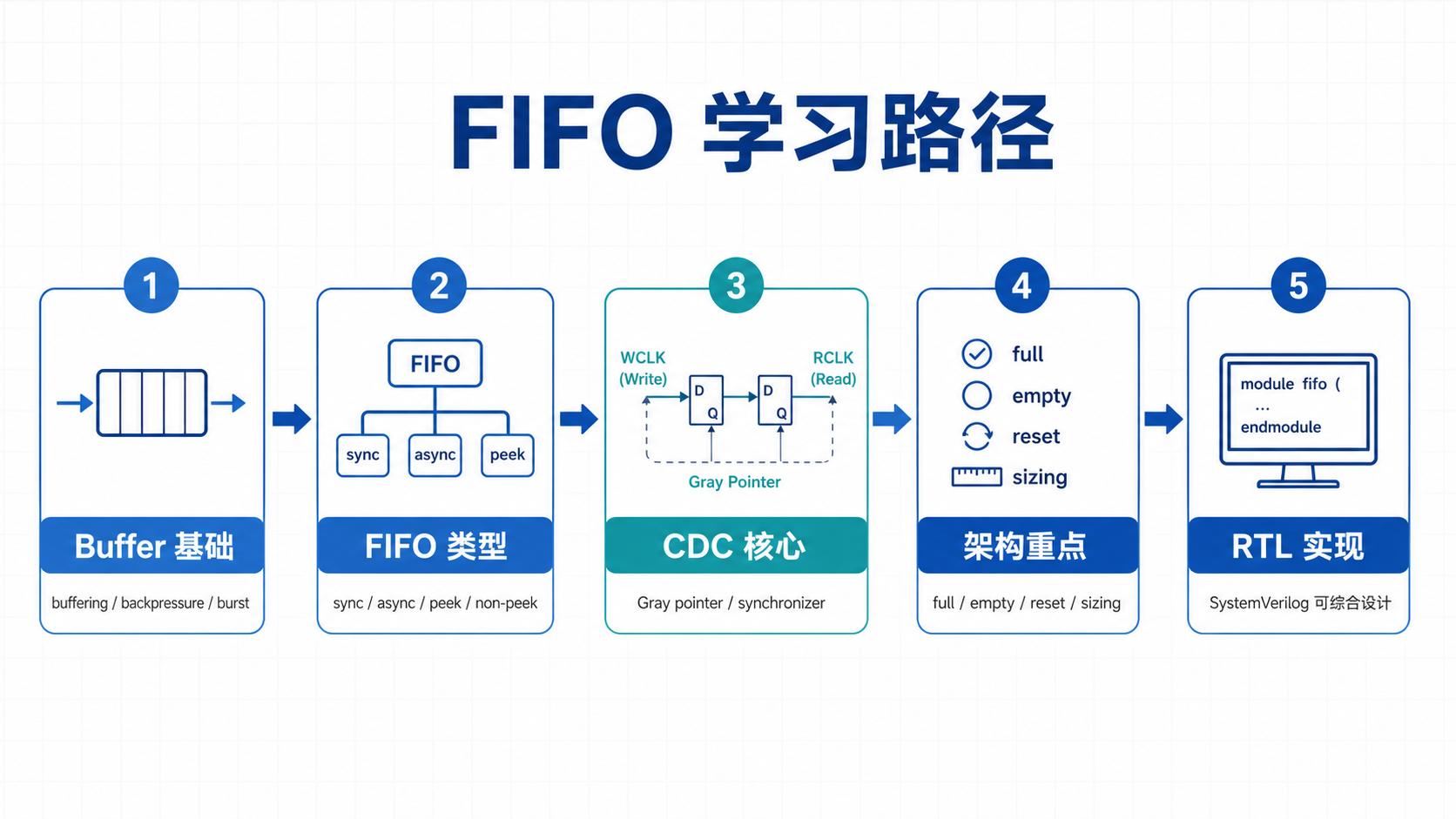
对应的学习目标如下:
| 层次 | 内容 | 对应章节 |
|---|---|---|
| Buffer 基础 | 理解 buffering、backpressure、burst absorption | 第 3 节 |
| 同步 FIFO | 单时钟域 FIFO 架构、接口语义、基础 RTL 和 testbench | 第 4 节 |
| 通用边界问题 | full/empty 判断、指针回绕、深度 sizing | 第 5、6 节 |
| 行为扩展 | peek、non-peek、FWFT 的区别和 Peek FIFO RTL | 第 7 节 |
| CDC FIFO | Gray pointer、异步 FIFO RTL、reset release、CDC checklist | 第 8 ~ 10 节 |
| 工程收束 | 架构分析重点、验证建议、总结和参考资料 | 第 11 ~ 14 节 |
如果只是想快速掌握写法,可以先读第 3、4、5、8、9 节;如果要做完整设计评审,则建议把第 6、10、11、12 节也一起检查。
3 Buffer 与 FIFO 的基本概念
3.1 为什么需要 Buffer
Buffer 的核心作用是解耦 producer 和 consumer,也就是临时存放数据,让发送数据的一方和接收数据的一方不用完全同步工作。比如上游模块一口气送来很多数据,而下游模块暂时来不及处理时,Buffer 可以先把数据存起来,等下游空闲后再慢慢取走。这样可以避免数据丢失,也能让系统控制逻辑更简单。
FIFO 常用于以下场景:
- 生产者和消费者速率不匹配;
- 下游模块可能会随机暂停接收数据,例如忙于处理其他任务,暂时不能继续读取;
- bus bridge 或 protocol bridge;
- pipeline stage 之间解耦;
- DMA、NoC、AXI-stream 等数据流通路;
- 异步时钟域之间的数据传输。
3.2 常见 Buffer 类型
| 类型 | 说明 |
|---|---|
| Register buffer | 通常只能暂存 1 个数据,也就是只有一个存储位置,常用于打拍 |
| Skid buffer | 常用于 ready/valid timing 优化 |
| Sync FIFO | 单时钟域多 entry buffer |
| Async FIFO | 跨时钟域 FIFO |
| Peek FIFO | 支持查看队头但不弹出 |
3.3 常用术语
FIFO 相关文章中经常会混用一些中英文术语,建议先明确含义:
| 术语 | 含义 |
|---|---|
| Producer / Consumer | 数据生产者 / 数据消费者 |
| Backpressure / 反压 | 下游无法继续接收时,通过 ready、full 或 credit 等信号让上游停止发送 |
| Occupancy / Level | FIFO 当前已经存放的数据个数 |
| Entry / Item / Beat | FIFO 中的一条数据。总线场景中常称 beat,队列场景中常称 entry |
| Head / Tail | 队头 / 队尾。读侧通常访问 head,写侧通常追加到 tail |
| Push / Pop | 写入 FIFO / 从 FIFO 弹出数据 |
| Burst absorption | FIFO 吸收上游突发流量的能力 |
| FWFT | First-Word Fall-Through,队头数据在 FIFO 非空时自动可见 |
4 同步 FIFO:单时钟域基础实现
学习 FIFO 可以先从同步 FIFO 开始,因为它只涉及一个时钟域,便于把注意力集中在存储阵列、读写指针、full / empty、同周期读写和接口握手语义上。异步 FIFO 会在此基础上增加 Gray pointer 和 CDC 同步。
同步 FIFO 的读写操作位于同一个时钟域。典型组成包括:
- 存储阵列;
- 写指针
wr_ptr; - 读指针
rd_ptr; - 计数器
count或 pointer 比较逻辑; full/empty状态;- 可选
almost_full/almost_empty。
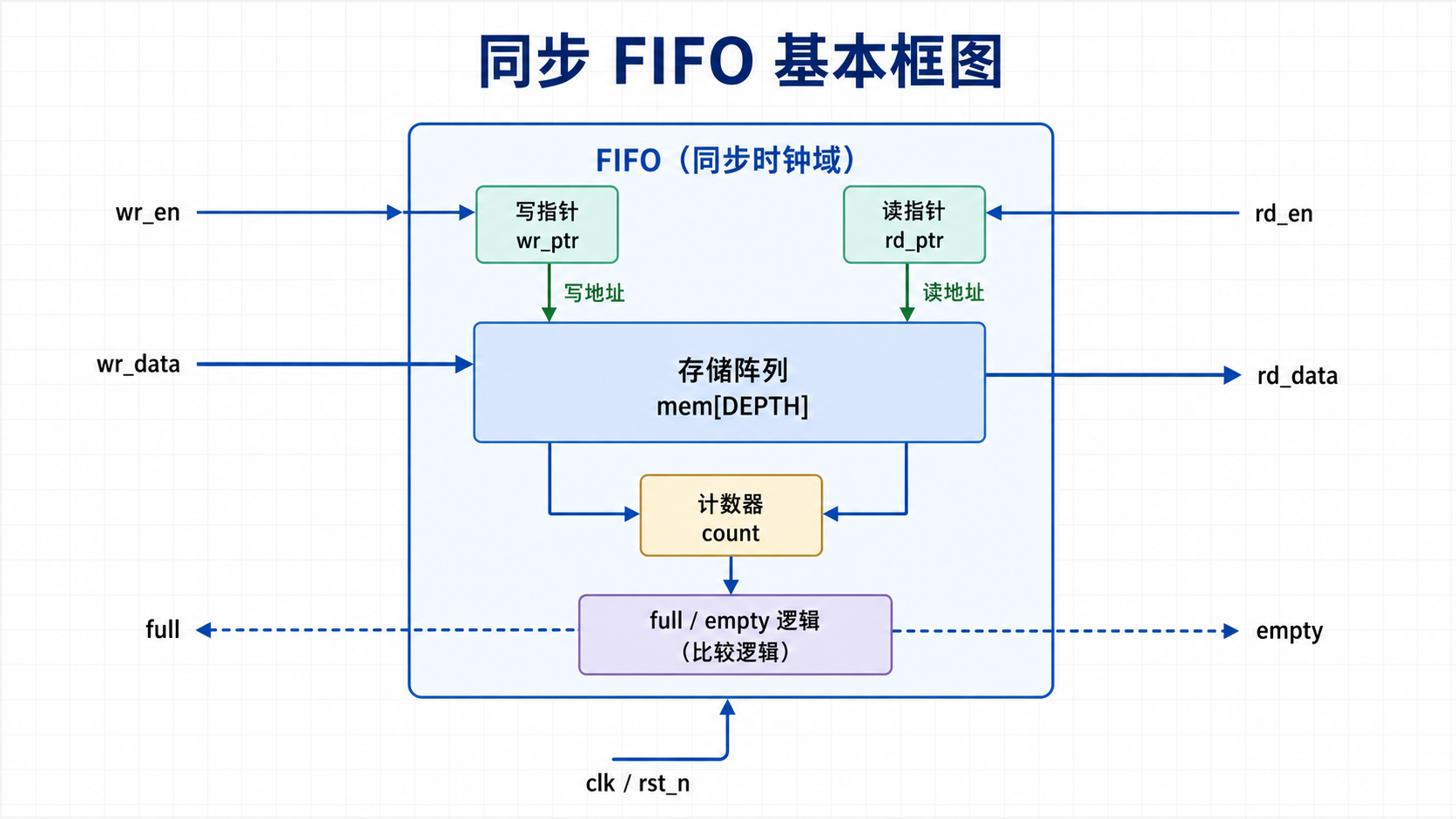
4.1 count-based full/empty
对同步 FIFO 而言,最直观的方式是使用 count 记录当前 FIFO 中的数据个数:
empty = count == 0
full = count == DEPTH
count 更新规则:
| 操作 | count 变化 |
|---|---|
| write only | count + 1 |
| read only | count - 1 |
| write and read | count 不变 |
| no operation | count 不变 |
4.2 与 ready/valid 接口的关系
为了和后面的 RTL 保持一致,本文统一使用以下信号名:
| 信号 | 方向 | 含义 |
|---|---|---|
wr_en |
上游 producer -> FIFO | 写请求。上游本周期希望向 FIFO 写入 wr_data |
wr_data |
上游 producer -> FIFO | 写入数据 |
full |
FIFO -> 上游 producer | FIFO 已满,通常用于对上游反压 |
do_write |
FIFO 内部事件 | 本周期真正写入 FIFO memory |
rd_en |
下游 consumer -> FIFO | 读请求。下游本周期希望从 FIFO 弹出一个 entry |
rd_data |
FIFO -> 下游 consumer | 当前读数据 / 队头数据 |
empty |
FIFO -> 下游 consumer | FIFO 为空,通常用于告诉下游当前没有有效数据 |
do_read |
FIFO 内部事件 | 本周期真正从 FIFO 弹出一个 entry |
因此,在本文 RTL 中,wr_en 表示上游发出的“写请求”,不是最终的“写成功”。真正写入 FIFO 的事件是 do_write:
assign do_read = rd_en && !empty;
assign do_write = wr_en && (!full || do_read);
这段逻辑表示:
rd_en && !empty时,读请求被接受,发生实际读出do_read;wr_en && !full时,FIFO 未满,写请求被接受,发生实际写入do_write;wr_en && full && do_read时,虽然当前 FIFO 是满的,但同周期实际读出释放了一个 entry,因此仍允许写入;wr_en && full && !do_read时,FIFO 满且没有实际读出,写请求不被接受。
如果把这个 RTL 接到 ready/valid 接口,可以把概念对应为:
| ready/valid 概念 | 本文 RTL 信号 |
|---|---|
上游 valid |
wr_en |
FIFO 返回给上游的 ready |
!full || do_read |
| 写侧握手成功 | do_write |
下游 ready |
rd_en |
FIFO 输出给下游的 valid |
!empty |
| 读侧握手成功 | do_read |
用 RTL 信号名表示就是:
assign wr_ready = !full || do_read; // 可选输出给上游的 ready
assign rd_valid = !empty; // 可选输出给下游的 valid
assign do_read = rd_en && rd_valid;
assign do_write = wr_en && wr_ready;
注意上面的 wr_ready 和 rd_valid 是为了说明 ready/valid 映射而引入的可选接口信号,后文基础 FIFO RTL 没有把它们作为端口列出,而是直接使用 full / empty 和内部 do_write / do_read 完成等价控制。
因此,所谓 “ready/valid interface” 和 “wr_en/rd_en interface” 主要区别不是 FIFO 内部存储结构不同,而是接口协议抽象层次不同:
| 接口风格 | 写侧含义 | 读侧含义 | 是否显式表达握手 |
|---|---|---|---|
wr_en / rd_en + full / empty |
wr_en 是写请求,full 表示 FIFO 是否拒绝写入 |
rd_en 是读请求,empty 表示 FIFO 是否无数据可读 |
不完全显式,需要使用者自己理解 wr_en && !full、rd_en && !empty |
| ready/valid | valid 表示发送方有数据,ready 表示接收方可接收 |
同样用 valid / ready 表示数据有效和接收许可 |
显式,valid && ready 就是传输成功 |
对于同一个同步 FIFO,这两种接口可以互相转换。例如写侧可以理解为:
// wr_en / full 风格
assign do_write = wr_en && !full;
// ready / valid 风格
assign wr_valid = wr_en;
assign wr_ready = !full;
assign do_write = wr_valid && wr_ready;
读侧可以理解为:
// rd_en / empty 风格
assign do_read = rd_en && !empty;
// ready / valid 风格
assign rd_valid = !empty;
assign rd_ready = rd_en;
assign do_read = rd_valid && rd_ready;
所以在本文语境中,wr_en / rd_en 是更贴近 FIFO 内部控制的接口写法;ready/valid 是更通用的数据流协议写法,常见于 AXI-Stream、NoC stream、pipeline stage 之间。二者本质上都要表达同一件事:只有请求方和接收方都允许时,数据传输才真正发生。
还需要注意,rd_valid = !empty 是否意味着 rd_data 同周期有效,取决于 FIFO 的读数据语义。如果 FIFO 是 register array 组合读或 FWFT 结构,rd_data 通常可以直接指向 head entry;如果底层是同步读 SRAM / BRAM,则往往需要额外的 prefetch register 或 rd_data_valid 对齐读延迟。
4.3 almost_full / almost_empty
除了 full 和 empty,工程中还经常需要 almost_full 和 almost_empty。它们的作用是提前进行流控,而不是等 FIFO 真正满或空之后才反应。例如:
parameter int ALMOST_FULL_TH = DEPTH - 2;
parameter int ALMOST_EMPTY_TH = 2;
assign almost_full = (count >= ALMOST_FULL_TH[CNT_WIDTH-1:0]);
assign almost_empty = (count <= ALMOST_EMPTY_TH[CNT_WIDTH-1:0]);
almost_full 常用于吸收 backpressure latency。例如上游看到反压后还会继续发送 2 拍数据,则不能等到 full 才停止上游,而应在剩余空间小于等于 2 时提前拉低 ready 或拉高 almost_full。
4.4 overflow / underflow 标志
为了方便 debug 和验证,也可以增加 overflow / underflow 检测:
assign overflow = wr_en && full && !do_read;
assign underflow = rd_en && empty;
其中 overflow 表示上游在 FIFO 满且没有实际读出腾空间的情况下仍尝试写入;underflow 表示下游在 FIFO 空时仍尝试读取。正式设计中可以选择将这些信号作为 sticky error flag,也可以只在仿真中用 assertion 检查。
4.5 同步 FIFO RTL
下面给出一个 count-based 同步 FIFO,支持同周期读写。为了方便指针回绕,深度参数建议取 2 的幂。
需要注意:下面的示例代码虽然将 DEPTH 参数化,但指针更新使用自然二进制加法回绕:
wr_ptr <= wr_ptr + 1'b1;
rd_ptr <= rd_ptr + 1'b1;
因此该示例实际要求 DEPTH 为 2 的幂。如果 DEPTH 不是 2 的幂,例如 DEPTH = 10,则 $clog2(DEPTH) 得到 4 bit 地址,指针可能访问 10 ~ 15 这些非法地址。非 2 的幂深度需要在指针达到 DEPTH-1 后显式回绕到 0,或增加额外地址保护逻辑。
module sync_fifo #(
parameter int DATA_WIDTH = 32,
parameter int DEPTH = 16,
parameter int ALMOST_FULL_TH = DEPTH - 2,
parameter int ALMOST_EMPTY_TH = 2,
parameter bit FWFT = 1'b1,
localparam int ADDR_WIDTH = $clog2(DEPTH),
localparam int CNT_WIDTH = $clog2(DEPTH + 1)
) (
input logic clk,
input logic rst_n,
input logic wr_en,
input logic [DATA_WIDTH-1:0] wr_data,
output logic full,
output logic almost_full,
input logic rd_en,
output logic [DATA_WIDTH-1:0] rd_data,
output logic empty,
output logic almost_empty,
output logic [CNT_WIDTH-1:0] level
);
logic [DATA_WIDTH-1:0] mem [DEPTH];
logic [ADDR_WIDTH-1:0] wr_ptr;
logic [ADDR_WIDTH-1:0] rd_ptr;
logic [CNT_WIDTH-1:0] count;
logic [DATA_WIDTH-1:0] rd_data_q;
logic do_write;
logic do_read;
initial begin
assert ((DEPTH & (DEPTH - 1)) == 0)
else $fatal(1, "Sync FIFO DEPTH must be power of 2");
end
assign empty = (count == '0);
assign full = (count == DEPTH[CNT_WIDTH-1:0]);
assign almost_full = (count >= ALMOST_FULL_TH[CNT_WIDTH-1:0]);
assign almost_empty = (count <= ALMOST_EMPTY_TH[CNT_WIDTH-1:0]);
assign level = count;
assign do_read = rd_en && !empty;
assign do_write = wr_en && (!full || do_read);
generate
if (FWFT) begin : FWFT_READ
// First-Word Fall-Through:
// FIFO 非空时,rd_data 直接指向当前 head entry。
assign rd_data = mem[rd_ptr];
end else begin : REGISTERED_READ
// Non-FWFT:
// rd_en 被接受后,在时钟边沿把当前 head entry 捕获到 rd_data_q。
assign rd_data = rd_data_q;
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
rd_data_q <= '0;
end else if (do_read) begin
rd_data_q <= mem[rd_ptr];
end
end
end
endgenerate
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
wr_ptr <= '0;
end else if (do_write) begin
mem[wr_ptr] <= wr_data;
wr_ptr <= wr_ptr + 1'b1;
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
rd_ptr <= '0;
end else if (do_read) begin
rd_ptr <= rd_ptr + 1'b1;
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
count <= '0;
end else begin
unique case ({do_write, do_read})
2'b10: count <= count + 1'b1;
2'b01: count <= count - 1'b1;
default: count <= count;
endcase
end
end
endmodule
一个覆盖边界场景的同步 FIFO testbench 如下。该 testbench 同时实例化 FWFT = 1 和 FWFT = 0 两种配置,重点覆盖 reset、empty read、连续写满、full write blocking、full 状态 simultaneous read/write、almost flag、wrap-around、随机读写以及 FIFO ordering。
`timescale 1ns/1ps
module tb_sync_fifo;
localparam int DATA_WIDTH = 8;
localparam int DEPTH = 8;
localparam int ALMOST_FULL_TH = DEPTH - 2;
localparam int ALMOST_EMPTY_TH = 2;
localparam int CNT_WIDTH = $clog2(DEPTH + 1);
logic clk;
logic rst_n;
logic wr_en;
logic [DATA_WIDTH-1:0] wr_data;
logic rd_en;
logic [DATA_WIDTH-1:0] rd_data_fwft;
logic [DATA_WIDTH-1:0] rd_data_reg;
logic full_fwft;
logic almost_full_fwft;
logic empty_fwft;
logic almost_empty_fwft;
logic [CNT_WIDTH-1:0] level_fwft;
logic full_reg;
logic almost_full_reg;
logic empty_reg;
logic almost_empty_reg;
logic [CNT_WIDTH-1:0] level_reg;
logic [DATA_WIDTH-1:0] exp_q [$];
sync_fifo #(
.DATA_WIDTH(DATA_WIDTH),
.DEPTH(DEPTH),
.ALMOST_FULL_TH(ALMOST_FULL_TH),
.ALMOST_EMPTY_TH(ALMOST_EMPTY_TH),
.FWFT(1'b1)
) u_fifo_fwft (
.clk,
.rst_n,
.wr_en,
.wr_data,
.full(full_fwft),
.almost_full(almost_full_fwft),
.rd_en,
.rd_data(rd_data_fwft),
.empty(empty_fwft),
.almost_empty(almost_empty_fwft),
.level(level_fwft)
);
sync_fifo #(
.DATA_WIDTH(DATA_WIDTH),
.DEPTH(DEPTH),
.ALMOST_FULL_TH(ALMOST_FULL_TH),
.ALMOST_EMPTY_TH(ALMOST_EMPTY_TH),
.FWFT(1'b0)
) u_fifo_reg (
.clk,
.rst_n,
.wr_en,
.wr_data,
.full(full_reg),
.almost_full(almost_full_reg),
.rd_en,
.rd_data(rd_data_reg),
.empty(empty_reg),
.almost_empty(almost_empty_reg),
.level(level_reg)
);
initial clk = 1'b0;
always #5 clk = ~clk;
task automatic drive_idle();
@(negedge clk);
wr_en = 1'b0;
rd_en = 1'b0;
wr_data = '0;
endtask
task automatic push(input logic [DATA_WIDTH-1:0] data);
bit accept_wr;
@(negedge clk);
wr_en = 1'b1;
rd_en = 1'b0;
wr_data = data;
accept_wr = !full_fwft;
@(posedge clk);
#1;
if (accept_wr) begin
exp_q.push_back(data);
end
@(negedge clk);
wr_en = 1'b0;
endtask
task automatic pop(output logic [DATA_WIDTH-1:0] data);
logic [DATA_WIDTH-1:0] exp;
bit accept_rd;
@(negedge clk);
wr_en = 1'b0;
rd_en = 1'b1;
accept_rd = !empty_fwft;
if (accept_rd) begin
assert(rd_data_fwft == exp_q[0])
else $fatal("FWFT data mismatch before read: rd_data=%0h exp=%0h",
rd_data_fwft, exp_q[0]);
exp = exp_q.pop_front();
end
@(posedge clk);
#1;
if (accept_rd) begin
data = exp;
assert(rd_data_reg == exp)
else $fatal("Non-FWFT data mismatch: rd_data=%0h exp=%0h", rd_data_reg, exp);
end
@(negedge clk);
rd_en = 1'b0;
endtask
task automatic check_flags();
assert(full_fwft == full_reg);
assert(empty_fwft == empty_reg);
assert(almost_full_fwft == almost_full_reg);
assert(almost_empty_fwft == almost_empty_reg);
assert(level_fwft == level_reg);
assert(level_fwft == exp_q.size())
else $fatal("Level mismatch: level=%0d exp_size=%0d", level_fwft, exp_q.size());
assert(full_fwft == (exp_q.size() == DEPTH));
assert(empty_fwft == (exp_q.size() == 0));
assert(almost_full_fwft == (exp_q.size() >= ALMOST_FULL_TH));
assert(almost_empty_fwft == (exp_q.size() <= ALMOST_EMPTY_TH));
endtask
task automatic drive_fifo_cycle(
input bit want_wr,
input bit want_rd,
input logic [DATA_WIDTH-1:0] data_i
);
bit accept_wr;
bit accept_rd;
int occ_pre;
logic [DATA_WIDTH-1:0] exp;
@(negedge clk);
wr_en = want_wr;
rd_en = want_rd;
wr_data = data_i;
occ_pre = exp_q.size();
accept_rd = want_rd && (occ_pre > 0);
accept_wr = want_wr && ((occ_pre < DEPTH) || accept_rd);
if (accept_rd) begin
exp = exp_q[0];
assert(rd_data_fwft == exp)
else $fatal("FWFT data mismatch before read: got=%0h exp=%0h",
rd_data_fwft, exp);
end
@(posedge clk);
#1;
if (accept_rd) begin
exp = exp_q.pop_front();
assert(rd_data_reg == exp)
else $fatal("Non-FWFT data mismatch: got=%0h exp=%0h", rd_data_reg, exp);
end
if (accept_wr) begin
exp_q.push_back(data_i);
end
check_flags();
endtask
logic [DATA_WIDTH-1:0] data;
int perf_cycles;
int perf_wr_accept;
int perf_rd_accept;
int perf_full_stall;
int perf_empty_stall;
real perf_wr_throughput;
real perf_rd_throughput;
initial begin
rst_n = 1'b0;
wr_en = 1'b0;
rd_en = 1'b0;
wr_data = '0;
repeat (4) @(negedge clk);
rst_n = 1'b1;
repeat (2) @(negedge clk);
assert(empty_fwft == 1'b1);
assert(full_fwft == 1'b0);
check_flags();
// Empty read: state should not change.
@(negedge clk);
rd_en = 1'b1;
@(posedge clk);
#1;
assert(empty_fwft == 1'b1);
assert(level_fwft == '0);
@(negedge clk);
rd_en = 1'b0;
check_flags();
// Fill FIFO and check ordering / flags.
for (int i = 0; i < DEPTH; i++) begin
push(DATA_WIDTH'(i));
check_flags();
end
assert(full_fwft == 1'b1);
// Full write without read should be blocked.
@(negedge clk);
wr_en = 1'b1;
wr_data = 8'hff;
rd_en = 1'b0;
@(posedge clk);
#1;
assert(full_fwft == 1'b1);
assert(level_fwft == DEPTH[CNT_WIDTH-1:0]);
@(negedge clk);
wr_en = 1'b0;
check_flags();
// Simultaneous read/write when full: level remains DEPTH and ordering preserved.
@(negedge clk);
wr_en = 1'b1;
wr_data = 8'h80;
rd_en = 1'b1;
exp_q.pop_front();
exp_q.push_back(8'h80);
@(posedge clk);
#1;
assert(full_fwft == 1'b1);
assert(level_fwft == DEPTH[CNT_WIDTH-1:0]);
@(negedge clk);
wr_en = 1'b0;
rd_en = 1'b0;
check_flags();
// Drain all entries to exercise wrap-around.
while (exp_q.size() != 0) begin
pop(data);
check_flags();
end
assert(empty_fwft == 1'b1);
// Empty simultaneous read/write: only write should happen, no bypass read.
@(negedge clk);
wr_en = 1'b1;
wr_data = 8'ha5;
rd_en = 1'b1;
@(posedge clk);
#1;
exp_q.push_back(8'ha5);
assert(level_fwft == 1);
@(negedge clk);
wr_en = 1'b0;
rd_en = 1'b0;
check_flags();
pop(data);
assert(data == 8'ha5);
check_flags();
// Random traffic with explicit read-pressure bursts.
for (int i = 0; i < DEPTH; i++) begin
drive_fifo_cycle(1'b1, 1'b1, DATA_WIDTH'(8'hb0 + i));
end
while (exp_q.size() != 0) begin
drive_fifo_cycle(1'b0, 1'b1, '0);
end
for (int i = 0; i < DEPTH; i++) begin
drive_fifo_cycle(1'b1, 1'b0, DATA_WIDTH'(8'hc0 + i));
end
for (int i = 0; i < DEPTH; i++) begin
drive_fifo_cycle(1'b0, 1'b1, '0);
end
assert(empty_fwft == 1'b1);
for (int i = 0; i < 2; i++) begin
drive_fifo_cycle(1'b0, 1'b1, '0);
end
for (int i = 0; i < 200; i++) begin
bit want_wr;
bit want_rd;
want_rd = (i % 4 != 0);
if (exp_q.size() < ALMOST_EMPTY_TH) begin
want_wr = 1'b1;
end else begin
want_wr = $urandom_range(0, 1);
end
drive_fifo_cycle(want_wr, want_rd, DATA_WIDTH'($urandom()));
end
// Performance test: sustained simultaneous read/write.
// After prefill, wr_en and rd_en are asserted together to measure throughput.
perf_cycles = 1000;
perf_wr_accept = 0;
perf_rd_accept = 0;
perf_full_stall = 0;
perf_empty_stall = 0;
while (exp_q.size() < (DEPTH / 2)) begin
drive_fifo_cycle(1'b1, 1'b0, DATA_WIDTH'($urandom()));
end
for (int i = 0; i < perf_cycles; i++) begin
bit accept_wr;
bit accept_rd;
int occ_pre;
occ_pre = exp_q.size();
accept_rd = (occ_pre > 0);
accept_wr = (occ_pre < DEPTH) || accept_rd;
drive_fifo_cycle(1'b1, 1'b1, DATA_WIDTH'($urandom()));
if (accept_wr) perf_wr_accept++;
else perf_full_stall++;
if (accept_rd) perf_rd_accept++;
else perf_empty_stall++;
end
perf_wr_throughput = real'(perf_wr_accept) / real'(perf_cycles);
perf_rd_throughput = real'(perf_rd_accept) / real'(perf_cycles);
$display("tb_sync_fifo PERF: cycles=%0d wr_accept=%0d rd_accept=%0d wr_tput=%0.3f rd_tput=%0.3f full_stall=%0d empty_stall=%0d",
perf_cycles,
perf_wr_accept,
perf_rd_accept,
perf_wr_throughput,
perf_rd_throughput,
perf_full_stall,
perf_empty_stall);
drive_idle();
$display("tb_sync_fifo PASS");
$finish;
end
endmodule
上面的同步 FIFO testbench 可以分成三组测试场景。第一组是 directed case,用来覆盖 reset、空读、写满、满写阻塞、满状态同周期读写、连续读空和空状态同周期读写等确定性边界;第二组是 random case,用来在较长时间内随机组合 wr_en 和 rd_en,进一步检查 FIFO ordering、level 和各类 flag 是否始终一致;第三组是 performance case,用来在持续同周期读写场景下统计 accepted write / accepted read、吞吐率以及 full / empty stall 次数。
4.5.1 Directed Case:测试场景 1 ~ 7
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 1 | Reset 后空 FIFO 检查 | 复位释放后保持 wr_en = 0、rd_en = 0 |
empty_fwft = 1,full_fwft = 0,level_fwft = 0,FWFT 和 registered FIFO 的 flag 保持一致 |
| 2 | Empty read | FIFO 为空时拉高 rd_en |
不发生实际读出,empty_fwft 保持为 1,level_fwft 保持为 0 |
| 3 | Fill FIFO | 连续调用 push() 写入 0 ~ DEPTH-1 |
level_fwft 逐拍增加,写满后 full_fwft = 1,almost_full / almost_empty 按阈值变化 |
| 4 | Full write blocking | FIFO 满时单独拉高 wr_en,写入 8'hff |
写请求被阻塞,level_fwft 仍为 DEPTH,full_fwft 保持为 1,队列内容不被破坏 |
| 5 | Full simultaneous read/write | FIFO 满时同时拉高 wr_en 和 rd_en,写入 8'h80 |
本周期同时读出旧队头并写入新数据,level_fwft 保持 DEPTH,FIFO ordering 保持正确 |
| 6 | Drain to empty / wrap-around | 通过 while (exp_q.size() != 0) 连续调用 pop() |
数据按写入顺序读出,level_fwft 逐拍下降,最终 empty_fwft = 1,同时覆盖读指针回绕 |
| 7 | Empty simultaneous read/write | FIFO 为空时同时拉高 wr_en 和 rd_en,写入 8'ha5 |
只发生写入,不发生 bypass read,level_fwft = 1;后续 pop() 应读出 8'ha5 |
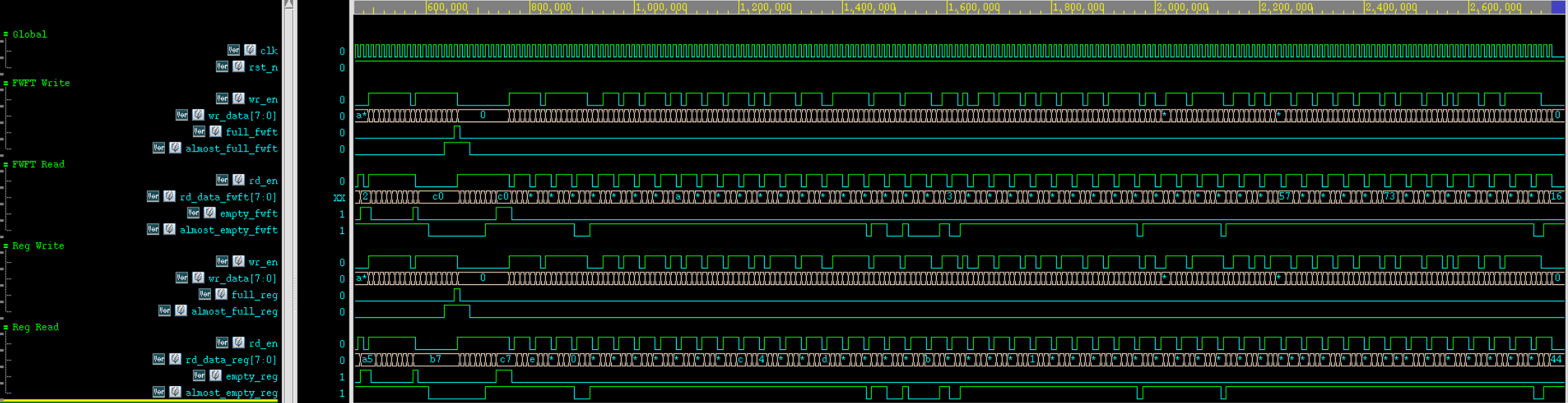
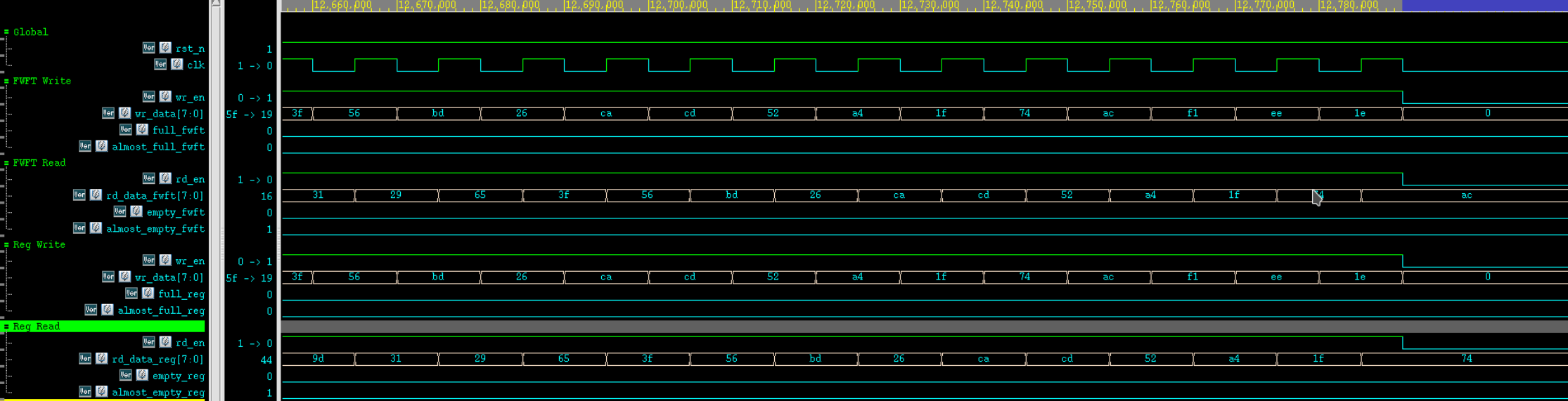
Verdi 仿真波形:

4.5.2 Random Case:测试场景 8
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 8 | Random traffic / 随机读写压力测试 | 连续 200 轮随机产生 want_wr 和 want_rd,并在每轮根据 FIFO 当前占用更新 scoreboard |
对所有被接受的读请求,FWFT FIFO 的 rd_data_fwft 和 registered FIFO 的 rd_data_reg 都应与期望队头一致;level_fwft 始终等于 exp_q.size(),full / empty / almost_full / almost_empty 与 scoreboard 一致 |
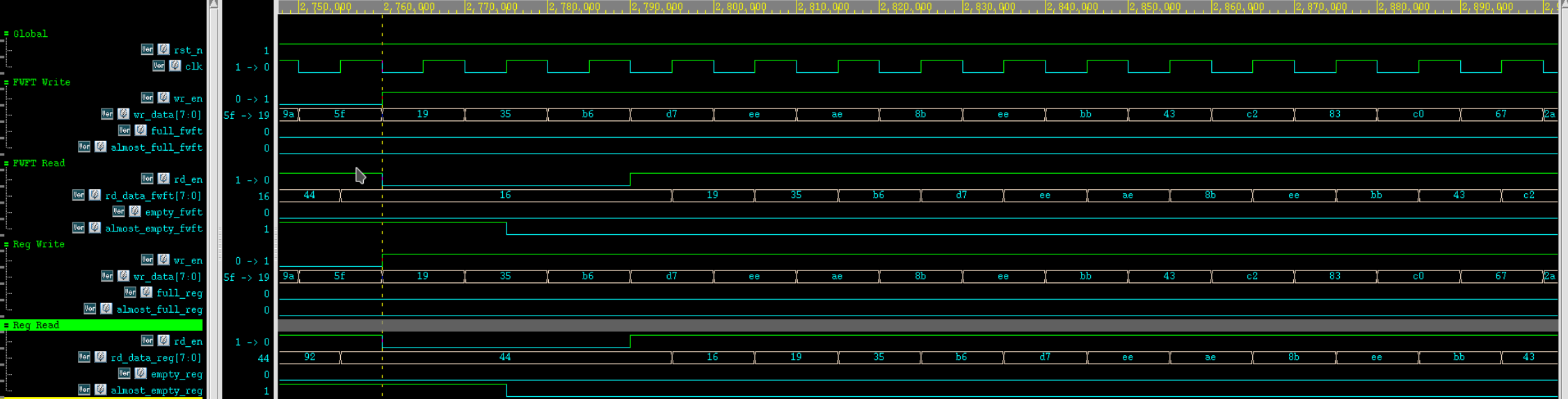
Verdi 仿真波形:
4.5.3 Performance Case:测试场景 9
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 9 | Sustained simultaneous read/write / 持续同周期读写性能统计 | 先通过 while (exp_q.size() < (DEPTH / 2)) 将 FIFO 预填充到半满,然后连续 perf_cycles = 1000 轮调用 drive_fifo_cycle(1'b1, 1'b1, DATA_WIDTH'($urandom())),同时统计 perf_wr_accept、perf_rd_accept、perf_full_stall 和 perf_empty_stall |
在半满稳定状态下,每轮同时请求 write 和 read;level_fwft、full / empty / almost_full / almost_empty 仍需与 scoreboard 一致;最终打印 wr_tput = perf_wr_accept / perf_cycles 和 rd_tput = perf_rd_accept / perf_cycles,用于观察持续读写场景下的吞吐率 |
Verdi 仿真波形:
这里的关键点是:
almost_full和almost_empty由当前count与阈值比较得到,用于提前反压或提前通知下游 FIFO 即将变空;FWFT用于选择读数据接口语义:FWFT = 1时,FIFO 非空后rd_data直接指向当前 head entry;FWFT = 0时,rd_en被接受后才把当前 head entry 注册到rd_data_q;do_read = rd_en && !empty,empty 时禁止 read;do_write = wr_en && (!full || do_read),表示 FIFO full 时如果同周期实际发生 read,可以允许 write;- 用
do_read而不是原始rd_en参与do_write判断,可以避免“读请求有效但实际未读”时错误放行写操作,表达也更接近真实握手语义; FWFT = 1时的rd_data = mem[rd_ptr]是组合读风格,适合 register array;- 如果底层使用 FPGA block RAM 或 ASIC SRAM,需要考虑 read latency、read enable 和 output register。
还需要明确该示例的空 FIFO 同周期读写语义:当 FIFO 为空且 wr_en 和 rd_en 同时有效时,do_write = 1、do_read = 0,也就是只写入新数据,不在同周期弹出该数据。换句话说,该实现不是 bypass FIFO;新写入的数据最早在后续周期被读取。FWFT 只决定 FIFO 已经非空时 rd_data 是否自动显示队头数据,并不改变 empty 状态下 read/write 同周期时是否允许 bypass。
下面用 WaveDrom 描述同步 FIFO 中几种典型边界行为:先连续写入直到 full,然后在 full 状态下同周期 read/write,此时 do_read 和 do_write 同时发生,level 保持不变;随后只读,level 下降。
{
signal: [
{ name: "clk", wave: "p..........." },
{ name: "rst_n", wave: "01.........." },
{ name: "wr_en", wave: "0.11111.0..." },
{ name: "rd_en", wave: "0.....1.11.." },
{ name: "do_write", wave: "0.11111.0..." },
{ name: "do_read", wave: "0.....1.11.." },
{ name: "level", wave: "x=.=.=.=.=.=.", data: ["0", "1", "2", "3", "4", "4", "3", "2"] },
{ name: "full", wave: "0....1.0...." },
{ name: "empty", wave: "10.........." }
],
head: {
text: "Sync FIFO: fill, full-cycle read+write, then drain"
}
}
empty 状态下同周期 read/write 的行为如下:由于 empty = 1,do_read = 0,所以该周期只接受写入,不会把新写入的数据直接作为 read data 消费。
{
signal: [
{ name: "clk", wave: "p......" },
{ name: "empty", wave: "1.0...." },
{ name: "wr_en", wave: "0.10..." },
{ name: "rd_en", wave: "0.10..." },
{ name: "do_write", wave: "0.10..." },
{ name: "do_read", wave: "0......" },
{ name: "level", wave: "x=.=...", data: ["0", "1"] },
{ name: "rd_data", wave: "x......" }
],
head: {
text: "Empty FIFO: simultaneous wr_en/rd_en only performs write"
}
}
上述 FWFT = 1 分支中的 rd_data = mem[rd_ptr] 更接近 register array 的组合读模型。真实工程中不同 memory 类型的读数据时序并不相同:
| 实现方式 | rd_data 行为 |
设计注意事项 |
|---|---|---|
| Register array + 组合读 | head entry 可组合可见 | 适合小深度 FIFO |
| FPGA block RAM | 通常同步读,读数据晚 1 拍 | 需要定义 rd_data_valid 或 prefetch |
| ASIC SRAM macro | 通常同步读,带 read enable / output register | 需要重新对齐 empty、rd_en 和 data valid |
| FWFT FIFO | empty 解除后 head data 已经有效 | pop 表示消费当前 head |
5 FIFO 状态判断:full / empty 与指针回绕
第 4 节的同步 FIFO 使用 count 来判断 full / empty,这是一种直观且适合教学的方式。工程中还经常使用带额外 wrap bit 的 pointer 比较法,尤其是异步 FIFO 中的 Gray pointer full/empty 判断,本节先把这个通用问题单独展开。
5.1 为什么 wr_ptr == rd_ptr 有歧义
在环形 FIFO 中,wr_ptr == rd_ptr 可能表示:
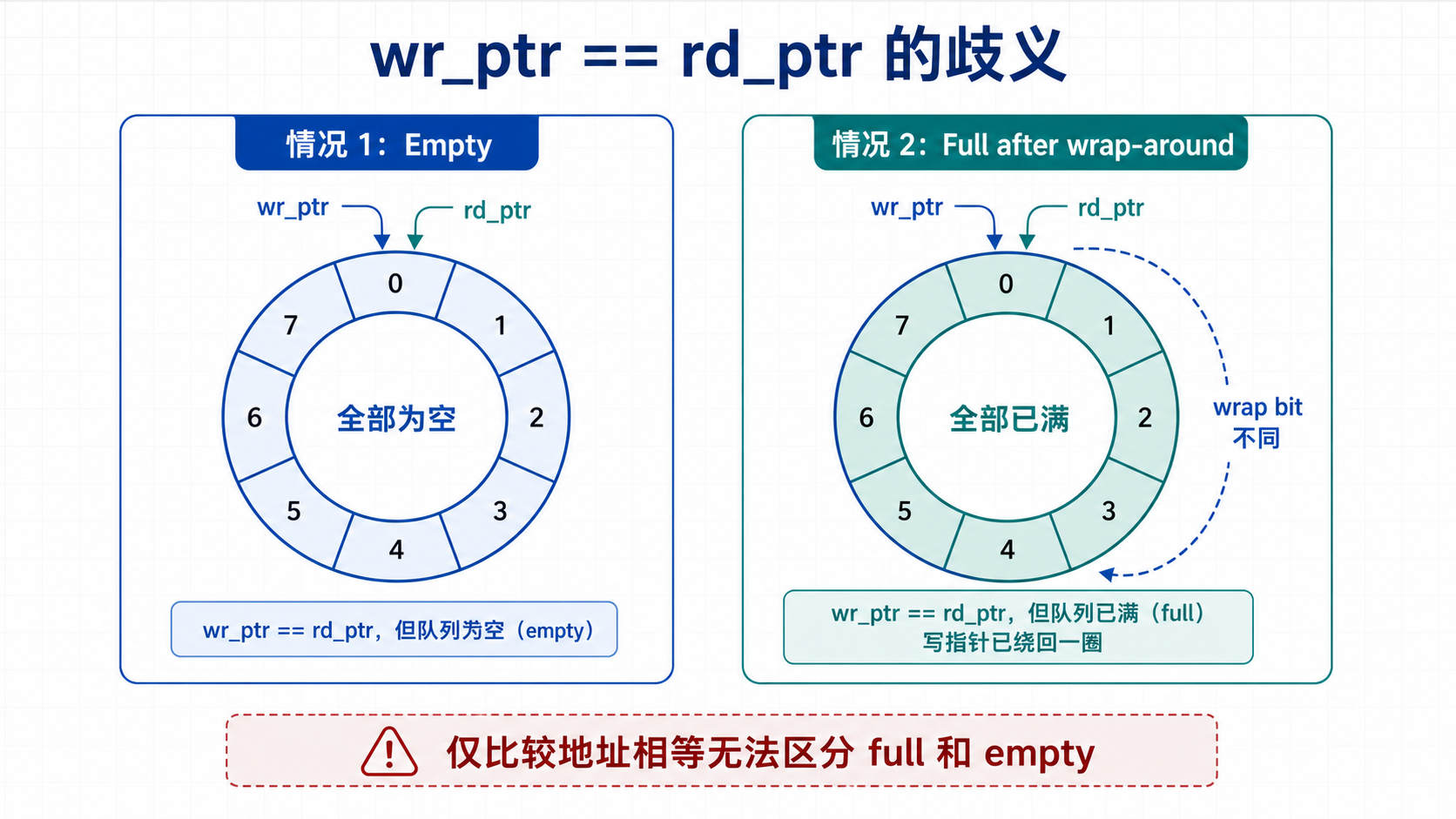
情况 1:FIFO empty
情况 2:FIFO full after wrap-around
因此需要额外信息区分 full 和 empty。常用方法包括:
- 使用 count;
- 指针增加额外 wrap bit;
- one-slot-empty;
- 异步 FIFO 中使用 Gray pointer。
5.2 pointer with extra bit
对深度为 2 的幂的 FIFO,可以让指针多一位。低位作为地址,高位作为 wrap bit。
DEPTH = 8
ADDR_WIDTH = 3
PTR_WIDTH = 4
判断方式:
assign empty = (wr_ptr == rd_ptr);
assign full = (wr_ptr[ADDR_WIDTH] != rd_ptr[ADDR_WIDTH]) &&
(wr_ptr[ADDR_WIDTH-1:0] == rd_ptr[ADDR_WIDTH-1:0]);
这种方法在同步 FIFO 和异步 FIFO 中都很常见。
6 FIFO 深度 sizing:从流量模型到工程取整
前面讨论的是“FIFO 如何正确工作”,本节讨论“FIFO 需要多深才够用”。深度 sizing 本质上是流量分析:在最坏窗口内,写入累计量和读出累计量之间的最大差值,就是 FIFO 需要吸收的 occupancy 峰值。
FIFO 深度 sizing 的核心问题是:在最坏情况下,FIFO 需要吸收多少尚未被下游消费的数据。换句话说,需要计算 FIFO occupancy 的最大值:

occupancy(t) = total_write(t) - total_read(t)
depth >= max(occupancy)
实际工程中,FIFO 深度通常不是只看平均吞吐率,而是看最坏 burst、下游 stall、仲裁延迟、CDC 反馈延迟和 backpressure 生效延迟。
6.1 通用计算方法
对任意一段时间窗口 T,假设:
W(T) = 该窗口内最多写入的数据个数
R(T) = 该窗口内最少读出的数据个数
则 FIFO 需要满足:
depth >= max_over_T { W(T) - R(T) }
如果系统支持 backpressure,还需要额外考虑从 FIFO 即将满到上游真正停止写入之间的延迟:
depth >= max_over_T { W(T) - R(T) } + backpressure_latency_write_count
其中:
backpressure_latency_write_count = write_rate * response_latency
6.2 写快读慢
如果写入速率为 W,读出速率为 R,burst 持续 B 个周期,并且 W > R,则 FIFO 至少需要:
depth >= (W - R) * B
例如:
write rate = 1 item/cycle
read rate = 0.5 item/cycle
burst length = 16 cycles
depth >= (1 - 0.5) * 16 = 8
如果上游看到 full 后还需要 2 个周期才能停止写入,则额外 margin 为:
extra = write_rate * response_latency
= 1 * 2
= 2
depth >= 8 + 2 = 10
工程实现时通常取 2 的幂:
depth = 16
6.3 下游 stall
如果上游持续写入,而下游最多 stall S 个周期,则在 stall 期间 FIFO 只进不出:
depth >= write_rate * S
例如:
write_rate = 1 item/cycle
max_stall = 12 cycles
depth >= 12
如果 full 反馈到上游需要 3 个周期才生效:
extra = 1 * 3 = 3
depth >= 12 + 3 = 15
工程上通常选择:
depth = 16
6.4 周期性速率不匹配
有些接口的平均速率相同,但局部速率不同。例如上游每 4 个周期连续写 4 个数据,下游每 4 个周期均匀读 4 个数据。虽然平均速率都是 1 item/cycle,但瞬时 occupancy 可能增加。
计算时应列出每个 cycle 的写读情况:
| cycle | write | read | occupancy |
|---|---|---|---|
| 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 2 |
| 2 | 1 | 0 | 3 |
| 3 | 1 | 0 | 4 |
| 4 | 0 | 1 | 3 |
| 5 | 0 | 1 | 2 |
| 6 | 0 | 1 | 1 |
| 7 | 0 | 1 | 0 |
因此:
depth >= max occupancy = 4
这个例子说明:平均带宽相等不代表 FIFO 深度可以为 1,还必须考虑 burst pattern。
6.5 总线仲裁延迟
如果 FIFO 的读侧需要等待仲裁,例如多个 master 共享一个 downstream port,则读侧可能在最坏情况下等待 A 个周期才获得服务。
假设:
write_rate = W item/cycle
arb_latency = A cycles
则至少需要:
depth >= W * A
如果获得仲裁后读侧带宽仍低于写侧,还需要叠加后续速率差:
depth >= W * A + (W - R) * B
6.6 异步 FIFO 深度计算
异步 FIFO 除了速率差异,还要考虑 CDC 反馈延迟。由于 full 依赖同步到写时钟域的读指针,empty 依赖同步到读时钟域的写指针,因此 full/empty 的感知天然滞后。
常用估算公式:
depth >= burst_accumulation + cdc_feedback_margin
其中:
burst_accumulation = max_write_accumulation - min_read_drain
而:
cdc_feedback_margin =
synchronizer_latency
+ pointer_compare_latency
+ upstream_response_latency
注意这里的 latency 需要换算成写侧可能继续写入的数据个数:
cdc_feedback_margin_items = write_rate * feedback_latency_in_wr_clk
例如:
wr_clk = 200 MHz
rd_clk = 100 MHz
write_rate = 1 item/wr_clk
read_rate = 1 item/rd_clk
write burst = 32 wr_clk cycles
在 32 个写时钟周期内,读时钟只走了约 16 个周期,因此:
write_count = 32
read_count = 16
burst_accumulation = 32 - 16 = 16
如果读指针同步到写时钟域需要 2 拍,上游响应 full 需要 2 拍:
feedback_latency = 2 + 2 = 4 wr_clk cycles
cdc_feedback_margin_items = 1 * 4 = 4
depth >= 16 + 4 = 20
工程实现中通常取 2 的幂:
depth = 32
6.7 深度取整规则
计算得到理论最小深度后,还需要进行工程取整:
depth_final = next_power_of_2(depth_required + safety_margin)
对同步 FIFO,不一定必须是 2 的幂,但 2 的幂可以简化指针回绕。对异步 FIFO,强烈建议使用 2 的幂,因为 Gray pointer full/empty 判断依赖标准二进制递增和 wrap bit。
例如:
depth_required = 20
safety_margin = 4
depth_final = next_power_of_2(24) = 32
6.8 FIFO 深度计算 checklist
[ ] 最大连续 burst 长度是多少?
[ ] burst 内 write rate 是多少?
[ ] burst 内 read rate 是多少?
[ ] 下游最大 stall 周期是多少?
[ ] 是否存在仲裁等待?最长等待多少周期?
[ ] full/backpressure 到上游停止写入有多少周期?
[ ] async FIFO 是否包含 pointer synchronizer 延迟?
[ ] reset 或 clock gating 后是否会出现短时间读写不平衡?
[ ] 是否需要 almost_full 提前反压?
[ ] 最终深度是否取 2 的幂?
6.9 深度选择建议
| 场景 | 推荐深度 |
|---|---|
| 简单 pipeline 解耦 | 2 ~ 4 |
| ready/valid 普通缓冲 | 4 ~ 8 |
| burst absorption | 8 ~ 64 |
| bus bridge / DMA | 16 ~ 256 |
| CDC FIFO | 通常 8 起步,按速率和 CDC latency 计算 |
| SRAM-based FIFO | 64 以上更常见 |
7 FIFO 读数据语义:Peek、Non-Peek 与 FWFT
在掌握普通 push/pop FIFO 后,还需要明确读数据什么时候可见,以及“查看队头”和“弹出队头”是否是同一个动作。Peek FIFO、Non-Peek FIFO 和 FWFT FIFO 的主要差异就在这里。
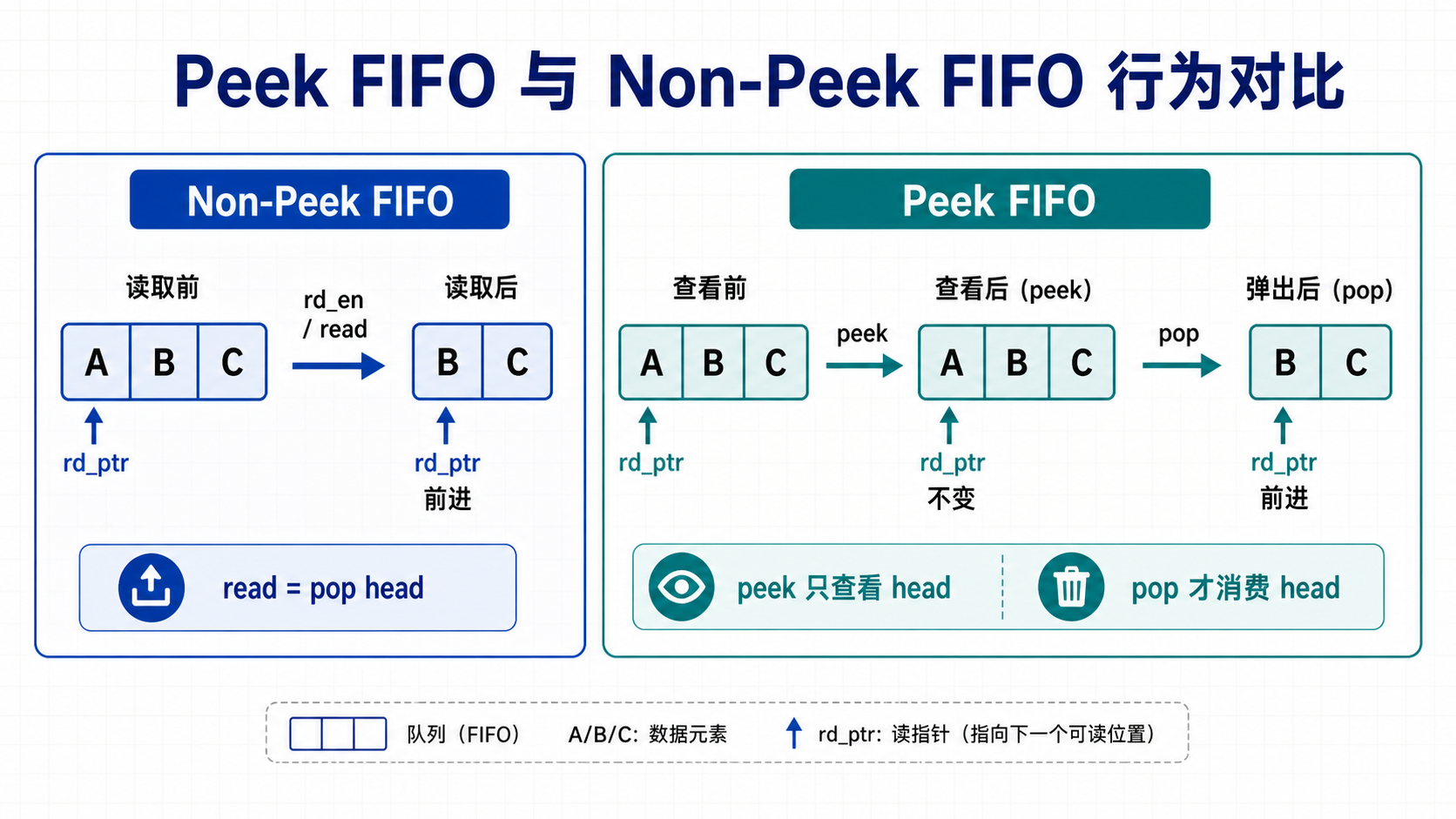
7.1 Non-Peek FIFO
Non-Peek FIFO 是普通 FIFO。一次 read 操作即表示消费当前 head entry,并移动读指针。
rd_en asserted -> pop head -> rd_ptr advance
适用于 streaming data、bus response queue、普通 pipeline buffer。
7.2 Peek FIFO
Peek FIFO 支持查看队头数据但不弹出。只有 pop 才会真正移动读指针。
peek: 查看 head data,FIFO 状态不变
pop : 消费 head data,rd_ptr 前进
典型应用包括:
- packet header inspection;
- command queue;
- reorder buffer;
- arbitration;
- protocol parser。
7.3 FWFT FIFO 与 Peek FIFO
Peek FIFO、普通 FIFO 和 FWFT FIFO 容易混淆。它们的主要区别在于 head data 是否自动可见,以及 read/pop 的语义是什么:
| 类型 | 队头数据是否自动可见 | read / pop 含义 | 典型实现 |
|---|---|---|---|
| 普通同步读 FIFO | 通常不可立即可见 | read 是一次读请求,数据下一拍或若干拍返回 | SRAM / BRAM 同步读 |
| FWFT FIFO | FIFO 非空后 head data 自动可见 | pop 表示消费当前 head | prefetch register 或组合读 |
| Peek FIFO | peek 可查看 head,pop 才消费 | peek 不改变状态,pop 移动读指针 | command queue、parser queue |
本文中的 peek_data = mem[rd_ptr] 属于教学用组合读模型,更接近“head data 始终可见”的接口风格;若底层 memory 是同步读 SRAM,则需要通过预取寄存器把同步读延迟隐藏起来。
下面的 WaveDrom 展示 peek 与 pop 的区别:连续 peek_en 不会移动 rd_ptr,因此 peek_data 保持为队头数据;只有 pop_en 有效且 FIFO 非空时,do_pop 才会发生,随后 peek_data 指向下一个队头 entry。
{
signal: [
{ name: "clk", wave: "p........." },
{ name: "empty", wave: "0........." },
{ name: "peek_en", wave: "0.111.1..." },
{ name: "pop_en", wave: "0....10..." },
{ name: "do_pop", wave: "0....10..." },
{ name: "rd_ptr", wave: "x=...=....", data: ["0", "1"] },
{ name: "peek_valid", wave: "0.111.1..." },
{ name: "peek_data", wave: "x=...=....", data: ["A0", "A1"] }
],
head: {
text: "Peek FIFO: peek keeps head stable, pop advances head"
}
}
7.4 Peek FIFO RTL
下面的 Peek FIFO 始终输出当前 head entry。peek_data 在 empty == 0 时有效,pop_en 才会移动读指针。
module peek_fifo #(
parameter int DATA_WIDTH = 32,
parameter int DEPTH = 16,
localparam int ADDR_WIDTH = $clog2(DEPTH),
localparam int CNT_WIDTH = $clog2(DEPTH + 1)
) (
input logic clk,
input logic rst_n,
input logic push_en,
input logic [DATA_WIDTH-1:0] push_data,
output logic full,
input logic pop_en,
output logic [DATA_WIDTH-1:0] peek_data,
output logic peek_valid,
output logic empty,
output logic [CNT_WIDTH-1:0] level
);
logic [DATA_WIDTH-1:0] mem [DEPTH];
logic [ADDR_WIDTH-1:0] wr_ptr;
logic [ADDR_WIDTH-1:0] rd_ptr;
logic [CNT_WIDTH-1:0] count;
logic do_push;
logic do_pop;
initial begin
assert ((DEPTH & (DEPTH - 1)) == 0)
else $fatal(1, "Peek FIFO DEPTH must be power of 2");
end
assign empty = (count == '0);
assign full = (count == DEPTH[CNT_WIDTH-1:0]);
assign level = count;
assign peek_valid = !empty;
assign peek_data = mem[rd_ptr];
assign do_pop = pop_en && !empty;
assign do_push = push_en && (!full || do_pop);
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
wr_ptr <= '0;
end else if (do_push) begin
mem[wr_ptr] <= push_data;
wr_ptr <= wr_ptr + 1'b1;
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
rd_ptr <= '0;
end else if (do_pop) begin
rd_ptr <= rd_ptr + 1'b1;
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
count <= '0;
end else begin
unique case ({do_push, do_pop})
2'b10: count <= count + 1'b1;
2'b01: count <= count - 1'b1;
default: count <= count;
endcase
end
end
endmodule
一个覆盖 peek / pop 边界行为的 Peek FIFO testbench 如下。该 testbench 重点覆盖 reset、empty peek、empty pop、连续 peek 不改变队头、peek 后 pop、写满、full 状态 simultaneous push/pop、wrap-around、随机 push/pop 以及 FIFO ordering。
module tb_peek_fifo;
localparam int DATA_WIDTH = 8;
localparam int DEPTH = 8;
localparam int CNT_WIDTH = $clog2(DEPTH + 1);
logic clk;
logic rst_n;
logic push_en;
logic [DATA_WIDTH-1:0] push_data;
logic full;
logic pop_en;
logic [DATA_WIDTH-1:0] peek_data;
logic peek_valid;
logic empty;
logic [CNT_WIDTH-1:0] level;
logic [DATA_WIDTH-1:0] exp_q [$];
peek_fifo #(
.DATA_WIDTH(DATA_WIDTH),
.DEPTH(DEPTH)
) dut (
.clk,
.rst_n,
.push_en,
.push_data,
.full,
.pop_en,
.peek_data,
.peek_valid,
.empty,
.level
);
initial clk = 1'b0;
always #5 clk = ~clk;
task automatic check_state();
assert(level == exp_q.size())
else $fatal("Peek FIFO level mismatch: level=%0d exp_size=%0d", level, exp_q.size());
assert(empty == (exp_q.size() == 0));
assert(full == (exp_q.size() == DEPTH));
assert(peek_valid == !empty);
if (exp_q.size() > 0) begin
assert(peek_data == exp_q[0])
else $fatal("Peek data mismatch: peek_data=%0h exp=%0h", peek_data, exp_q[0]);
end
endtask
task automatic push(input logic [DATA_WIDTH-1:0] data);
@(negedge clk);
push_en = 1'b1;
pop_en = 1'b0;
push_data = data;
@(posedge clk);
#1;
if (exp_q.size() < DEPTH) begin
exp_q.push_back(data);
end
@(negedge clk);
push_en = 1'b0;
check_state();
endtask
task automatic pop(output logic [DATA_WIDTH-1:0] data);
logic [DATA_WIDTH-1:0] exp;
@(negedge clk);
push_en = 1'b0;
pop_en = 1'b1;
if (exp_q.size() > 0) begin
exp = exp_q.pop_front();
data = exp;
end
@(posedge clk);
#1;
@(negedge clk);
pop_en = 1'b0;
check_state();
endtask
logic [DATA_WIDTH-1:0] data;
int perf_cycles;
int perf_push_accept;
int perf_pop_accept;
int perf_full_stall;
int perf_empty_stall;
real perf_push_throughput;
real perf_pop_throughput;
initial begin
rst_n = 1'b0;
push_en = 1'b0;
push_data = '0;
pop_en = 1'b0;
repeat (4) @(negedge clk);
rst_n = 1'b1;
repeat (2) @(negedge clk);
assert(empty == 1'b1);
assert(full == 1'b0);
assert(peek_valid == 1'b0);
check_state();
// Empty pop should not change state.
@(negedge clk);
pop_en = 1'b1;
@(posedge clk);
#1;
assert(empty == 1'b1);
@(negedge clk);
pop_en = 1'b0;
check_state();
// Empty peek is represented by peek_valid=0.
assert(peek_valid == 1'b0);
// Push two entries and verify continuous peek does not pop.
push(8'h11);
push(8'h22);
repeat (5) begin
@(posedge clk);
#1;
assert(peek_valid == 1'b1);
assert(peek_data == 8'h11);
assert(level == 2);
end
// Pop after peek, then next head should appear.
pop(data);
assert(data == 8'h11);
assert(peek_data == 8'h22);
pop(data);
assert(data == 8'h22);
assert(empty == 1'b1);
// Fill FIFO.
for (int i = 0; i < DEPTH; i++) begin
push(DATA_WIDTH'(8'h40 + i));
end
assert(full == 1'b1);
assert(peek_data == 8'h40);
// Full push without pop should be blocked.
@(negedge clk);
push_en = 1'b1;
push_data = 8'hff;
pop_en = 1'b0;
@(posedge clk);
#1;
assert(full == 1'b1);
assert(level == DEPTH[CNT_WIDTH-1:0]);
@(negedge clk);
push_en = 1'b0;
check_state();
// Full simultaneous push/pop should preserve level and ordering.
@(negedge clk);
push_en = 1'b1;
push_data = 8'ha5;
pop_en = 1'b1;
exp_q.pop_front();
exp_q.push_back(8'ha5);
@(posedge clk);
#1;
assert(full == 1'b1);
assert(level == DEPTH[CNT_WIDTH-1:0]);
@(negedge clk);
push_en = 1'b0;
pop_en = 1'b0;
check_state();
// Drain to exercise wrap-around.
while (exp_q.size() != 0) begin
pop(data);
end
assert(empty == 1'b1);
// Random push/pop.
for (int i = 0; i < 200; i++) begin
bit want_push;
bit want_pop;
bit accept_push;
bit accept_pop;
int occ_pre;
logic [DATA_WIDTH-1:0] rand_data;
want_push = $urandom_range(0, 1);
want_pop = $urandom_range(0, 1);
rand_data = DATA_WIDTH'($urandom());
occ_pre = exp_q.size();
accept_pop = want_pop && (occ_pre > 0);
accept_push = want_push && ((occ_pre < DEPTH) || accept_pop);
@(negedge clk);
push_en = want_push;
push_data = rand_data;
pop_en = want_pop;
if (accept_pop) begin
exp_q.pop_front();
end
if (accept_push) begin
exp_q.push_back(rand_data);
end
@(posedge clk);
#1;
check_state();
end
@(negedge clk);
push_en = 1'b0;
pop_en = 1'b0;
// Performance test: sustained simultaneous push/pop.
// After prefill, push_en and pop_en are asserted together to measure throughput.
perf_cycles = 1000;
perf_push_accept = 0;
perf_pop_accept = 0;
perf_full_stall = 0;
perf_empty_stall = 0;
while (exp_q.size() > (DEPTH / 2)) begin
pop(data);
end
while (exp_q.size() < (DEPTH / 2)) begin
push(DATA_WIDTH'($urandom()));
end
for (int i = 0; i < perf_cycles; i++) begin
bit accept_push;
bit accept_pop;
int occ_pre;
logic [DATA_WIDTH-1:0] rand_data;
occ_pre = exp_q.size();
accept_pop = (occ_pre > 0);
accept_push = (occ_pre < DEPTH) || accept_pop;
rand_data = DATA_WIDTH'($urandom());
@(negedge clk);
push_en = 1'b1;
push_data = rand_data;
pop_en = 1'b1;
if (accept_pop) begin
exp_q.pop_front();
perf_pop_accept++;
end else begin
perf_empty_stall++;
end
if (accept_push) begin
exp_q.push_back(rand_data);
perf_push_accept++;
end else begin
perf_full_stall++;
end
@(posedge clk);
#1;
check_state();
end
@(negedge clk);
push_en = 1'b0;
pop_en = 1'b0;
perf_push_throughput = real'(perf_push_accept) / real'(perf_cycles);
perf_pop_throughput = real'(perf_pop_accept) / real'(perf_cycles);
$display("tb_peek_fifo PERF: cycles=%0d push_accept=%0d pop_accept=%0d push_tput=%0.3f pop_tput=%0.3f full_stall=%0d empty_stall=%0d",
perf_cycles,
perf_push_accept,
perf_pop_accept,
perf_push_throughput,
perf_pop_throughput,
perf_full_stall,
perf_empty_stall);
$display("tb_peek_fifo PASS");
$finish;
end
endmodule
上面的 Peek FIFO testbench 可以分成三组测试场景。第一组是 directed case,用来覆盖 reset、empty pop、empty peek、连续 peek、peek 后 pop、写满、满状态 push blocking、满状态同周期 push/pop、drain 到空以及 wrap-around;第二组是 random case,用来随机组合 push_en 和 pop_en 并检查 FIFO ordering、level、empty、full、peek_valid 和 peek_data;第三组是 performance case,用来在持续同周期 push/pop 场景下统计 accepted push / accepted pop、吞吐率以及 full / empty stall 次数。
7.4.1 Directed Case:测试场景 1 ~ 9
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 1 | Reset 后空 FIFO 检查 | 复位释放后保持 push_en = 0、pop_en = 0 |
empty = 1,full = 0,peek_valid = 0,level = 0,scoreboard 为空 |
| 2 | Empty pop | FIFO 为空时拉高 pop_en |
不发生实际 pop,empty 保持为 1,scoreboard 和 level 不变 |
| 3 | Empty peek | FIFO 为空时检查 peek_valid |
peek_valid = 0,表示当前没有可 peek 的队头数据 |
| 4 | Continuous peek does not pop | 连续 push(8'h11)、push(8'h22) 后,连续 5 个周期只观察 peek_valid / peek_data,不拉高 pop_en |
peek_valid = 1,peek_data 持续等于 8'h11,level = 2,说明 peek 不改变队头和读指针 |
| 5 | Pop after peek | 在连续 peek 后调用两次 pop(data) |
第一次 pop 得到 8'h11,随后 peek_data 变为 8'h22;第二次 pop 得到 8'h22,最终 empty = 1 |
| 6 | Fill FIFO | 连续调用 push() 写入 8'h40 ~ 8'h40 + DEPTH - 1 |
FIFO 写满后 full = 1,level = DEPTH,peek_data 仍指向队头 8'h40 |
| 7 | Full push blocking | FIFO 满时单独拉高 push_en,写入 8'hff,pop_en = 0 |
push 被阻塞,full 保持为 1,level 保持为 DEPTH,scoreboard 内容不被破坏 |
| 8 | Full simultaneous push/pop | FIFO 满时同时拉高 push_en 和 pop_en,写入 8'ha5 |
同周期 pop 旧队头并 push 新数据,full 保持为 1,level 保持为 DEPTH,scoreboard 顺序更新为弹出旧队头并追加 8'ha5 |
| 9 | Drain to empty / wrap-around | 通过 while (exp_q.size() != 0) 连续调用 pop(data) |
所有数据被按 FIFO 顺序弹出,最终 empty = 1,同时覆盖读写指针回绕后的状态一致性 |
下图为 Peek FIFO directed case 1 ~ 9 的仿真波形,覆盖 reset、empty pop、empty peek、连续 peek、peek 后 pop、写满、满状态 push blocking、满状态同周期 push/pop,以及 drain 到空 / wrap-around。重点观察 peek_valid、peek_data、level、full 和 empty 是否始终与 scoreboard 状态一致。

7.4.2 Random Case:测试场景 10
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 10 | Random push/pop / 随机 push-pop 压力测试 | 连续 200 轮随机产生 want_push 和 want_pop,每轮根据当前 scoreboard 更新期望队列 |
level 始终等于 exp_q.size();empty、full、peek_valid 与 scoreboard 一致;当队列非空时,peek_data 始终等于当前期望队头 |
下图为 Peek FIFO random case 10 的仿真波形。该阶段随机组合 push_en 和 pop_en,并在每个周期根据 accepted push / accepted pop 更新 scoreboard,用来检查随机流量下 peek_data 是否始终指向当前队头、level 是否与期望队列长度一致。

7.4.3 Performance Case:测试场景 11
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 11 | Sustained simultaneous push/pop / 持续同周期 push-pop 性能统计 | 先根据 case10 结束后的 FIFO occupancy 做归一化:如果高于半满则连续 pop() drain 到半满,如果低于半满则连续 push() 预填充到半满;随后连续 perf_cycles = 1000 轮保持 push_en = 1、pop_en = 1,并统计 perf_push_accept、perf_pop_accept、perf_full_stall 和 perf_empty_stall |
performance 主循环从半满稳定状态开始;每轮后 check_state() 仍通过;最终打印 push_tput = perf_push_accept / perf_cycles 和 pop_tput = perf_pop_accept / perf_cycles,用于观察持续 push/pop 场景下的吞吐率 |
下图为 Peek FIFO performance case 11 的起始阶段仿真波形。测试先将 FIFO 预填充到半满,然后进入持续同周期 push/pop,用于观察稳定状态下 level 基本保持不变、peek_data 随 pop 推进到下一队头。

下图为 Peek FIFO performance case 11 的结束阶段仿真波形,结尾处统计 perf_push_accept、perf_pop_accept、perf_full_stall、perf_empty_stall,并打印持续 push/pop 场景下的吞吐率。

验证 Peek FIFO 时需要重点检查:
peek_valid && !pop_en -> rd_ptr stable
pop_en && !empty -> rd_ptr advance
peek_data -> always points to current head
如果底层 memory 是同步读 SRAM,则 peek_data 可能不是组合可见,需要增加 prefetch 或 output register。此时 peek_valid 不应简单理解为 !empty,而应和 SRAM read latency 对齐;常见做法是在 FIFO 内部维护一个 head prefetch register,使外部仍然看到类似 FWFT 的接口。
8 异步 FIFO 与 CDC:跨时钟域的基本模型
异步 FIFO 是 FIFO 设计中最经典的 CDC 场景。和同步 FIFO 相比,它的数据仍然通过 memory 传输,但读写指针属于不同的时钟域,因此必须用 Gray pointer 和 synchronizer 来传递“对方指针的位置”。
异步 FIFO 用于跨时钟域传输数据。其核心思想是:
- 数据通过 dual-port memory 传输;
- 写指针在写时钟域维护;
- 读指针在读时钟域维护;
- pointer 通过 Gray code 跨域同步;
- full 在写时钟域生成;
- empty 在读时钟域生成。
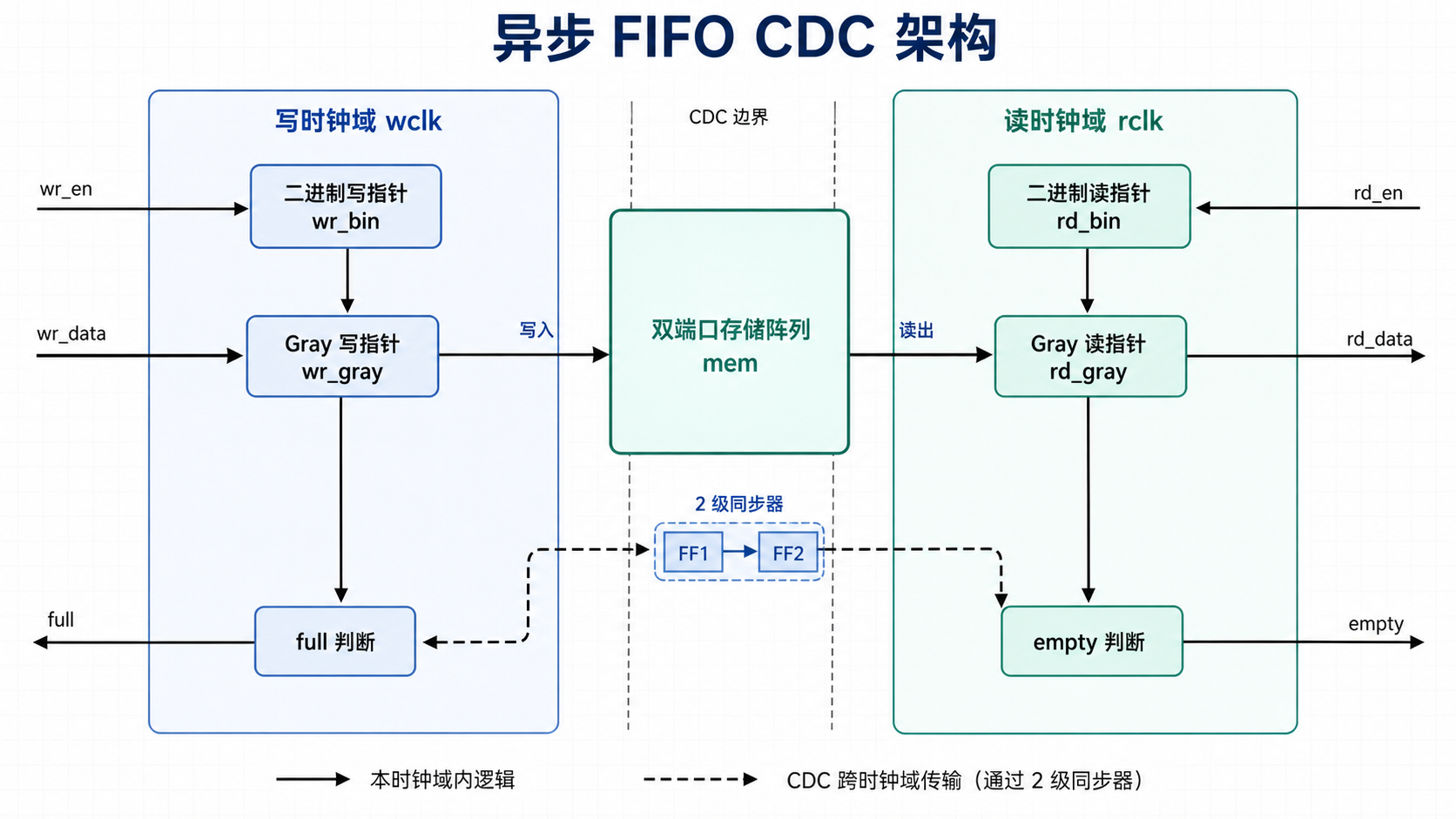
8.1 为什么使用 Gray code
二进制指针递增时可能多个 bit 同时翻转,例如:
0111 -> 1000
如果直接跨时钟域同步,接收端可能采到非法中间状态。Gray code 每次递增只变化 1 bit,因此适合跨时钟域同步。
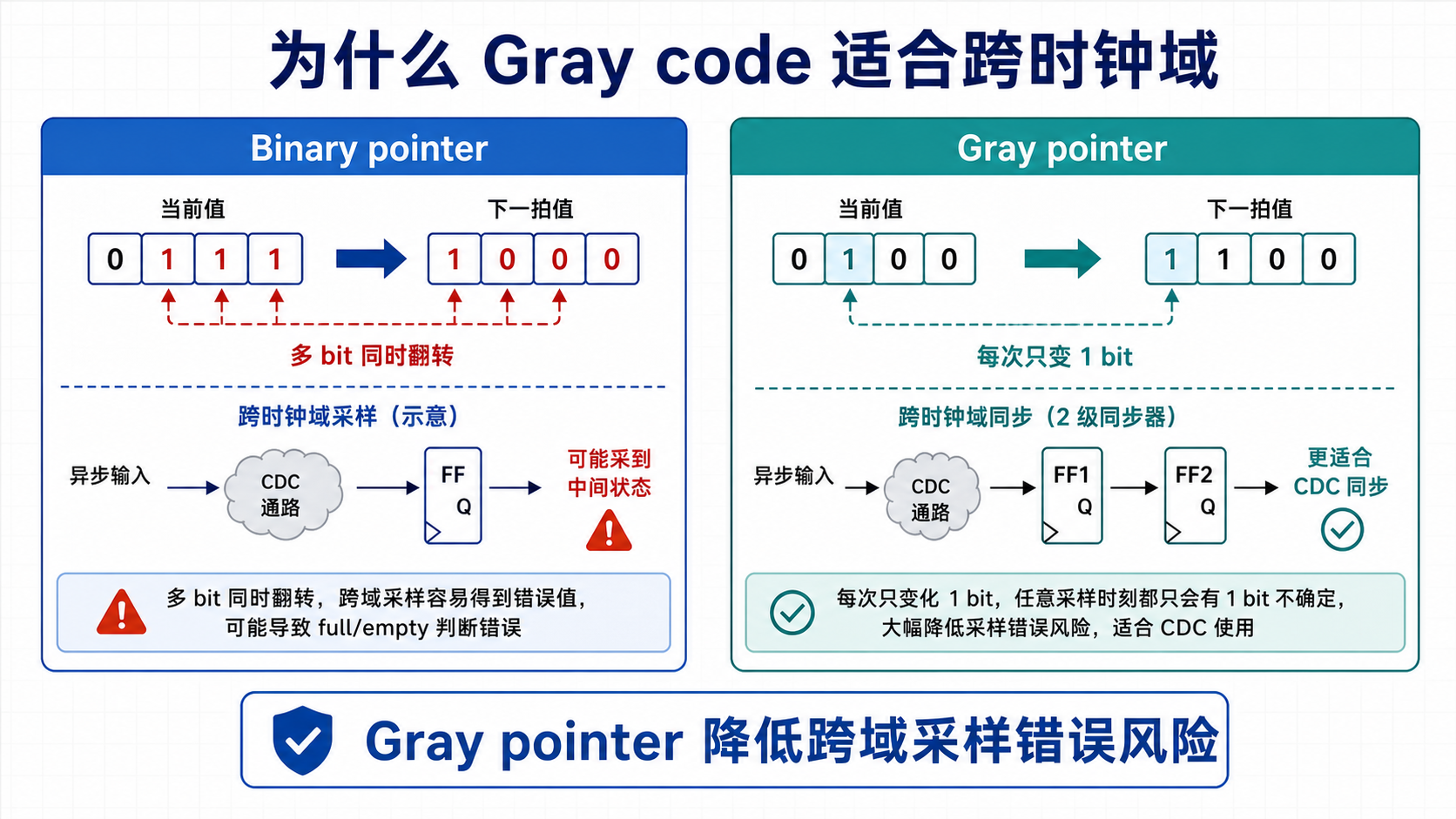
8.2 Binary 与 Gray 转换
function automatic logic [PTR_WIDTH-1:0] bin2gray(
input logic [PTR_WIDTH-1:0] bin
);
return (bin >> 1) ^ bin;
endfunction
9 异步 FIFO RTL:Gray Pointer、同步器与边界状态
下面给出一个经典异步 FIFO 的 SystemVerilog 实现。为了简化指针和 Gray code 判断,DEPTH 应取 2 的幂。
异步 FIFO 中这个限制比同步 FIFO 更重要:标准 Gray pointer full/empty 判断依赖二进制指针按 2 的幂空间自然回绕。如果 DEPTH 不是 2 的幂,Gray pointer 序列不再只覆盖一个完整的 2^N 环,跨域同步和 full/empty 判断都需要重新设计。因此工程上通常要求 async FIFO depth 固定为 2 的幂,并在 elaboration 阶段用 assertion 检查:
initial begin
assert ((DEPTH & (DEPTH - 1)) == 0)
else $fatal(1, "Async FIFO DEPTH must be power of 2");
end
module async_fifo #(
parameter int DATA_WIDTH = 32,
parameter int DEPTH = 16,
localparam int ADDR_WIDTH = $clog2(DEPTH),
localparam int PTR_WIDTH = ADDR_WIDTH + 1
) (
input logic wr_clk,
input logic wr_rst_n,
input logic wr_en,
input logic [DATA_WIDTH-1:0] wr_data,
output logic full,
input logic rd_clk,
input logic rd_rst_n,
input logic rd_en,
output logic [DATA_WIDTH-1:0] rd_data,
output logic empty,
output logic overflow_error,
output logic underflow_error
);
logic [DATA_WIDTH-1:0] mem [DEPTH];
logic [PTR_WIDTH-1:0] wr_ptr_bin;
logic [PTR_WIDTH-1:0] wr_ptr_bin_next;
logic [PTR_WIDTH-1:0] wr_ptr_gray;
logic [PTR_WIDTH-1:0] wr_ptr_gray_next;
logic [PTR_WIDTH-1:0] rd_ptr_bin;
logic [PTR_WIDTH-1:0] rd_ptr_bin_next;
logic [PTR_WIDTH-1:0] rd_ptr_gray;
logic [PTR_WIDTH-1:0] rd_ptr_gray_next;
logic [PTR_WIDTH-1:0] wr_ptr_gray_rdclk_q1;
logic [PTR_WIDTH-1:0] wr_ptr_gray_rdclk_q2;
logic [PTR_WIDTH-1:0] rd_ptr_gray_wrclk_q1;
logic [PTR_WIDTH-1:0] rd_ptr_gray_wrclk_q2;
logic do_write;
logic do_read;
logic wr_overflow;
logic rd_underflow;
initial begin
assert ((DEPTH & (DEPTH - 1)) == 0)
else $fatal(1, "Async FIFO DEPTH must be power of 2");
end
function automatic logic [PTR_WIDTH-1:0] bin2gray(
input logic [PTR_WIDTH-1:0] bin
);
return (bin >> 1) ^ bin;
endfunction
assign do_write = wr_en && !full;
assign do_read = rd_en && !empty;
assign wr_ptr_bin_next = wr_ptr_bin + , do_write};
assign wr_ptr_gray_next = bin2gray(wr_ptr_bin_next);
assign rd_ptr_bin_next = rd_ptr_bin + , do_read};
assign rd_ptr_gray_next = bin2gray(rd_ptr_bin_next);
assign rd_data = mem[rd_ptr_bin[ADDR_WIDTH-1:0]];
always_ff @(posedge wr_clk or negedge wr_rst_n) begin
if (!wr_rst_n) begin
wr_ptr_bin <= '0;
wr_ptr_gray <= '0;
end else begin
wr_ptr_bin <= wr_ptr_bin_next;
wr_ptr_gray <= wr_ptr_gray_next;
end
end
always_ff @(posedge wr_clk) begin
if (do_write) begin
mem[wr_ptr_bin[ADDR_WIDTH-1:0]] <= wr_data;
end
end
always_ff @(posedge rd_clk or negedge rd_rst_n) begin
if (!rd_rst_n) begin
rd_ptr_bin <= '0;
rd_ptr_gray <= '0;
end else begin
rd_ptr_bin <= rd_ptr_bin_next;
rd_ptr_gray <= rd_ptr_gray_next;
end
end
always_ff @(posedge rd_clk or negedge rd_rst_n) begin
if (!rd_rst_n) begin
wr_ptr_gray_rdclk_q1 <= '0;
wr_ptr_gray_rdclk_q2 <= '0;
end else begin
wr_ptr_gray_rdclk_q1 <= wr_ptr_gray;
wr_ptr_gray_rdclk_q2 <= wr_ptr_gray_rdclk_q1;
end
end
always_ff @(posedge wr_clk or negedge wr_rst_n) begin
if (!wr_rst_n) begin
rd_ptr_gray_wrclk_q1 <= '0;
rd_ptr_gray_wrclk_q2 <= '0;
end else begin
rd_ptr_gray_wrclk_q1 <= rd_ptr_gray;
rd_ptr_gray_wrclk_q2 <= rd_ptr_gray_wrclk_q1;
end
end
always_ff @(posedge wr_clk or negedge wr_rst_n) begin
if (!wr_rst_n) begin
full <= 1'b0;
end else begin
full <= (wr_ptr_gray_next == {
~rd_ptr_gray_wrclk_q2[PTR_WIDTH-1:PTR_WIDTH-2],
rd_ptr_gray_wrclk_q2[PTR_WIDTH-3:0]
});
end
end
always_ff @(posedge rd_clk or negedge rd_rst_n) begin
if (!rd_rst_n) begin
empty <= 1'b1;
end else begin
empty <= (rd_ptr_gray_next == wr_ptr_gray_rdclk_q2);
end
end
always_ff @(posedge wr_clk or negedge wr_rst_n) begin
if (!wr_rst_n) begin
wr_overflow <= 1'b0;
end else begin
wr_overflow <= wr_overflow | (wr_en && full);
end
end
always_ff @(posedge rd_clk or negedge rd_rst_n) begin
if (!rd_rst_n) begin
rd_underflow <= 1'b0;
end else begin
rd_underflow <= rd_underflow | (rd_en && empty);
end
end
assign overflow_error = wr_overflow;
assign underflow_error = rd_underflow;
endmodule
一个覆盖 CDC 场景的异步 FIFO testbench 如下。该 testbench 使用不同频率的 wr_clk / rd_clk,并通过 monitor 风格 scoreboard 检查实际写入和实际读出,覆盖 reset、写快读慢、读快写慢、随机读写、full/empty 边界和长时间 FIFO ordering。
//2026-06-01
//========================================
//The time unit and precision
`timescale 1ns/1ps
module tb_async_fifo;
localparam int DATA_WIDTH = 8;
localparam int DEPTH = 16;
logic wr_clk;
logic rd_clk;
logic wr_rst_n;
logic rd_rst_n;
logic wr_en;
logic [DATA_WIDTH-1:0] wr_data;
logic full;
logic rd_en;
logic [DATA_WIDTH-1:0] rd_data;
logic empty;
logic overflow_error;
logic underflow_error;
logic [DATA_WIDTH-1:0] exp_q [$];
int write_count;
int read_count;
int wr_cycle_count;
int rd_cycle_count;
int full_stall_count;
int empty_stall_count;
real wr_throughput;
real rd_throughput;
async_fifo #(
.DATA_WIDTH(DATA_WIDTH),
.DEPTH(DEPTH)
) dut (
.wr_clk,
.wr_rst_n,
.wr_en,
.wr_data,
.full,
.rd_clk,
.rd_rst_n,
.rd_en,
.rd_data,
.empty,
.overflow_error,
.underflow_error
);
initial wr_clk = 1'b0;
always #3 wr_clk = ~wr_clk;
initial rd_clk = 1'b0;
always #7 rd_clk = ~rd_clk;
// Write monitor: record accepted writes and write-side performance counters.
always @(posedge wr_clk) begin
if (wr_rst_n) begin
wr_cycle_count++;
if (wr_en && full) begin
full_stall_count++;
end
if (wr_en && !full) begin
exp_q.push_back(wr_data);
write_count++;
end
end
end
// Read monitor: compare accepted reads and record read-side performance counters.
always @(posedge rd_clk) begin
logic [DATA_WIDTH-1:0] exp;
if (rd_rst_n) begin
rd_cycle_count++;
if (rd_en && empty) begin
empty_stall_count++;
end
if (rd_en && !empty) begin
if (exp_q.size() == 0) begin
$fatal("Async FIFO scoreboard underflow");
end
exp = exp_q.pop_front();
read_count++;
assert(rd_data == exp)
else $fatal("Async FIFO mismatch: rd_data=%0h exp=%0h", rd_data, exp);
end
end
end
task automatic apply_reset();
wr_rst_n = 1'b0;
rd_rst_n = 1'b0;
wr_en = 1'b0;
wr_data = '0;
rd_en = 1'b0;
exp_q.delete();
write_count = 0;
read_count = 0;
wr_cycle_count = 0;
rd_cycle_count = 0;
full_stall_count = 0;
empty_stall_count = 0;
wr_throughput = 0.0;
rd_throughput = 0.0;
repeat (5) @(posedge wr_clk);
wr_rst_n = 1'b1;
repeat (5) @(posedge rd_clk);
rd_rst_n = 1'b1;
repeat (4) @(posedge wr_clk);
repeat (4) @(posedge rd_clk);
endtask
task automatic write_burst(input int n, input logic [DATA_WIDTH-1:0] base);
int accepted;
accepted = 0;
while (accepted < n) begin
@(negedge wr_clk);
if (!full) begin
wr_en = 1'b1;
wr_data = base + DATA_WIDTH'(accepted);
accepted++;
end else begin
wr_en = 1'b0;
end
end
@(negedge wr_clk);
wr_en = 1'b0;
endtask
task automatic read_until_count(input int n);
int target;
target = read_count + n;
while (read_count < target) begin
@(negedge rd_clk);
rd_en = !empty;
end
@(negedge rd_clk);
rd_en = 1'b0;
endtask
initial begin
apply_reset();
assert(empty == 1'b1);
assert(full == 1'b0);
// Empty read attempts should not underflow.
repeat (8) begin
@(negedge rd_clk);
rd_en = 1'b1;
end
@(negedge rd_clk);
rd_en = 1'b0;
repeat (4) @(posedge rd_clk);
assert(read_count == 0);
// Write fast, read slow: should exercise fill and possibly full.
fork
write_burst(64, 8'h00);
begin
repeat (20) @(posedge rd_clk);
read_until_count(64);
end
join
wait (exp_q.size() == 0);
repeat (10) @(posedge rd_clk);
assert(empty == 1'b1);
// Read faster after prefill.
fork
write_burst(32, 8'h80);
begin
repeat (4) @(posedge rd_clk);
read_until_count(32);
end
join
wait (exp_q.size() == 0);
repeat (10) @(posedge rd_clk);
// Random asynchronous traffic.
fork
begin : random_writer
for (int i = 0; i < 300; i++) begin
@(negedge wr_clk);
if ($urandom_range(0, 99) < 65 && !full) begin
wr_en = 1'b1;
wr_data = DATA_WIDTH'($urandom());
end else begin
wr_en = 1'b0;
end
end
@(negedge wr_clk);
wr_en = 1'b0;
end
begin : random_reader
for (int i = 0; i < 500; i++) begin
@(negedge rd_clk);
if ($urandom_range(0, 99) < 70 && !empty) begin
rd_en = 1'b1;
end else begin
rd_en = 1'b0;
end
end
@(negedge rd_clk);
rd_en = 1'b0;
end
join
// Drain remaining entries.
while (exp_q.size() != 0) begin
@(negedge rd_clk);
rd_en = !empty;
end
@(negedge rd_clk);
rd_en = 1'b0;
repeat (20) @(posedge rd_clk);
assert(exp_q.size() == 0);
assert(write_count == read_count);
// Performance summary: accepted transfers per local clock-domain cycle.
wr_throughput = real'(write_count) / real'(wr_cycle_count);
rd_throughput = real'(read_count) / real'(rd_cycle_count);
$display("tb_async_fifo PERF: wr_cycles=%0d rd_cycles=%0d write_count=%0d read_count=%0d wr_tput=%0.3f rd_tput=%0.3f full_stall=%0d empty_stall=%0d",
wr_cycle_count,
rd_cycle_count,
write_count,
read_count,
wr_throughput,
rd_throughput,
full_stall_count,
empty_stall_count);
$display("tb_async_fifo PASS, write_count=%0d read_count=%0d", write_count, read_count);
$finish;
end
endmodule
上面的异步 FIFO testbench 可以分成三组测试场景。第一组是 directed case,用来覆盖 reset、empty read、写快读慢、读侧追赶以及 drain 到空;第二组是 random asynchronous traffic,用来在两个不同时钟域中随机产生写请求和读请求,并通过 monitor 风格 scoreboard 检查实际 accepted write / accepted read 的 FIFO ordering;第三组是 performance summary,用已有 monitor 计数器统计 accepted transfer、local clock cycle、full stall、empty stall 和吞吐率。
9.1 异步 FIFO Testbench Case 说明
| 编号 | 测试场景 | 主要激励 | 期望结果 |
|---|---|---|---|
| 1 | Reset 后空 FIFO 检查 | 调用 apply_reset(),清零 exp_q、write_count、read_count、性能计数器,并分别释放 wr_rst_n / rd_rst_n |
empty = 1,full = 0,scoreboard 为空,计数器从 0 开始统计 |
| 2 | Empty read attempts | FIFO 为空时连续 8 个 rd_clk 周期拉高 rd_en |
不发生 accepted read,read_count = 0,不会触发 scoreboard underflow |
| 3 | Write fast, read slow | fork 中一边调用 write_burst(64, 8'h00),另一边先等待 20 个 rd_clk 周期再调用 read_until_count(64) |
写侧先向 FIFO 注入 64 个数据,读侧延迟后读出 64 个数据;monitor 检查读出数据顺序与 exp_q 一致;最终 exp_q.size() == 0,empty = 1 |
| 4 | Read faster after prefill | fork 中一边调用 write_burst(32, 8'h80),另一边等待 4 个 rd_clk 周期后调用 read_until_count(32) |
32 个数据被全部 accepted write 并按顺序 accepted read;最终 exp_q.size() == 0 |
| 5 | Random asynchronous traffic | random_writer 在 300 个 wr_clk 周期内以 65% 概率且 !full 时拉高 wr_en;random_reader 在 500 个 rd_clk 周期内以 70% 概率且 !empty 时拉高 rd_en |
monitor 只记录 accepted write/read;每个 accepted read 的 rd_data 与 scoreboard 队头一致;不会发生 scoreboard underflow |
| 6 | Drain remaining entries | random traffic 结束后,while (exp_q.size() != 0) 中按 rd_clk 持续令 rd_en <= !empty |
剩余 entry 被全部读出,最终 exp_q.size() == 0 且 write_count == read_count |
| 7 | Performance summary | write/read monitor 分别统计 wr_cycle_count、rd_cycle_count、full_stall_count、empty_stall_count;结尾计算 wr_throughput = write_count / wr_cycle_count 和 rd_throughput = read_count / rd_cycle_count |
打印 tb_async_fifo PERF,展示写时钟域和读时钟域各自的 accepted transfer per cycle、full stall 和 empty stall 统计;随后打印 tb_async_fifo PASS |
下图为异步 FIFO directed case 1 ~ 3 的仿真波形,覆盖 reset 后空 FIFO 检查、空读尝试,以及写快读慢时跨时钟域 accepted write / accepted read 与 scoreboard ordering 的一致性。

下图为异步 FIFO case 4 的仿真波形,先对 FIFO 进行预填充,然后让读侧以更快节奏追赶,重点观察读写指针跨域同步后数据仍按写入顺序读出。

下图为异步 FIFO case 5 ~ 6 的仿真波形,覆盖随机异步读写以及 random traffic 结束后的 drain remaining entries。该阶段主要检查 monitor 记录的 accepted write / accepted read 是否和 scoreboard 队列保持一致,并确认最终剩余 entry 全部读空。

下图为异步 FIFO case 7 的仿真波形和性能统计阶段,结合 wr_cycle_count、rd_cycle_count、full_stall_count、empty_stall_count 观察两个本地时钟域下的吞吐率和 stall 行为。

9.2 异步 FIFO 设计重点
上述 RTL 中有几个关键点:
- 写地址来自
wr_ptr_bin[ADDR_WIDTH-1:0]; - 读地址来自
rd_ptr_bin[ADDR_WIDTH-1:0]; - 跨域同步的是 Gray pointer,而不是 binary pointer;
full在wr_clk域产生;empty在rd_clk域产生;full判断需要比较 next write Gray pointer;empty判断需要比较 next read Gray pointer;overflow_error/underflow_error作为 sticky debug flag,分别在写满仍写、读空仍读时置位。
9.3 full 判断逻辑
异步 FIFO 中常见 full 判断如下:
full <= (wr_ptr_gray_next == {
~rd_ptr_gray_sync[PTR_WIDTH-1:PTR_WIDTH-2],
rd_ptr_gray_sync[PTR_WIDTH-3:0]
});
这表示写指针追上读指针一圈,即地址部分相同,但 wrap 信息表示 FIFO 已满。
这里容易误解的一点是:Gray pointer full 判断中并不是简单翻转同步读指针的最高 1 bit,而是翻转最高 2 bit。原因是 async FIFO 的指针通常是 ADDR_WIDTH + 1 位二进制指针,FIFO full 对应二进制意义上写指针比读指针超前 DEPTH。这个关系转换成 Gray code 后,会表现为 Gray pointer 的最高两位取反、其余低位相同。
以 DEPTH = 8 为例,二进制指针宽度为 4 bit。若读指针为 0_000,写指针走到满时为 1_000,二进制相差 8。转换成 Gray code 后:
rd_bin = 0000 -> rd_gray = 0000
wr_bin = 1000 -> wr_gray = 1100
可以看到 full 时对应的是 Gray 码最高两位从 00 变成 11,所以比较逻辑需要翻转同步读指针 Gray 值的最高两位。
下面用 WaveDrom 描述写指针跨域同步和 full 生成的时序关系。rd_ptr_gray 需要经过两级同步器进入写时钟域,因此 full 的判断基于已经同步后的 rd_ptr_gray_wrclk_q2,天然带有 CDC 反馈延迟。
{
signal: [
{ name: "wr_clk", wave: "p............" },
{ name: "wr_en", wave: "0.1111110...." },
{ name: "wr_ptr_bin", wave: "x=.=.=.=.=.=.", data: ["0", "1", "2", "3", "4", "5", "6"] },
{ name: "wr_ptr_gray", wave: "x=.=.=.=.=.=.", data: ["000", "001", "011", "010", "110", "111", "101"] },
{},
{ name: "rd_clk", wave: "p..p..p..p..." },
{ name: "rd_ptr_gray", wave: "x=.....=.....", data: ["000", "001"] },
{ name: "rd_gray_wrclk_q1", wave: "x..=.....=...", data: ["000", "001"] },
{ name: "rd_gray_wrclk_q2", wave: "x...=.....=..", data: ["000", "001"] },
{ name: "full", wave: "0......10...." }
],
head: {
text: "Async FIFO: Gray pointer synchronization and delayed full generation"
}
}
9.4 empty 判断逻辑
empty <= (rd_ptr_gray_next == wr_ptr_gray_sync);
这表示下一次读之后,读指针等于已经同步到读时钟域的写指针,FIFO 为空。
9.5 reset release 注意事项
异步 FIFO 的 reset 通常采用 async assert / sync deassert 风格:reset 可以异步拉低,确保两个时钟域的指针和状态快速清零;但 reset 释放最好分别同步到本地 wr_clk 和 rd_clk,避免 reset deassert 本身成为 CDC 风险。
典型做法是在每个时钟域各自生成本地同步释放 reset:
logic [1:0] wr_rst_sync;
logic [1:0] rd_rst_sync;
always_ff @(posedge wr_clk or negedge rst_n) begin
if (!rst_n) begin
wr_rst_sync <= 2'b00;
end else begin
wr_rst_sync <= {wr_rst_sync[0], 1'b1};
end
end
always_ff @(posedge rd_clk or negedge rst_n) begin
if (!rst_n) begin
rd_rst_sync <= 2'b00;
end else begin
rd_rst_sync <= {rd_rst_sync[0], 1'b1};
end
end
assign wr_rst_n = wr_rst_sync[1];
assign rd_rst_n = rd_rst_sync[1];
另外,两个时钟域 reset 释放的先后顺序可能不同。系统级协议应保证 reset 释放稳定前不会发起有效读写,或者在 FIFO 外部增加初始化完成握手。
reset 同步释放的波形可以表示如下:外部 rst_n 异步拉高后,wr_rst_n 和 rd_rst_n 分别在本地时钟域延迟两拍释放。由于两个时钟频率不同,本地 reset 释放时间点可能不同。
{
signal: [
{ name: "rst_n", wave: "0.1.........." },
{ name: "wr_clk", wave: "p............" },
{ name: "wr_rst_sync", wave: "x=.=.........", data: ["00", "01", "11"] },
{ name: "wr_rst_n", wave: "0...1........" },
{},
{ name: "rd_clk", wave: "p..p..p..p..." },
{ name: "rd_rst_sync", wave: "x=..=..=.....", data: ["00", "01", "11"] },
{ name: "rd_rst_n", wave: "0......1....." }
],
head: {
text: "Async assert / sync deassert reset in two clock domains"
}
}
10 CDC 分析 Checklist:结构、约束与常见错误
分析 async FIFO 时,建议按以下 checklist 检查:
[ ] data 是否通过 dual-port memory 传输
[ ] 是否没有直接同步 data bus
[ ] binary pointer 是否只在本地时钟域使用
[ ] 跨域 pointer 是否转换为 Gray code
[ ] Gray pointer 是否经过 two-flop synchronizer
[ ] full 是否只在 wr_clk domain 产生
[ ] empty 是否只在 rd_clk domain 产生
[ ] reset assertion 是否能清零两个时钟域指针
[ ] reset release 是否满足本地时钟域同步要求
[ ] DEPTH 是否为 2 的幂
[ ] CDC 工具是否识别 synchronizer
[ ] Gray bus 是否有 max delay 或 bus skew 约束
其中 Gray bus 约束尤其容易被忽略。Gray code 在逻辑上每次递增只翻转 1 bit,但如果物理实现中各 bit 的路径延迟差异过大,接收时钟域仍可能在不同采样边沿看到多个 bit 的变化。因此,对于跨域 Gray pointer bus,除了 CDC 结构正确,还应考虑 max delay 或 bus skew 约束。
约束目标不是把跨时钟域路径做成普通同步时序路径,而是限制同一组 Gray pointer bit 之间的到达偏斜,使其满足“接收端不会观察到多个 bit 分散跨多个周期变化”的假设。伪 SDC 示例:
# 示例:约束写指针 Gray bus 到读时钟域第一级同步器的路径偏斜
set_max_delay -datapath_only <one_fast_clk_period> \
-from [get_pins wr_ptr_gray_reg*/Q] \
-to [get_pins wr_ptr_gray_rdclk_q1*/D]
# 或使用工具支持的 bus skew 约束
set_bus_skew <allowed_skew> \
-from [get_pins wr_ptr_gray_reg*/Q] \
-to [get_pins wr_ptr_gray_rdclk_q1*/D]
实际命令需要根据 Synopsys、Cadence、Vivado 或其他工具的约束语法调整。
常见错误如下:
| 错误 | 后果 |
|---|---|
| binary pointer 直接跨域 | full/empty 可能错误 |
| data bus 直接打两拍 | 多 bit 数据不一致 |
| full 在读时钟域产生 | 写侧 backpressure 错误 |
| empty 在写时钟域产生 | 读侧控制错误 |
| reset 异步释放无处理 | 两边 pointer 初始状态不一致 |
| Gray bus 无约束 | 物理实现后可能多 bit 同时到达 |
11 FIFO 架构分析重点:设计评审时看什么
前面的章节分别讲了同步 FIFO、Peek FIFO 和异步 FIFO。实际做设计评审时,建议不要只盯着某一段 RTL,而是先确认 FIFO 类型、接口语义、状态边界、深度 sizing、CDC 和验证覆盖是否一致。
可以先用下面这张表快速定位问题:
| 评审问题 | 重点检查 | 对应章节 |
|---|---|---|
| 这个 FIFO 属于哪一类? | sync / async、peek / non-peek、FWFT / registered read | 第 4、7、8 节 |
| 状态边界是否清楚? | full、empty、同周期 read/write、wrap-around |
第 4、5 节 |
| 深度是否够? | burst、stall、backpressure latency、CDC feedback latency | 第 6 节 |
| CDC 是否安全? | Gray pointer、two-flop synchronizer、reset release、bus skew | 第 8、9、10 节 |
| 验证是否覆盖关键场景? | directed、random、performance、boundary、reset | 第 12 节 |
11.1 FIFO 类型
首先要确认 FIFO 类型:
sync or async?
peek or non-peek?
register array or SRAM?
ready/valid interface or wr_en/rd_en + full/empty interface?
11.2 full/empty
对同步 FIFO:
count 是否正确更新?
同周期读写是否定义清楚?
full 时 read + write 是否允许?
empty 时 write + read 是否允许?
对异步 FIFO:
Gray pointer 是否正确?
同步方向是否正确?
full/empty 是否在本地域生成?
是否比较 next pointer?
11.3 depth sizing
sizing 时建议明确以下参数:
- 最大 burst 长度;
- 写入速率;
- 读出速率;
- 下游最大 stall;
- 上游看到 full 后的响应延迟;
- CDC synchronizer 延迟;
- arbitration latency;
- 是否允许丢包;
- 面积和 SRAM macro 限制。
12 FIFO 验证建议:从边界条件到长时间随机
FIFO 验证应覆盖边界条件,而不仅仅是普通 push/pop。建议按三层组织:先用 directed case 打穿关键边界,再用 random case 覆盖长时间组合行为,最后用 performance / throughput case 观察持续读写、stall 和 backpressure 行为。
| 验证层次 | 目的 | 典型检查 |
|---|---|---|
| Directed case | 精确覆盖已知边界 | reset、empty read、full write、wrap-around、同周期 read/write |
| Random case | 覆盖长期随机组合 | scoreboard ordering、level、flag 一致性 |
| Performance case | 观察吞吐和 stall | accepted transfer、full stall、empty stall、持续 read/write |
12.1 Sync FIFO 验证点
[ ] reset 后 empty=1, full=0
[ ] empty 时 read 不改变状态
[ ] full 时 write 不覆盖未读数据
[ ] 连续写到 full
[ ] 连续读到 empty
[ ] 同周期 read/write 时 count 保持
[ ] pointer wrap-around
[ ] data ordering 保持 FIFO 顺序
12.2 Peek FIFO 验证点
[ ] peek_data 指向 head entry
[ ] peek 不改变 rd_ptr
[ ] pop 改变 rd_ptr
[ ] 连续 peek 数据保持
[ ] peek 后 pop 顺序正确
[ ] empty 时 peek_valid=0
12.3 Async FIFO 验证点
[ ] wr_clk faster than rd_clk
[ ] rd_clk faster than wr_clk
[ ] random wr_en / rd_en
[ ] random reset
[ ] full boundary
[ ] empty boundary
[ ] long-run data ordering
[ ] no overflow
[ ] no underflow
13 总结
FIFO 的主线可以总结为:
Buffering
-> Sync FIFO
-> full/empty boundary and depth sizing
-> Peek / Non-Peek / FWFT read semantics
-> Async FIFO and CDC safety
-> architecture review and verification
其中最重要的工程能力包括:
- 能够根据系统流量估算 FIFO 深度;
- 能够解释
wr_ptr == rd_ptr的 full/empty 歧义; - 能够写出同步 FIFO 和异步 FIFO RTL;
- 能够区分 peek FIFO 与普通 FIFO 的行为;
- 能够识别 async FIFO 中的 CDC 风险;
- 能够针对 full、empty、wrap-around、reset 做完整验证。
FIFO 是 Buffer 设计的基础,也是 CDC 设计中最经典的结构之一。掌握 FIFO 的架构、RTL 和验证方法,是进一步学习 bus bridge、NoC、DMA、cache queue、packet buffer 的重要基础。
14 参考资料
本文在整理 FIFO 架构、异步 FIFO、CDC、Gray pointer、ready/valid 接口和 SystemVerilog testbench 等内容时,参考了以下经典论文、厂商文档和协议 / 语言资料。
-
Clifford E. Cummings, Simulation and Synthesis Techniques for Asynchronous FIFO Design, SNUG San Jose 2002.
https://www.sunburst-design.com/papers/CummingsSNUG2002SJ_FIFO1.pdf -
Clifford E. Cummings, Clock Domain Crossing (CDC) Design & Verification Techniques Using SystemVerilog, SNUG Boston 2008.
https://www.sunburst-design.com/papers/CummingsSNUG2008Boston_CDC.pdf -
Clifford E. Cummings, Synthesis and Scripting Techniques for Designing Multi-Asynchronous Clock Designs, SNUG San Jose 2001.
https://www.sunburst-design.com/papers/CummingsSNUG2001SJ_AsyncClk.pdf -
Peter Alfke, FIFO Design in Virtex and Virtex-II FPGAs, Xilinx Application Note XAPP131.
https://docs.amd.com/v/u/en-US/xapp131 -
AMD/Xilinx, FIFO Generator LogiCORE IP Product Guide, PG057.
https://docs.amd.com/v/u/en-US/pg057-fifo-generator -
Intel, SCFIFO and DCFIFO Intel FPGA IP User Guide.
https://www.intel.com/content/www/us/en/docs/programmable/683522/latest/scfifo-and-dcfifo-intel-fpga-ip.html -
Mark Litterick, Pragmatic Simulation-Based Verification of Clock Domain Crossing Signals and Jitter Using SystemVerilog Assertions, Verilab.
https://www.verilab.com/files/litterick_cdc_sva.pdf -
Sutherland, Davidmann, Flake, SystemVerilog for Design: A Guide to Using SystemVerilog for Hardware Design and Modeling, Springer.
https://link.springer.com/book/10.1007/0-387-36495-1 -
Chris Spear, Greg Tumbush, SystemVerilog for Verification: A Guide to Learning the Testbench Language Features, Springer.
https://link.springer.com/book/10.1007/978-1-4614-0715-7 -
Arm, AMBA AXI-Stream Protocol Specification.
https://developer.arm.com/documentation/ihi0051/latest/
