1 前言
CRC(Cyclic Redundancy Check,循环冗余校验)是一类面向数据完整性检测的编码方法,广泛用于 packet、frame、sector、transaction 等粒度的数据保护。它不能纠正错误,但可以以很低的硬件开销发现传输或存储过程中出现的 bit flip、burst error、截断、拼接和部分顺序错误。
在数字 IC 和 FPGA 设计中,CRC 经常出现在以下位置:
- Ethernet frame FCS,典型为 CRC-32;
- PCIe TLP / DLLP 中的 LCRC / CRC;
- USB token / data packet 中的 CRC5 / CRC16;
- MIPI、SATA、NVMe、SD 卡、存储控制器;
- NoC packet、DMA descriptor、片上 message passing;
- 固件镜像、配置表、OTP/eFuse shadow 数据校验。
本文围绕“数据完整性检测(packet 级)”展开,重点讨论 CRC 的 polynomial 选择、bit 顺序、pipeline、串行/并行实现,并给出一个建议小项目:CRC32 实现(64B/512b 并行)生成 + 校验。
2 学习路径
CRC 的学习可以按如下路径展开:
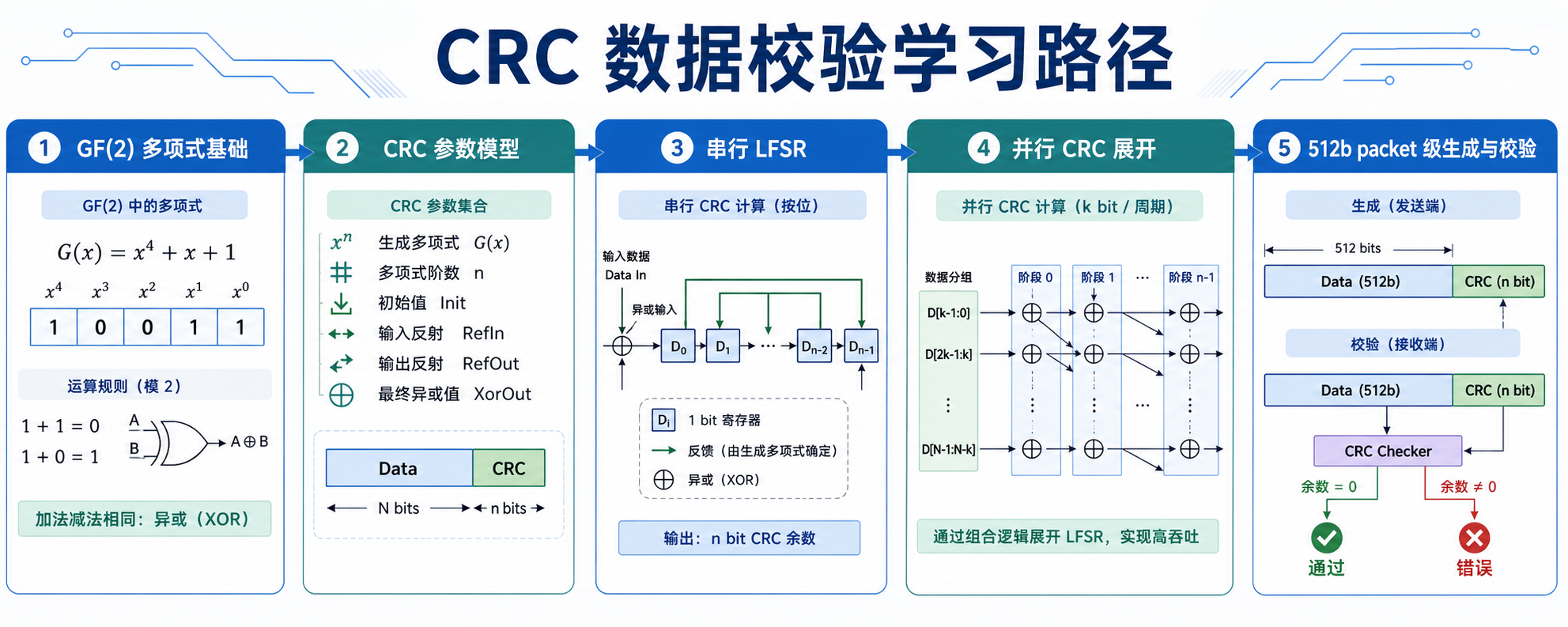
对应的学习目标如下:
| 类别 | 内容 |
|---|---|
| 数据校验 | 理解 CRC 如何用于 packet 级数据完整性检测 |
| 数学基础 | 掌握 GF(2) 多项式、模 2 除法、余数和 syndrome |
| 架构分析 | polynomial 选择、bit 顺序、pipeline、并行/串行实现 |
| RTL 设计 | LFSR 结构展开、并行 CRC、seed、invert、byte enable |
| 小项目 | CRC32 64B/512b 并行生成 + 校验 |
3 CRC 的基本概念
3.1 CRC 解决什么问题
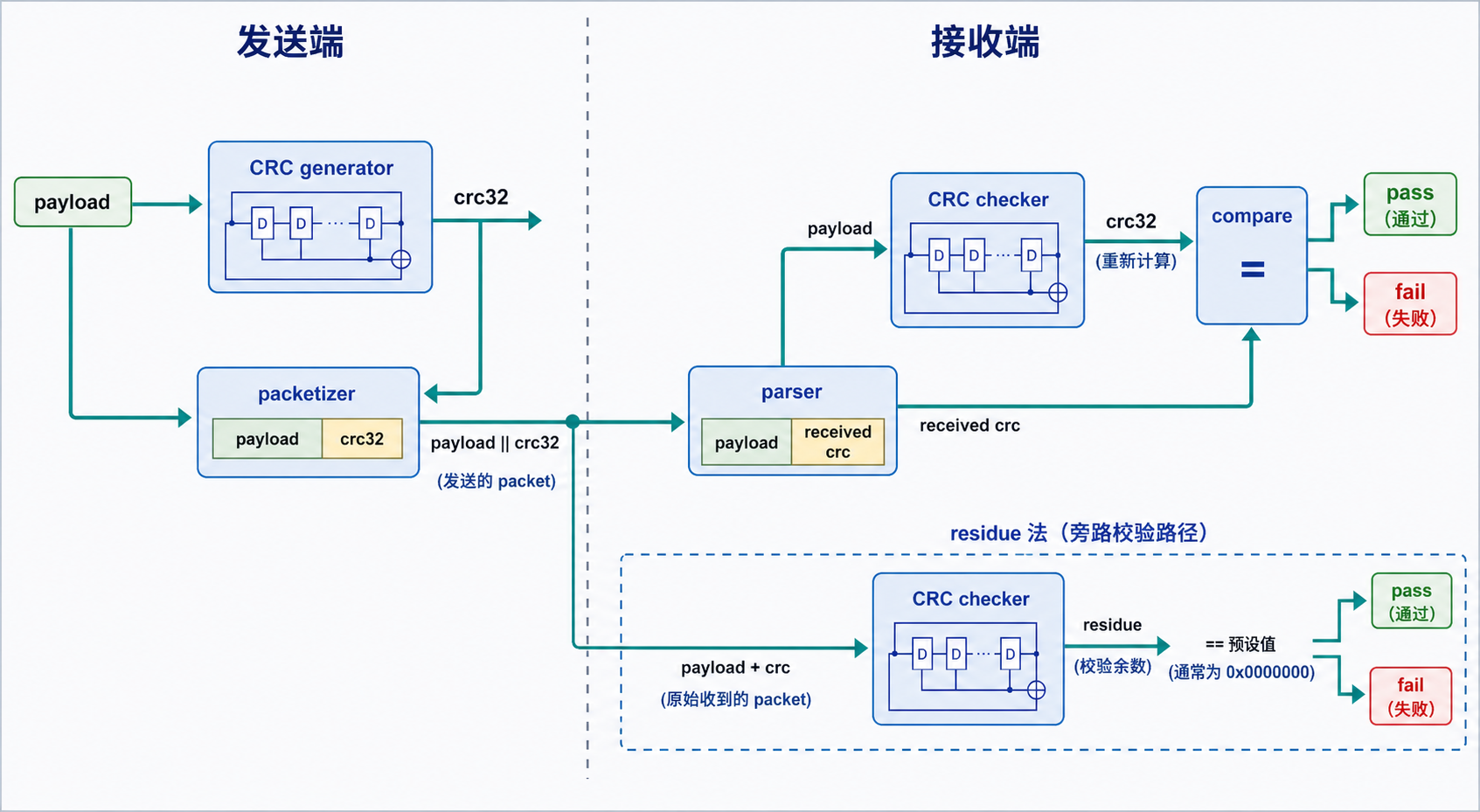
CRC 的目标是判断一段数据在传输或存储后是否发生了变化。发送端根据 payload 计算出一个 CRC 值,并把它附加在 packet 尾部;接收端重新计算 CRC,或者把 payload 和 CRC 字段一起送入 checker,判断结果是否满足预期。
发送端:
payload -> CRC generator -> payload || crc
接收端:
payload || crc -> CRC checker -> pass / fail
CRC 不是加密算法,也不是 MAC(Message Authentication Code)。它主要用于检测随机错误或物理链路错误,不用于抵抗恶意篡改。
3.2 CRC 的数学本质
CRC 本质上是在 GF(2) 上做多项式除法。GF(2) 中只有 0 和 1,加法等价于 XOR,减法也等价于 XOR,没有进位或借位。
0 + 0 = 0
0 + 1 = 1
1 + 0 = 1
1 + 1 = 0
加法 = XOR
减法 = XOR
将 bit 串看作一个多项式:
bit string: 1011
polynomial: x^3 + x + 1
如果 CRC 位宽为 n,生成多项式为 G(x),发送数据为 M(x),则 CRC 余数可以表示为:
R(x) = M(x) * x^n mod G(x)
发送端发送:
T(x) = M(x) * x^n + R(x)
接收端检查:
T(x) mod G(x) == 0
实际工程中的 CRC 标准通常还会包含 seed、bit reflection、final xor 等参数,因此接收端不一定总是检查 0,也可能检查一个固定 residue / magic number。
3.3 CRC 参数模型
一个完整 CRC 标准至少需要定义以下参数:
| 参数 | 说明 |
|---|---|
| Width | CRC 寄存器宽度 |
| Poly | 生成多项式,通常不包含最高次项 |
| Init / Seed | 每个 packet 开始时 CRC 寄存器初始值 |
| RefIn | 输入数据是否按 bit 反射 |
| RefOut | 输出 CRC 是否反射 |
| XorOut / Invert | 输出前是否与固定值 XOR |
| Check | 对字符串 "123456789" 的标准结果 |
| Residue | 把 data + crc 一起计算后的固定余数 |
以常见的 CRC-32/ISO-HDLC,也就是 Ethernet CRC32 为例:
Width = 32
Poly = 0x04C11DB7
Init = 0xFFFFFFFF
RefIn = True
RefOut = True
XorOut = 0xFFFFFFFF
Check = 0xCBF43926
Residue = 0x2144DF1C
4 Polynomial 选择
4.1 什么是生成多项式
CRC 的 polynomial 决定了 LFSR 的反馈 tap,也决定了错误检测能力。CRC-32/ISO-HDLC 的生成多项式为:
G(x) = x^32 + x^26 + x^23 + x^22 + x^16 + x^12 + x^11
+ x^10 + x^8 + x^7 + x^5 + x^4 + x^2 + x + 1
通常十六进制表示不包含最高位 x^32:
normal polynomial = 0x04C11DB7
reflected polynomial = 0xEDB88320
4.2 常见 CRC polynomial
| 标准 | Width | Poly | RefIn/RefOut | 典型应用 |
|---|---|---|---|---|
| CRC-5/USB | 5 | 0x05 | True / True | USB token |
| CRC-8/SMBus | 8 | 0x07 | False / False | SMBus |
| CRC-16/IBM | 16 | 0x8005 | True / True | Modbus、USB |
| CRC-16/CCITT-FALSE | 16 | 0x1021 | False / False | X.25、HDLC 变体 |
| CRC-32/ISO-HDLC | 32 | 0x04C11DB7 | True / True | Ethernet、ZIP、PNG |
| CRC-32C | 32 | 0x1EDC6F41 | True / True | iSCSI、SCTP |
| CRC-64/ECMA | 64 | 0x42F0E1EBA9EA3693 | False / False | 存储、文件校验 |
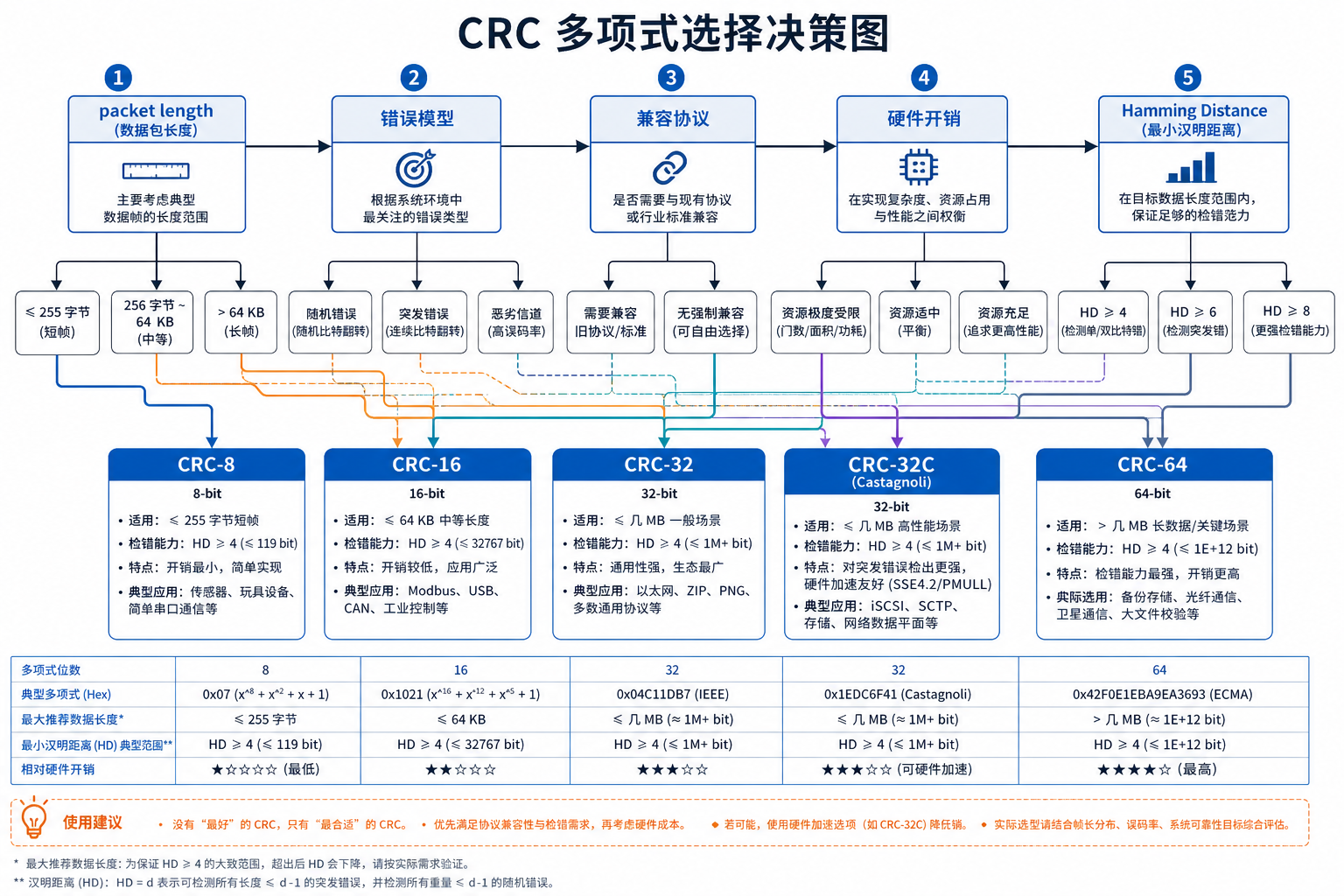
4.3 Polynomial 选择原则
选择 polynomial 时,一般关注以下指标:
- 是否能检测所有单 bit 错误;
- 是否能检测所有双 bit 错误;
- 是否能检测所有奇数个 bit 错误;
- 是否能检测长度不超过
Width的 burst error; - 对目标最大 packet length 的汉明距离(Hamming Distance);
- 是否需要兼容已有协议或软件库;
- RTL 实现面积和时序是否可接受。
工程上通常不建议自己随意发明 polynomial。对于标准接口,应直接使用协议规定的 CRC 参数;对于自定义片内 packet,如果长度和错误模型没有特殊要求,可以优先选择已经被充分分析过的 CRC-16、CRC-32 或 CRC-32C。
5 Bit 顺序与字节序
5.1 MSB-first 与 LSB-first
CRC 实现最容易出错的地方是 bit 顺序。对于同一个 polynomial,如果输入 bit 顺序不同,LFSR 移位方向、tap 表示和最终输出都会不同。
| 项目 | MSB-first | LSB-first / Reflected |
|---|---|---|
| 输入顺序 | 每个 byte 的 bit7 先处理 | 每个 byte 的 bit0 先处理 |
| LFSR 移位方向 | 通常左移 | 通常右移 |
| polynomial | normal poly,例如 0x04C11DB7 | reflected poly,例如 0xEDB88320 |
| 常见场景 | ATM、部分存储协议 | Ethernet、USB、ZIP、zlib |
对 CRC-32/ISO-HDLC,软件库 zlib.crc32() 使用的就是 reflected 模型。硬件如果按 Ethernet 字节流处理,也通常采用 LSB-first 的右移 LFSR。
5.2 Byte order 与 bit order 不要混淆
需要区分两个概念:
byte order:多个 byte 在总线上的排列顺序
bit order :一个 byte 内部 bit 被 CRC 处理的顺序
例如 512-bit AXI-Stream 数据 tdata[511:0] 中,很多设计约定:
tdata[7:0] = packet 的第 0 个 byte
tdata[15:8] = packet 的第 1 个 byte
...
tdata[511:504] = packet 的第 63 个 byte
如果 CRC 模型是 reflected,那么每个 byte 内部处理顺序为 bit0、bit1、…、bit7。但这不等于把整个 512-bit bus 完全 bit reverse。
5.3 bit reverse 函数
function automatic logic [7:0] bit_reverse8(
input logic [7:0] data
);
for (int i = 0; i < 8; i++) begin
bit_reverse8[i] = data[7-i];
end
endfunction
对 reflected CRC,如果直接采用 LSB-first LFSR,一般不需要显式对每个 byte 做 bit reverse;如果内部使用 MSB-first 方程,则可能需要在入口和出口增加 bit reverse。架构设计时要固定一种 convention,并在文档中写清楚。
6 串行 CRC 与 LFSR
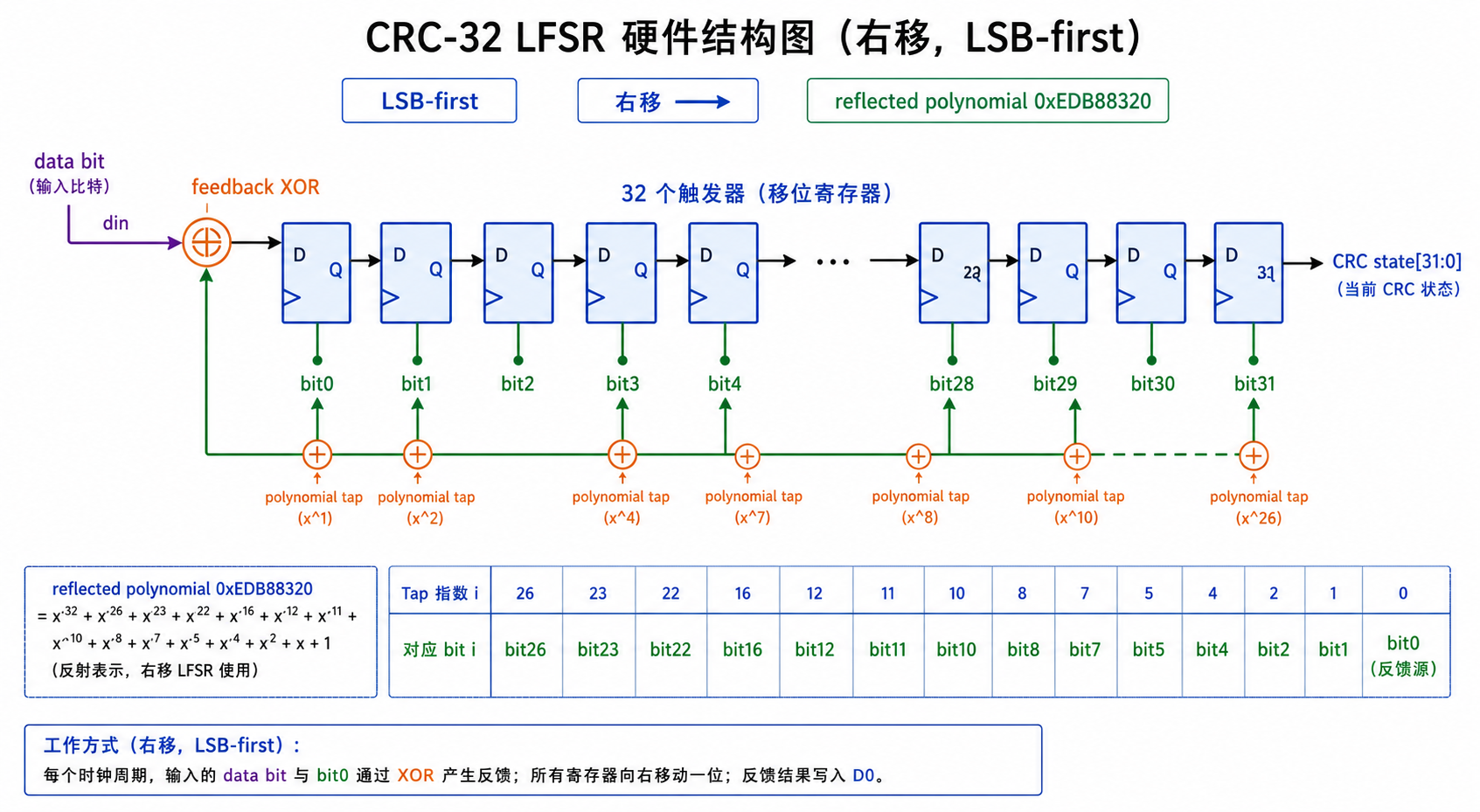
6.1 LFSR 基本结构
CRC 的硬件本质是 LFSR。串行 CRC 每个 cycle 处理 1 bit,资源非常少,但吞吐率低。
6.2 LSB-first CRC32 串行更新函数
下面给出 reflected CRC-32 的 1-bit 更新函数。这里的 crc_state 是内部状态,不是最终输出值。最终输出还需要 xorout,也就是取反。
function automatic logic [31:0] crc32_lsb1_next(
input logic [31:0] crc_state,
input logic data_bit
);
logic feedback;
logic [31:0] shifted;
begin
feedback = crc_state[0] ^ data_bit;
shifted = {1'b0, crc_state[31:1]};
if (feedback) begin
crc32_lsb1_next = shifted ^ 32'hEDB88320;
end else begin
crc32_lsb1_next = shifted;
end
end
endfunction
6.3 串行 CRC32 generator RTL
module crc32_serial_lsb #(
parameter logic [31:0] INIT = 32'hFFFF_FFFF,
parameter logic [31:0] XOROUT = 32'hFFFF_FFFF
) (
input logic clk,
input logic rst_n,
input logic clear,
input logic data_valid,
input logic data_bit,
output logic [31:0] crc_value
);
logic [31:0] crc_state;
function automatic logic [31:0] crc32_lsb1_next(
input logic [31:0] crc_state_i,
input logic data_bit_i
);
logic feedback;
logic [31:0] shifted;
begin
feedback = crc_state_i[0] ^ data_bit_i;
shifted = {1'b0, crc_state_i[31:1]};
if (feedback) begin
crc32_lsb1_next = shifted ^ 32'hEDB88320;
end else begin
crc32_lsb1_next = shifted;
end
end
endfunction
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
crc_state <= INIT;
end else if (clear) begin
crc_state <= INIT;
end else if (data_valid) begin
crc_state <= crc32_lsb1_next(crc_state, data_bit);
end
end
assign crc_value = crc_state ^ XOROUT;
endmodule
串行实现适合学习 LFSR 原理,也适合低速接口。但在高速 packet datapath 中,例如每拍 64B 的网络接口,必须使用并行 CRC。
7 LFSR 结构展开与并行 CRC
7.1 并行化思想
并行 CRC 的本质是把串行 LFSR 一次展开 N 步:
串行:
cycle k : process bit0
cycle k+1 : process bit1
...
cycle k+N-1 : process bitN-1
并行:
cycle k : process bit[N-1:0]
由于 CRC 是 GF(2) 上的线性运算,因此下一状态一定可以表示为当前状态和输入数据的 XOR 组合:
crc_next = A * crc_state XOR B * data
其中:
A是状态转移矩阵;B是输入数据影响矩阵;- 所有加法都是 XOR;
- 所有乘法都是 AND。
7.2 使用函数循环展开
在 RTL 中可以先用函数描述 N bit 并行更新。综合工具会把固定次数的 for loop 展开成组合逻辑。
function automatic logic [31:0] crc32_lsbN_next #(
int DATA_WIDTH = 64
) (
input logic [31:0] crc_state_i,
input logic [DATA_WIDTH-1:0] data_i,
input logic [DATA_WIDTH/8-1:0] keep_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int byte_idx = 0; byte_idx < DATA_WIDTH/8; byte_idx++) begin
if (keep_i[byte_idx]) begin
for (int bit_idx = 0; bit_idx < 8; bit_idx++) begin
crc_tmp = crc32_lsb1_next(
crc_tmp,
data_i[byte_idx*8 + bit_idx]
);
end
end
end
crc32_lsbN_next = crc_tmp;
end
endfunction
上面这种写法可读性很好,也便于处理 tkeep。缺点是对于 512-bit 并行输入,综合后会得到非常深的 XOR 网络,可能难以达到高频。因此工程实现通常会:
- 生成显式 XOR 方程;
- 对 byte / 64-bit chunk 分段;
- 插入 pipeline;
- 或使用矩阵切分和 CRC combine。
7.3 8-bit 并行更新函数
下面给出一个可综合的 8-bit 并行函数,它通过 8 次 1-bit 更新展开。综合后没有时序状态,只是组合逻辑。
function automatic logic [31:0] crc32_lsb8_next(
input logic [31:0] crc_state_i,
input logic [7:0] data_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int i = 0; i < 8; i++) begin
crc_tmp = crc32_lsb1_next(crc_tmp, data_i[i]);
end
crc32_lsb8_next = crc_tmp;
end
endfunction
7.4 64-bit 并行更新函数
function automatic logic [31:0] crc32_lsb64_next(
input logic [31:0] crc_state_i,
input logic [63:0] data_i,
input logic [7:0] keep_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int byte_idx = 0; byte_idx < 8; byte_idx++) begin
if (keep_i[byte_idx]) begin
crc_tmp = crc32_lsb8_next(
crc_tmp,
data_i[byte_idx*8 +: 8]
);
end
end
crc32_lsb64_next = crc_tmp;
end
endfunction
对 512-bit 数据,可以把数据拆成 8 个 64-bit lane,每个 lane 使用相同的 64-bit 更新函数。最简单的方式是 lane0 到 lane7 顺序串接,最容易验证;更高频的方式是把这些 lane 的组合逻辑再做流水线或矩阵合并。
8 Pipeline 与并行/串行取舍
8.1 串行、半并行、全并行
| 实现方式 | 每拍处理数据 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 串行 LFSR | 1 bit | 面积极小、易懂 | 吞吐率低 | UART、低速 SPI、学习 |
| Byte 并行 | 8 bit | 易验证、适配软件模型 | 高速链路不足 | MCU bus、低速 packet |
| 64-bit 并行 | 8 Byte | 面积适中 | XOR 网络开始变深 | AXI、DMA、NoC |
| 512-bit 并行 | 64 Byte | 高吞吐 | 时序压力大 | 100G/400G、PCIe、宽 NoC |
8.2 512-bit CRC 的时序问题
如果直接把 512 个输入 bit 展开成一个组合函数,综合后每个 CRC 输出 bit 可能包含大量 XOR 项。虽然 XOR 是简单门,但 fan-in、布线和级联深度会显著影响时序。
常见优化方法包括:
- 每 64-bit 做一段,段与段之间插入 pipeline;
- 先计算多个 partial CRC,再通过矩阵 combine 合并;
- 将 XOR tree 做平衡树;
- 在高 fanout 的中间信号处插入寄存器;
- 对
valid、last、keep、crc_state做严格 pipeline 对齐。
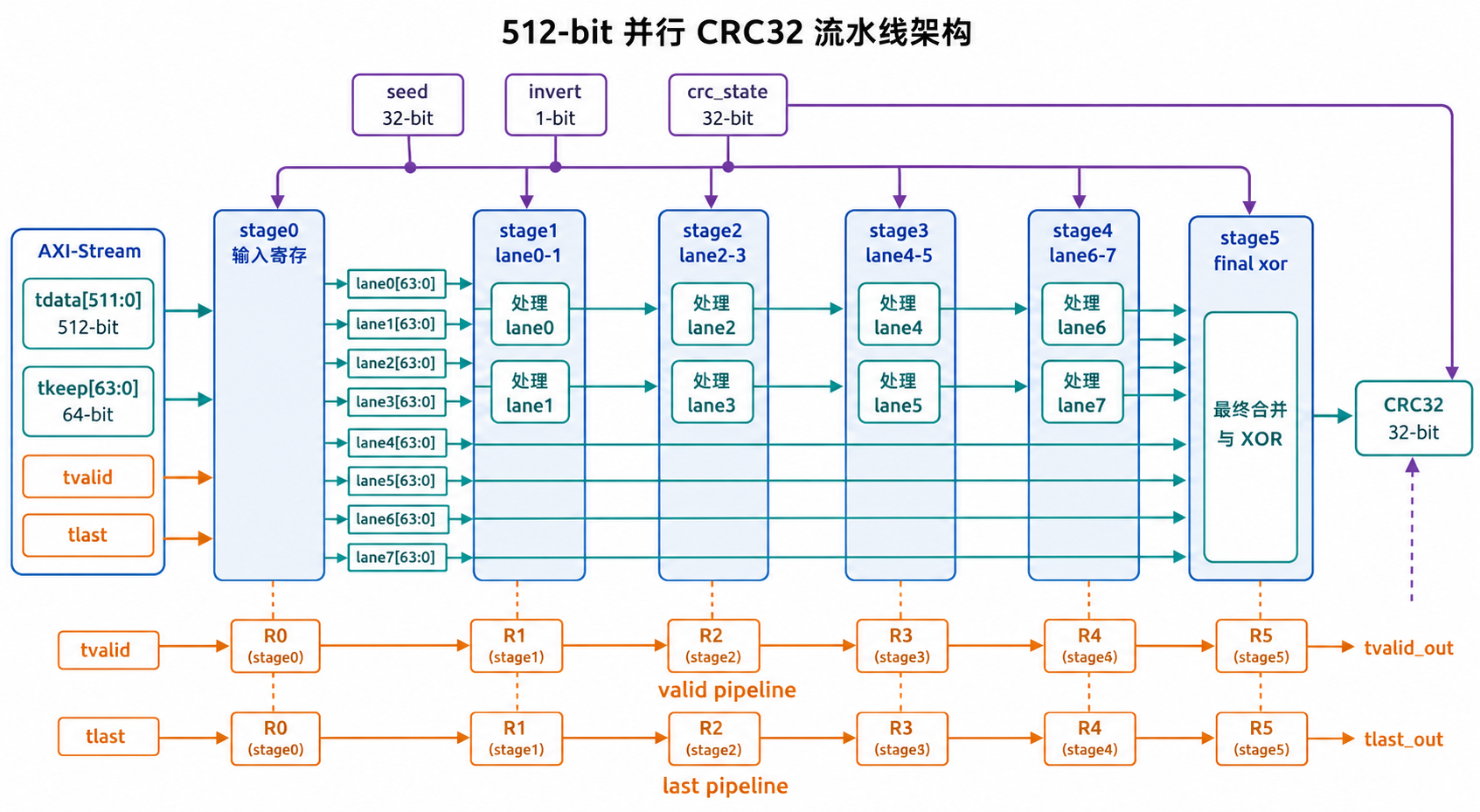
8.3 Pipeline 控制信号
CRC pipeline 中不能只 pipeline 数据,还必须同步 pipeline 控制信息:
valid
sop / first beat
eop / last beat
keep / byte valid
mode_gen / mode_check
packet_id(如果多 packet interleave)
如果 CRC 模块一次只处理一个 packet,并且采用 ready/valid backpressure,则控制逻辑相对简单;如果多个 packet 交错进入,需要为每个 packet 保存独立 CRC context。
9 Seed、Invert 与 Residue
9.1 Seed
Seed 是每个 packet 开始时 CRC state 的初始值。CRC-32/ISO-HDLC 使用:
INIT = 0xFFFFFFFF
RTL 中一般在 SOP 或 start 时加载 seed:
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
crc_state <= INIT;
end else if (start_packet) begin
crc_state <= INIT;
end else if (data_fire) begin
crc_state <= crc_next;
end
end
9.2 Invert / XorOut
CRC-32/ISO-HDLC 输出前需要与 0xFFFFFFFF XOR:
crc_output = crc_state ^ 0xFFFFFFFF
SystemVerilog 写法:
assign crc_value = crc_state ^ 32'hFFFF_FFFF;
或:
assign crc_value = ~crc_state;
9.3 校验方式
常见 CRC checker 有两种实现方法。
方法一:重新计算并比较
recv_payload -> crc_calc -> calc_crc
calc_crc == recv_crc -> pass
优点是直观,适合 packet 尾部 CRC 字段已经被 parser 提取出来的情况。
方法二:payload + crc 一起计算 residue
payload || recv_crc -> crc_calc -> residue
residue == expected_residue -> pass
对 CRC-32/ISO-HDLC,reflected byte order 下常见 residue 为:
0x2144DF1C
使用 residue 法时必须确保接收到的 CRC 字段 byte order 与协议一致。例如 Ethernet FCS 在链路上传输时也是低 bit 先发,软件内存中的显示顺序可能与波形中的 bit 顺序不同。
10 CRC32 64B/512b 并行小项目
10.1 项目目标
本小项目实现一个 packet 级 CRC32 模块,支持每拍输入 64 Byte,也就是 512 bit 数据,同时支持 CRC 生成和 CRC 校验。
| 项目 | 规格 |
|---|---|
| CRC 标准 | CRC-32/ISO-HDLC |
| 数据宽度 | 512 bit / 64 Byte |
| 输入协议 | ready/valid + keep + last |
| bit 顺序 | LSB-first / reflected |
| seed | 0xFFFFFFFF |
| xorout | 0xFFFFFFFF |
| 生成模式 | 输出 payload 的 CRC32 |
| 校验模式 | 可用重新计算比较法或 residue 法 |
| partial beat | 使用 keep 指示有效 byte |
10.2 顶层接口
module crc32_512b_packet #(
parameter logic [31:0] INIT = 32'hFFFF_FFFF,
parameter logic [31:0] XOROUT = 32'hFFFF_FFFF,
parameter logic [31:0] RESIDUE = 32'h2144_DF1C,
parameter bit CHECK_BY_RESIDUE = 1'b0
) (
input logic clk,
input logic rst_n,
input logic [511:0] s_data,
input logic [63:0] s_keep,
input logic s_valid,
output logic s_ready,
input logic s_last,
input logic mode_check,
input logic [31:0] expected_crc,
output logic [31:0] crc_value,
output logic crc_valid,
output logic crc_ok
);
logic [31:0] crc_state;
logic [31:0] crc_next;
logic fire;
assign s_ready = 1'b1;
assign fire = s_valid && s_ready;
function automatic logic [31:0] crc32_lsb1_next(
input logic [31:0] crc_state_i,
input logic data_bit_i
);
logic feedback;
logic [31:0] shifted;
begin
feedback = crc_state_i[0] ^ data_bit_i;
shifted = {1'b0, crc_state_i[31:1]};
if (feedback) begin
crc32_lsb1_next = shifted ^ 32'hEDB88320;
end else begin
crc32_lsb1_next = shifted;
end
end
endfunction
function automatic logic [31:0] crc32_lsb8_next(
input logic [31:0] crc_state_i,
input logic [7:0] data_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int bit_idx = 0; bit_idx < 8; bit_idx++) begin
crc_tmp = crc32_lsb1_next(crc_tmp, data_i[bit_idx]);
end
crc32_lsb8_next = crc_tmp;
end
endfunction
function automatic logic [31:0] crc32_lsb512_next(
input logic [31:0] crc_state_i,
input logic [511:0] data_i,
input logic [63:0] keep_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int byte_idx = 0; byte_idx < 64; byte_idx++) begin
if (keep_i[byte_idx]) begin
crc_tmp = crc32_lsb8_next(
crc_tmp,
data_i[byte_idx*8 +: 8]
);
end
end
crc32_lsb512_next = crc_tmp;
end
endfunction
assign crc_next = crc32_lsb512_next(crc_state, s_data, s_keep);
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
crc_state <= INIT;
end else if (fire) begin
if (s_last) begin
crc_state <= INIT;
end else begin
crc_state <= crc_next;
end
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
crc_value <= '0;
crc_valid <= 1'b0;
crc_ok <= 1'b0;
end else begin
crc_valid <= 1'b0;
if (fire && s_last) begin
crc_value <= crc_next ^ XOROUT;
crc_valid <= 1'b1;
if (mode_check) begin
if (CHECK_BY_RESIDUE) begin
crc_ok <= (crc_next == RESIDUE);
end else begin
crc_ok <= ((crc_next ^ XOROUT) == expected_crc);
end
end else begin
crc_ok <= 1'b0;
end
end
end
end
endmodule
上面的版本是“功能优先”的写法,易读、易仿真、易对齐软件模型。若频率目标较高,需要把 crc32_lsb512_next() 拆成多级 pipeline。
10.3 512b pipeline 版本框架
下面给出一个按 64-bit chunk 处理的 pipeline 框架。为了突出结构,代码只展示关键路径。实际项目中还需要加入 backpressure、bubble 处理和 packet 边界保护。
module crc32_512b_pipeline (
input logic clk,
input logic rst_n,
input logic [511:0] in_data,
input logic [63:0] in_keep,
input logic in_valid,
input logic in_last,
output logic [31:0] out_crc,
output logic out_valid
);
localparam logic [31:0] INIT = 32'hFFFF_FFFF;
localparam logic [31:0] XOROUT = 32'hFFFF_FFFF;
logic [31:0] crc_s0;
logic [31:0] crc_s1;
logic [31:0] crc_s2;
logic [31:0] crc_s3;
logic [31:0] crc_s4;
logic [31:0] crc_s5;
logic [31:0] crc_s6;
logic [31:0] crc_s7;
logic [31:0] crc_s8;
logic [511:0] data_s0;
logic [63:0] keep_s0;
logic valid_s0;
logic last_s0;
logic [6:0] valid_pipe;
logic [6:0] last_pipe;
function automatic logic [31:0] crc32_lsb1_next(
input logic [31:0] crc_state_i,
input logic data_bit_i
);
logic feedback;
logic [31:0] shifted;
begin
feedback = crc_state_i[0] ^ data_bit_i;
shifted = {1'b0, crc_state_i[31:1]};
crc32_lsb1_next = feedback ? (shifted ^ 32'hEDB88320) : shifted;
end
endfunction
function automatic logic [31:0] crc32_lsb8_next(
input logic [31:0] crc_state_i,
input logic [7:0] data_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int i = 0; i < 8; i++) begin
crc_tmp = crc32_lsb1_next(crc_tmp, data_i[i]);
end
crc32_lsb8_next = crc_tmp;
end
endfunction
function automatic logic [31:0] crc32_lsb64_next(
input logic [31:0] crc_state_i,
input logic [63:0] data_i,
input logic [7:0] keep_i
);
logic [31:0] crc_tmp;
begin
crc_tmp = crc_state_i;
for (int byte_idx = 0; byte_idx < 8; byte_idx++) begin
if (keep_i[byte_idx]) begin
crc_tmp = crc32_lsb8_next(
crc_tmp,
data_i[byte_idx*8 +: 8]
);
end
end
crc32_lsb64_next = crc_tmp;
end
endfunction
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
data_s0 <= '0;
keep_s0 <= '0;
valid_s0 <= 1'b0;
last_s0 <= 1'b0;
valid_pipe <= '0;
last_pipe <= '0;
end else begin
data_s0 <= in_data;
keep_s0 <= in_keep;
valid_s0 <= in_valid;
last_s0 <= in_last;
valid_pipe <= {valid_pipe[5:0], in_valid};
last_pipe <= {last_pipe[5:0], in_last};
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
crc_s0 <= INIT;
crc_s1 <= INIT;
crc_s2 <= INIT;
crc_s3 <= INIT;
crc_s4 <= INIT;
crc_s5 <= INIT;
crc_s6 <= INIT;
crc_s7 <= INIT;
crc_s8 <= INIT;
end else if (valid_s0) begin
crc_s1 <= crc32_lsb64_next(crc_s0, data_s0[ 63: 0], keep_s0[ 7: 0]);
crc_s2 <= crc32_lsb64_next(crc_s1, data_s0[127: 64], keep_s0[15: 8]);
crc_s3 <= crc32_lsb64_next(crc_s2, data_s0[191:128], keep_s0[23:16]);
crc_s4 <= crc32_lsb64_next(crc_s3, data_s0[255:192], keep_s0[31:24]);
crc_s5 <= crc32_lsb64_next(crc_s4, data_s0[319:256], keep_s0[39:32]);
crc_s6 <= crc32_lsb64_next(crc_s5, data_s0[383:320], keep_s0[47:40]);
crc_s7 <= crc32_lsb64_next(crc_s6, data_s0[447:384], keep_s0[55:48]);
crc_s8 <= crc32_lsb64_next(crc_s7, data_s0[511:448], keep_s0[63:56]);
if (last_pipe[6]) begin
crc_s0 <= INIT;
end else begin
crc_s0 <= crc_s8;
end
end
end
always_ff @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
out_crc <= '0;
out_valid <= 1'b0;
end else begin
out_valid <= valid_pipe[6] && last_pipe[6];
if (valid_pipe[6] && last_pipe[6]) begin
out_crc <= crc_s8 ^ XOROUT;
end
end
end
endmodule
这个框架表达的是“按 64-bit 段切 pipeline”的思想。真实高频实现中,data_s0 也需要随 pipeline 分段寄存,否则后级仍然引用同一拍输入数据,容易出现数据对齐问题。更严谨的版本应将每一段尚未处理的数据和 keep 继续向后传递。
10.4 生成端与校验端数据流
生成模式:
packet payload -> crc32 generator -> crc_value
MAC / packetizer append crc_value
校验模式方法一:
packet payload -> crc32 generator -> calc_crc
packet crc field -> expected_crc
calc_crc == expected_crc
校验模式方法二:
packet payload || packet crc field -> crc32 checker
final_state == residue
11 tkeep 与 partial packet
11.1 为什么需要 keep
512-bit datapath 每拍最多传输 64 Byte,但 packet 长度不一定是 64 Byte 的整数倍。最后一拍通常只有部分 byte 有效,因此需要 keep 指示哪些 byte 参与 CRC。
packet length = 70 Byte
beat0: keep = 64'hFFFF_FFFF_FFFF_FFFF
beat1: keep = 64'h0000_0000_0000_003F // 6 Byte valid
11.2 keep 必须连续吗
对 AXI4-Stream packet,常见约定是:
- 非 last beat:
keep全 1; - last beat:
keep从 byte0 开始连续为 1; - 不允许中间有 hole,例如
8'b1011_1111。
如果协议允许 sparse keep,则 CRC 函数必须按照 byte index 顺序跳过无效 byte。但很多 packet 协议不允许 sparse keep,因为它会使 packet byte stream 定义复杂化。
11.3 keep 检查逻辑
function automatic logic keep_is_contiguous(
input logic [63:0] keep
);
logic seen_zero;
begin
seen_zero = 1'b0;
keep_is_contiguous = 1'b1;
for (int i = 0; i < 64; i++) begin
if (!keep[i]) begin
seen_zero = 1'b1;
end else if (seen_zero) begin
keep_is_contiguous = 1'b0;
end
end
end
endfunction
在 generator 中可以把非法 keep 当作 protocol error;在 checker 中也可以把非法 keep 直接判 fail。
12 验证建议
12.1 标准 check value
CRC-32/ISO-HDLC 的标准测试向量是字符串 "123456789":
input = 31 32 33 34 35 36 37 38 39
crc32 = 0xCBF43926
任何 CRC32 RTL 首先都应该通过这个测试。
12.2 Python 参考模型
import zlib
import struct
def crc32_ref(data: bytes) -> int:
return zlib.crc32(data) & 0xffffffff
def append_crc32_le(data: bytes) -> bytes:
crc = crc32_ref(data)
return data + struct.pack("<I", crc)
def check_crc32_compare(frame: bytes) -> bool:
payload = frame[:-4]
recv_crc = struct.unpack("<I", frame[-4:])[0]
return crc32_ref(payload) == recv_crc
data = b"123456789"
assert crc32_ref(data) == 0xCBF43926
frame = append_crc32_le(data)
assert check_crc32_compare(frame)
12.3 SystemVerilog testbench 框架
module tb_crc32_512b_packet;
logic clk;
logic rst_n;
logic [511:0] s_data;
logic [63:0] s_keep;
logic s_valid;
logic s_ready;
logic s_last;
logic mode_check;
logic [31:0] expected_crc;
logic [31:0] crc_value;
logic crc_valid;
logic crc_ok;
crc32_512b_packet dut (
.clk (clk),
.rst_n (rst_n),
.s_data (s_data),
.s_keep (s_keep),
.s_valid (s_valid),
.s_ready (s_ready),
.s_last (s_last),
.mode_check (mode_check),
.expected_crc (expected_crc),
.crc_value (crc_value),
.crc_valid (crc_valid),
.crc_ok (crc_ok)
);
initial begin
clk = 1'b0;
forever #1 clk = ~clk;
end
task automatic drive_one_packet_9byte;
begin
@(posedge clk);
s_valid <= 1'b1;
s_last <= 1'b1;
s_keep <= 64'h0000_0000_0000_01FF;
s_data <= '0;
s_data[ 7: 0] <= 8'h31;
s_data[15: 8] <= 8'h32;
s_data[23:16] <= 8'h33;
s_data[31:24] <= 8'h34;
s_data[39:32] <= 8'h35;
s_data[47:40] <= 8'h36;
s_data[55:48] <= 8'h37;
s_data[63:56] <= 8'h38;
s_data[71:64] <= 8'h39;
@(posedge clk);
s_valid <= 1'b0;
s_last <= 1'b0;
s_keep <= '0;
s_data <= '0;
end
endtask
initial begin
rst_n = 1'b0;
s_data = '0;
s_keep = '0;
s_valid = 1'b0;
s_last = 1'b0;
mode_check = 1'b0;
expected_crc = 32'h0;
repeat (5) @(posedge clk);
rst_n = 1'b1;
drive_one_packet_9byte();
wait (crc_valid);
assert (crc_value == 32'hCBF4_3926)
else $fatal("CRC mismatch: got %08x", crc_value);
repeat (10) @(posedge clk);
$finish;
end
endmodule
12.4 验证 checklist
[ ] reset 后 CRC state 是否等于 seed
[ ] "123456789" 是否得到 0xCBF43926
[ ] 1 Byte packet 是否正确
[ ] 63 Byte packet 是否正确
[ ] 64 Byte packet 是否正确
[ ] 65 Byte packet 是否正确
[ ] 全 0 packet 是否正确
[ ] 全 1 packet 是否正确
[ ] 随机长度 packet 是否与 Python zlib.crc32 一致
[ ] 连续 packet 是否每包重新加载 seed
[ ] tkeep 最后一拍是否正确
[ ] 非法 sparse keep 是否被检测
[ ] checker 是否能发现单 bit 错误
[ ] checker 是否能发现 burst error
[ ] CRC 字段 byte order 是否与协议一致
[ ] pipeline valid/last/keep 是否对齐
13 常见错误
| 问题 | 常见原因 | 调试方法 |
|---|---|---|
| CRC 与软件不一致 | RefIn/RefOut 搞反 | 先用 "123456789" 对齐 |
| 只有多 byte packet 错 | byte order 错 | 打印每个 byte 进入 CRC 的顺序 |
| 只有最后一拍错 | tkeep 处理错 | 测试 1、63、64、65 Byte |
| 连续 packet 第二包错 | 没有重新加载 seed | 检查 SOP / last 后 state |
| checker 总是 fail | expected_crc endian 错 | 检查 CRC 字段存储顺序 |
| residue 法不通过 | 把 final xor 后的值又送入内部状态 | 明确 internal state 与 output crc |
| 高速综合不过 | 512-bit XOR tree 太深 | 分段、平衡 XOR、插 pipeline |
| pipeline 后结果错 | valid/last/keep 未对齐 | 在波形中标记 packet_id |
14 架构分析 Checklist
做 CRC IP 架构评审时,可以按下面的 checklist 逐项确认。
[ ] CRC 标准是否明确:width/poly/init/refin/refout/xorout/residue
[ ] polynomial 是否来自标准或经过检错能力分析
[ ] 输入 byte order 是否定义清楚
[ ] byte 内 bit order 是否定义清楚
[ ] LFSR 使用 normal 还是 reflected polynomial
[ ] seed 加载时机是否和 packet start 对齐
[ ] output invert 是否只做一次
[ ] generator 和 checker 是否使用同一套参数
[ ] checker 使用 compare 法还是 residue 法
[ ] 512b 并行展开是否满足时序
[ ] pipeline latency 是否写入接口文档
[ ] valid/last/keep 是否逐级对齐
[ ] tkeep 是否只允许 last beat partial
[ ] 是否支持 backpressure
[ ] 是否允许连续 packet back-to-back
[ ] 是否需要多 packet context
[ ] 是否有软件 golden model
[ ] 是否覆盖标准 check value
15 推荐练习
15.1 练习一:CRC-8 串行实现
要求:
- polynomial 使用
0x07; - 每拍处理 1 bit;
- 支持
clear重新加载 seed; - 写 testbench 手工对比模 2 除法结果。
15.2 练习二:CRC32 8-bit 并行实现
要求:
- CRC-32/ISO-HDLC;
- 每拍处理 1 Byte;
- 对
"123456789"输出0xCBF43926; - 支持连续 packet。
15.3 练习三:CRC32 64-bit 并行实现
要求:
- 每拍处理 8 Byte;
- 支持
keep[7:0]; - 覆盖 1 到 128 Byte 的随机 packet;
- 与 Python
zlib.crc32对比。
15.4 练习四:CRC32 512-bit 并行生成 + 校验
要求:
- 每拍处理 64 Byte;
- 支持生成模式;
- 支持校验模式;
- 支持 partial last beat;
- 插入 pipeline 后仍保持结果正确;
- 随机注入单 bit 错误,checker 必须报错。
16 总结
CRC 是数字系统中非常典型的“数学简单、工程细节复杂”的模块。它的核心是 GF(2) 多项式除法,硬件实现通常是 LFSR;但真正容易出错的是 polynomial 选择、bit 顺序、seed、invert、CRC 字段 byte order、partial packet 和 pipeline 对齐。
对 RTL 设计而言,建议采用如下路线:
先固定 CRC 参数
再固定 byte order 和 bit order
先实现 1-bit 串行模型
再扩展 8-bit / 64-bit 并行
最后实现 512-bit pipeline
全程使用软件 golden model 对比
对小项目“CRC32 64B/512b 并行生成 + 校验”,最重要的不是一开始就写出最优 XOR 方程,而是先把 packet 级行为定义清楚:每个 byte 以什么顺序进入 CRC,何时加载 seed,何时输出 invert 后的 CRC,最后一拍哪些 byte 有效,以及 checker 用 compare 法还是 residue 法。只要这些 convention 固定,后续无论是自动生成并行方程,还是插入 pipeline 优化时序,都有明确的参考基准。
17 参考资料
- CRC Catalogue:https://reveng.sourceforge.io/crc-catalogue/
- Ross N. Williams, A Painless Guide to CRC Error Detection Algorithms
- IEEE 802.3 Ethernet CRC-32 相关章节
- pycrc:https://pycrc.org/
- zlib crc32 software reference
- Xilinx / AMD Parallel CRC Generation 相关应用笔记
- Intel FPGA CRC implementation 相关应用笔记
