1 前言
上一篇《以太网基础知识:从帧格式、MAC地址到交换机转发》已经建立了以太网的基础框架:网络分层、以太网帧格式、MAC 地址、ARP、交换机转发、VLAN、STP、LACP、QoS、Wireshark 抓包以及 MAC/PHY/Switch ASIC 的基本概念。
如果继续从硬件或芯片设计角度深入学习,以太网就不再只是“一个二层协议”,而是一条从 bit 级物理传输 到 packet 级高速转发 的完整数据通路:
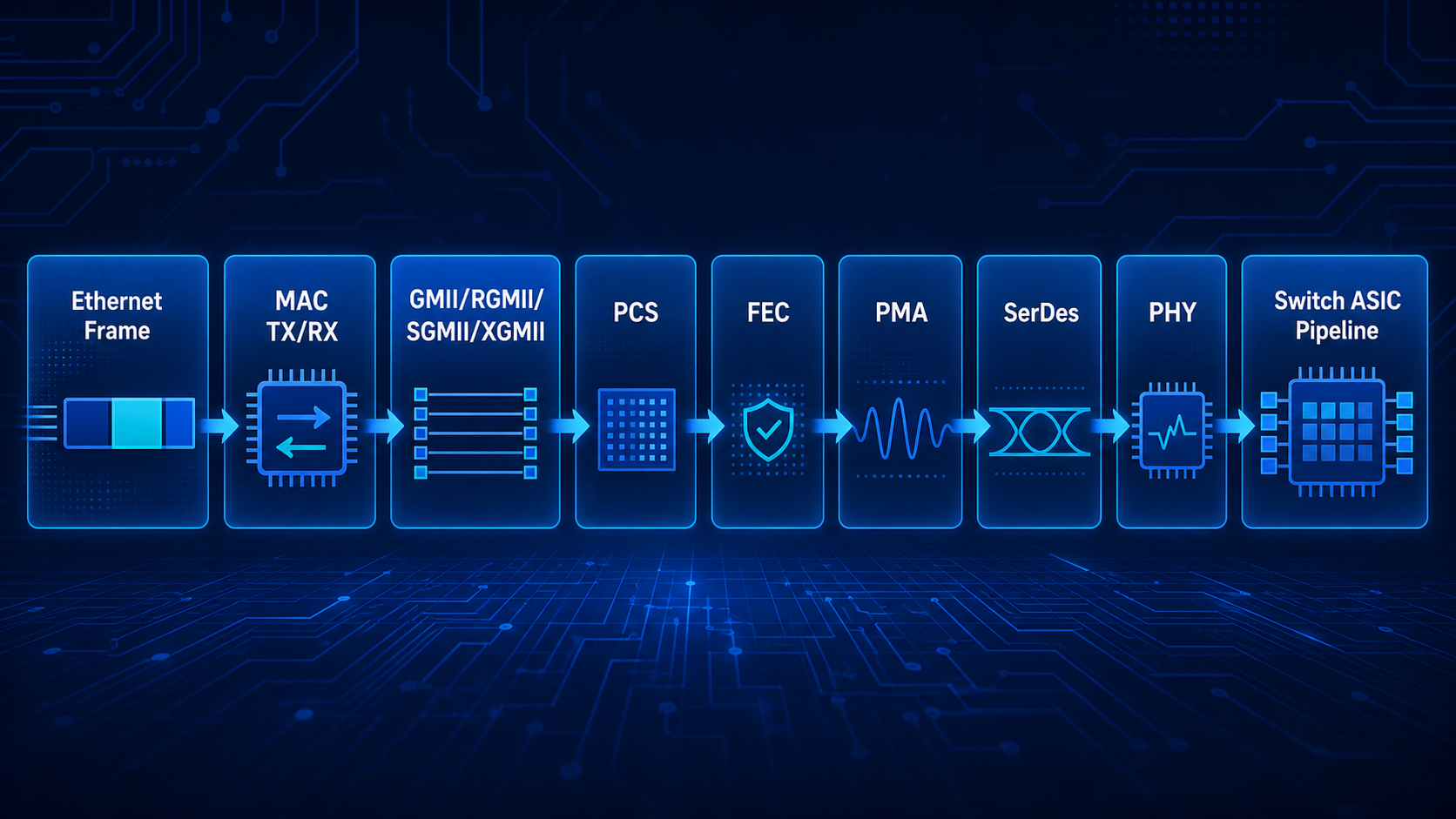
本文只关注 硬件/芯片方向,目标是回答三个问题:
- 如果要设计 Ethernet MAC,需要学习哪些内容?
- 如果要理解 PHY、PCS、SerDes,需要掌握哪些物理层知识?
- 如果要进一步学习 Switch ASIC,需要从哪些模块切入?
本文不是 IEEE 802.3 标准的逐条解释,而是一份面向 RTL/ASIC/FPGA 工程师的以太网硬件学习大纲和技术地图。
2 从硬件角度重新理解以太网
从网络协议角度看,以太网主要处理 frame;从芯片角度看,以太网是一条高速数据通路。一个 packet 进入芯片后,需要经历接收、校验、解析、查表、缓存、调度、修改和发送。
RX Pins / SerDes
-> PHY / PMA
-> PCS
-> MAC RX
-> Packet Parser
-> Lookup / ACL / QoS
-> Buffer / Queue
-> Scheduler
-> Egress Edit
-> MAC TX
-> PCS
-> PMA / PHY
-> TX Pins / SerDes
上面这条路径中有几个容易混淆的模块,先做一个简单解释:
| 模块 | 简单理解 | 主要作用 |
|---|---|---|
| PMA | Physical Medium Attachment,靠近 SerDes 的物理适配层 | 负责串并转换、时钟恢复、lane 映射等更接近高速串行链路的工作 |
| PCS | Physical Coding Sublayer,物理编码子层 | 负责编码/解码、扰码/解扰、block lock、lane alignment、FEC 等,使 MAC 数据适合高速传输 |
| Parser | 报文解析器 | 从 packet 中提取目的 MAC、源 MAC、VLAN、EtherType、IP、TCP/UDP 端口等字段,生成后续查表需要的 metadata |
| Lookup | 查表模块 | 根据 Parser 提取的字段查询 MAC 表、VLAN 表、路由表、ACL 表等,决定 packet 的转发路径和处理动作 |
| ACL | Access Control List,访问控制列表 | 根据报文字段匹配规则,执行丢弃、放行、重定向、镜像、计数、限速等动作 |
| QoS | Quality of Service,服务质量 | 根据优先级、流量类型或拥塞状态,把 packet 分到不同队列,并决定调度、限速、丢弃或标记策略 |
| Egress | 出方向处理流水线 | 在 packet 发出前完成 VLAN tag 修改、MAC rewrite、TTL 更新、checksum 更新、timestamp 插入等操作 |
可以简单记成:PCS/PMA 负责把 bit 在物理链路上可靠传输,Parser/Lookup/ACL/QoS 负责决定 packet 在芯片里怎么走,Egress 负责 packet 出端口前的最后修改。
因此,以太网硬件学习可以拆成四个层次:
| 层次 | 关注点 | 典型模块 |
|---|---|---|
| 帧处理层 | 以太网帧如何收发、校验和对齐 | MAC TX、MAC RX、CRC、Padding、IFG |
| 接口层 | MAC 和 PHY/PCS 如何传输数据 | MII、GMII、RGMII、SGMII、XGMII |
| 物理编码层 | bit 如何编码、对齐、纠错、串并转换 | PCS、FEC、PMA、SerDes |
| 交换芯片层 | packet 如何被解析、查表、缓存和调度 | Parser、Lookup、Buffer、Queue、Scheduler |
如果是 FPGA 入门,可以先从 MAC + RGMII/SGMII + UDP/ARP 实验开始;如果是 ASIC/Switch 芯片方向,则需要进一步理解大带宽、多端口、多 pipeline、共享 buffer、QoS 和拥塞控制。
3 Ethernet MAC:硬件学习的第一个核心模块
Ethernet MAC 是以太网硬件系统中最适合作为起点的模块。它处于二层协议和物理层接口之间,既要理解帧格式,也要考虑 RTL 数据流、CRC、时钟、反压和错误处理。
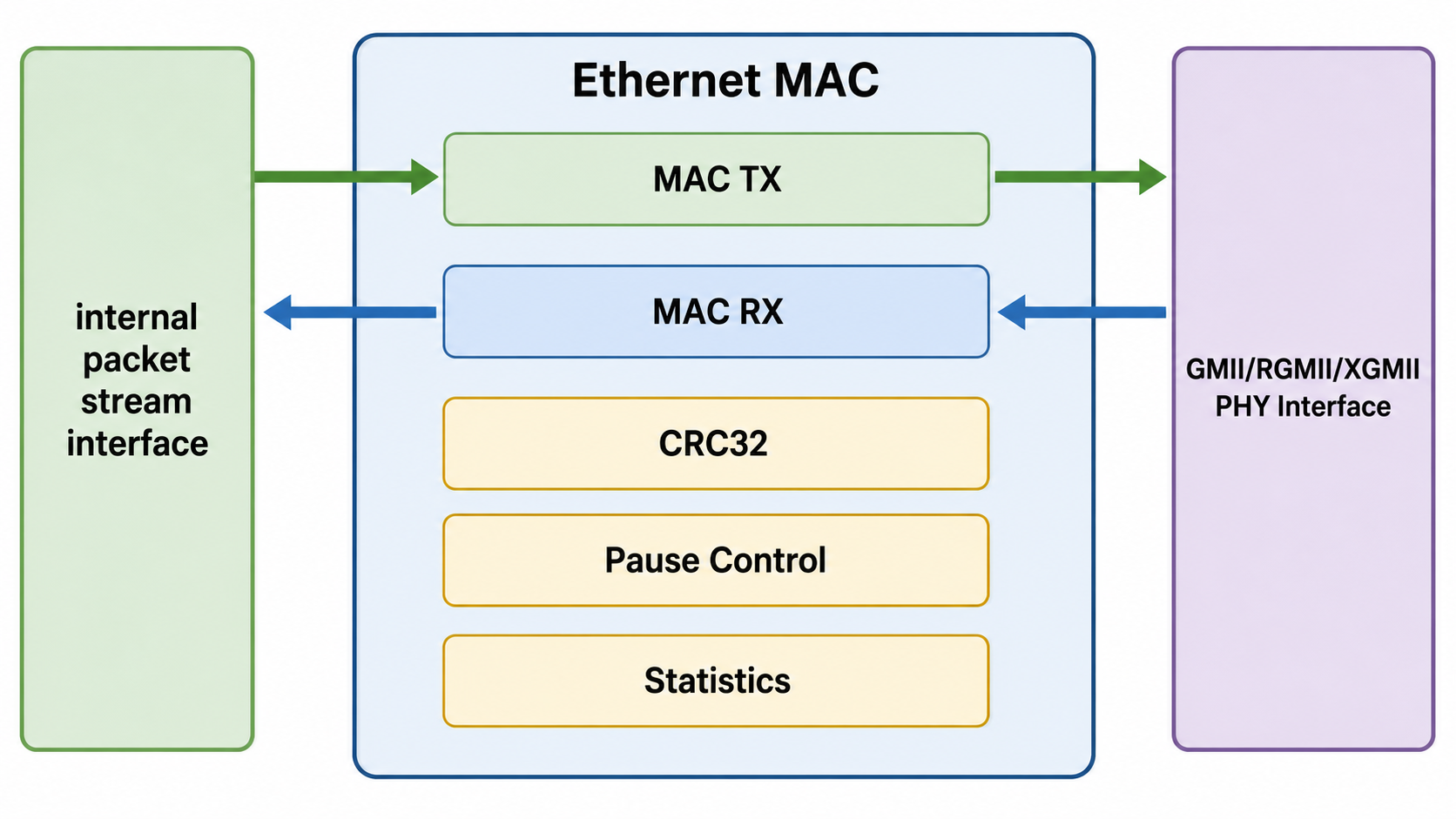
3.1 MAC 的位置
Packet Stream / DMA / Switch Pipeline
|
| internal packet interface
v
Ethernet MAC
|
| GMII / RGMII / SGMII / XGMII
v
PHY / PCS / SerDes
MAC 通常分为 TX 和 RX 两个方向:
| 模块 | 主要职责 |
|---|---|
| MAC TX | 接收内部 packet stream,插入 Preamble/SFD,补齐 Padding,计算并追加 FCS,控制 IFG |
| MAC RX | 从 PHY 接口接收字节流,检测 Preamble/SFD,恢复 frame,校验 FCS,过滤错误帧 |
| MAC Control | 处理 Pause Frame、PFC、速率配置、地址过滤等控制功能 |
| Statistics | 统计收发包数、字节数、CRC error、runt、jabber、pause frame 等 |
3.2 MAC TX 数据通路
MAC TX 的输入通常是内部 packet stream,例如 AXI-Stream 或自定义 valid/ready 接口。一个典型发送流程如下:
等待 SOP
-> 接收 Destination MAC / Source MAC / EtherType / Payload
-> 插入 Preamble 和 SFD
-> 发送 Frame Body
-> 如果长度不足则插入 Padding
-> 计算并追加 FCS
-> 插入 IFG
-> 等待下一帧
MAC TX 需要重点学习:
| 主题 | 说明 |
|---|---|
| Preamble/SFD | 发送端插入 55 55 55 55 55 55 55 D5 |
| IFG | Inter Frame Gap,标准以太网帧间隔 |
| Padding | Payload 不足时补齐到最小帧长 |
| FCS | 发送时计算 Ethernet CRC32 并追加 |
| Backpressure | 下游 PHY 或 PCS 不可接收时如何暂停 |
| Underrun | 发送过程中上游数据断流时如何处理 |
RTL 设计时,MAC TX 通常是一个状态机:
IDLE
-> PREAMBLE
-> SFD
-> DATA
-> PAD
-> FCS
-> IFG
-> IDLE
3.3 MAC RX 数据通路
MAC RX 的任务是把 PHY 接口上的字节流恢复成内部 packet stream。典型流程如下:
检测 Preamble
-> 检测 SFD
-> 接收 Frame Body
-> 统计长度
-> 计算 CRC32
-> 接收 FCS
-> 比较 CRC
-> 输出 packet 或丢弃错误帧
MAC RX 需要重点关注:
| 主题 | 说明 |
|---|---|
| Preamble 检测 | 判断帧开始前导码是否正确 |
| SFD 检测 | 根据 0xD5 确定有效帧开始 |
| FCS 校验 | 判断传输过程中是否发生 bit 错误 |
| Runt Frame | 小于最小帧长的异常帧 |
| Jabber Frame | 超过最大允许长度的异常帧 |
| Alignment Error | 非法对齐或字节边界错误 |
| Address Filter | 根据目的 MAC 判断是否接收 |
3.4 MAC 中的统计计数器
商用 MAC 通常会包含大量统计计数器,用于驱动、交换机 SDK 或调试系统读取。
常见计数器包括:
- RX good packets;
- TX good packets;
- RX good bytes;
- TX good bytes;
- CRC error;
- runt frame;
- jabber frame;
- pause frame;
- multicast frame;
- broadcast frame;
- undersize / oversize frame;
- dropped packet。
这些计数器对芯片 bring-up 和网络排障非常重要。例如,如果链路 up 但大量 CRC error,通常需要怀疑 PHY、SerDes、线缆、时钟或信号完整性问题。
4 CRC32/FCS:MAC 设计中的关键细节
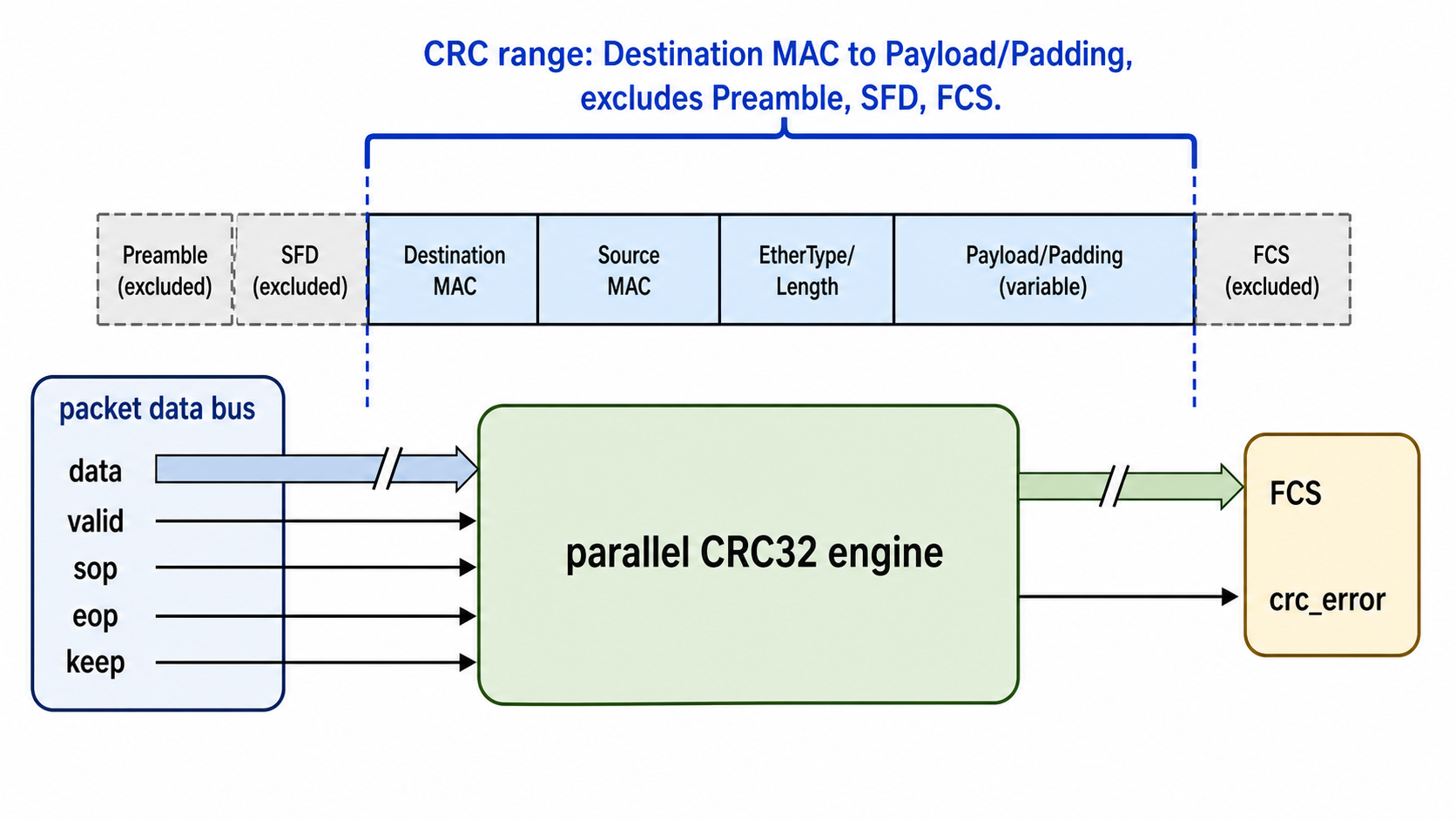
FCS(Frame Check Sequence)是以太网帧尾部的 4 Byte 校验字段,通常使用 Ethernet CRC32。虽然 CRC 在概念上不复杂,但在硬件实现中很容易因为 bit order、byte order、初值和异或方式出错。
4.1 Ethernet CRC32 基本参数
| 项目 | Ethernet CRC32 |
|---|---|
| 多项式 | 0x04C11DB7 |
| 初始值 | 0xFFFFFFFF |
| 输入 bit 顺序 | LSB first |
| 输出处理 | final xor |
| FCS 长度 | 4 Bytes |
| 校验范围 | Destination MAC 到 Payload/Padding,不包括 Preamble/SFD 和 FCS 自身 |
在 RTL 中,CRC 可以串行计算,也可以并行计算。低速 MAC 可以每拍处理 8 bit,高速 MAC 通常需要每拍处理 32/64/128/256/512 bit 甚至更宽。
4.2 并行 CRC
并行 CRC 是以太网 MAC RTL 中非常常见的模块。它的输入数据宽度通常与内部 datapath 宽度一致。
| Datapath 宽度 | 常见场景 |
|---|---|
| 8 bit | 10/100M、简单教学 MAC |
| 32 bit | GMII 相关低速设计 |
| 64 bit | 10G XGMII |
| 256 bit | 中高端交换芯片内部 datapath |
| 512 bit | 高吞吐 Switch ASIC pipeline |
并行 CRC 设计要处理 EOP 最后一拍的有效 byte 数,因此常与 tkeep、empty 或 byte_valid 信号配合使用。
4.3 常见错误点
学习和实现 Ethernet CRC 时,需要特别注意:
- Preamble 和 SFD 不参与 CRC;
- FCS 字段自身不参与 CRC;
- Ethernet CRC 输入 bit 顺序是 reflected 的;
- FCS 在以太网上发送时的 byte 顺序容易和寄存器显示顺序相反;
- 最后一拍不足完整总线宽度时,要根据有效 byte mask 计算;
- VLAN Tag、Padding 都属于 CRC 计算范围;
- 如果 MAC RX 剥离 FCS,内部 packet length 是否包含 FCS 要统一定义。
5 MAC-PHY 接口:从并行总线到高速串行接口
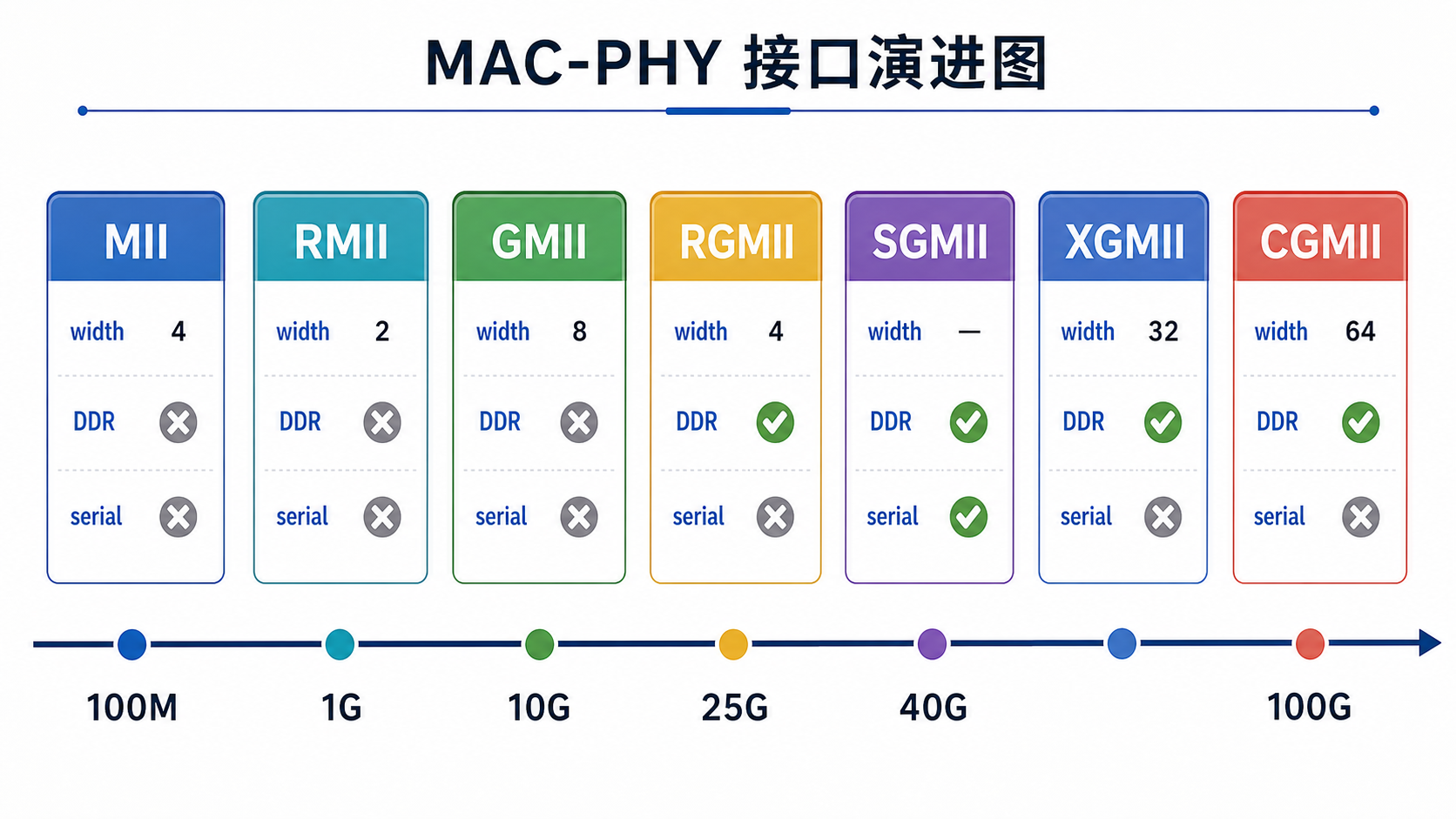
MAC 和 PHY/PCS 之间需要通过标准接口传输数据。不同速率、不同应用场景会使用不同接口。
5.1 常见接口总览
| 接口 | 典型速率 | 数据形式 | 典型应用 |
|---|---|---|---|
| MII | 10/100M | 4-bit 并行 | 早期低速以太网 |
| RMII | 10/100M | 2-bit 并行 | 低引脚数 MCU/SoC |
| GMII | 1G | 8-bit 并行 | 千兆 MAC/PHY |
| RGMII | 1G | 4-bit DDR | 低引脚数千兆接口 |
| SGMII | 1G | 串行 | MAC 与 PHY 间高速串行 |
| XGMII | 10G | 32/64-bit 并行 | 10G MAC 与 PCS |
| XLGMII | 40G | 宽并行 | 40G Ethernet |
| CGMII | 100G | 宽并行 | 100G Ethernet |
5.2 GMII
GMII 是千兆以太网中常见的 MAC-PHY 接口,每个方向 8 bit 数据,配合独立时钟和控制信号。
典型 GMII 信号包括:
| 信号 | 方向 | 说明 |
|---|---|---|
| GTX_CLK | MAC -> PHY | TX 125 MHz clock |
| TXD[7:0] | MAC -> PHY | 发送数据 |
| TX_EN | MAC -> PHY | 发送数据有效 |
| TX_ER | MAC -> PHY | 发送错误 |
| RX_CLK | PHY -> MAC | RX recovered clock |
| RXD[7:0] | PHY -> MAC | 接收数据 |
| RX_DV | PHY -> MAC | 接收数据有效 |
| RX_ER | PHY -> MAC | 接收错误 |
5.3 RGMII
RGMII 使用 4 bit DDR 数据总线,在时钟上升沿和下降沿各传 4 bit,从而减少引脚数量。RGMII 在 FPGA 和嵌入式 SoC 中非常常见。
RGMII 学习重点:
- DDR 输入输出;
- TXC/RXC 时钟关系;
- internal delay 与 external delay;
- PCB 走线 delay;
- timing constraint;
- setup/hold margin;
- 10/100/1000M 不同速率下的时钟行为。
5.4 SGMII
SGMII 是串行千兆接口,常用于 MAC 与 PHY 或交换芯片内部模块之间。它通常基于 1.25 Gbps 串行链路,并包含自协商能力。
SGMII 学习重点:
- 8B/10B 编码;
- comma detection;
- link synchronization;
- in-band auto-negotiation;
- speed indication;
- full/half duplex indication;
- PCS 与 SerDes 配合。
5.5 XGMII
XGMII 用于 10G Ethernet MAC 与 PCS 之间,通常为 32 bit 数据 + 4 bit control,或扩展为 64 bit 形式。
XGMII 引入了 data/control 字符的概念:
| 字符 | 含义 |
|---|---|
| Idle | 空闲字符 |
| Start | 帧开始 |
| Terminate | 帧结束 |
| Error | 错误字符 |
| Data | 正常数据字节 |
在 10G 及以上以太网中,MAC 不再简单地通过 TX_EN/RX_DV 表示有效数据,而是通过 control character 标记 packet 边界和空闲状态。
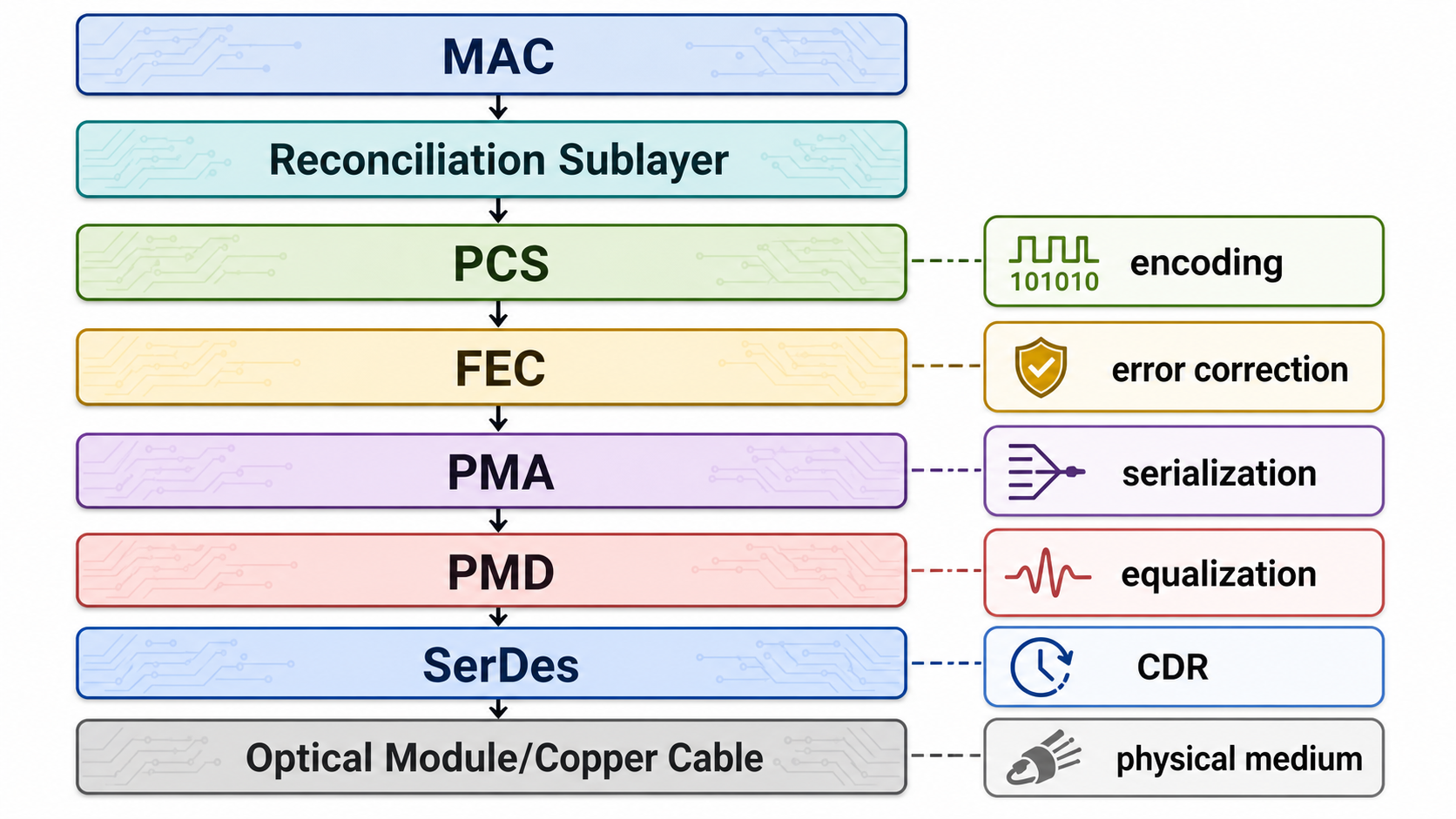
6 PCS、PMA、PMD 与 SerDes
在高速以太网中,MAC 后面通常不直接连接模拟物理介质,而是经过 PCS、PMA、PMD 等子层。
MAC
-> Reconciliation Sublayer
-> PCS
-> FEC
-> PMA
-> PMD
-> Medium
6.1 PCS
PCS 是 Physical Coding Sublayer,主要负责将 MAC 侧的数据转换为适合高速传输和恢复的编码流。
PCS 常见功能包括:
- 编码和解码;
- block lock;
- lane alignment;
- scrambling;
- descrambling;
- alignment marker 插入和删除;
- gearbox;
- FEC 编码和解码;
- link status 管理。
6.2 PMA
PMA 是 Physical Medium Attachment,更靠近 SerDes。它通常负责:
- 串并转换;
- CDR;
- lane mapping;
- bit mux/demux;
- 时钟恢复;
- 与 SerDes analog front-end 交互。
6.3 PMD
PMD 是 Physical Medium Dependent,和具体介质强相关,例如铜缆、背板、光模块。它处理的是更接近真实物理世界的问题:
- 电气信号;
- 光电转换;
- 连接器;
- 模块接口;
- 发射功率;
- 接收灵敏度;
- 介质相关的信号完整性。
6.4 SerDes
SerDes 是高速以太网芯片中的关键 IP。低速以太网可以使用并行接口,但 10G、25G、50G、100G、400G、800G 系统通常依赖高速 SerDes lane。
SerDes 学习重点:
| 主题 | 说明 |
|---|---|
| NRZ | 两电平信号,每个 symbol 表示 1 bit |
| PAM4 | 四电平信号,每个 symbol 表示 2 bit |
| CDR | Clock Data Recovery,从接收数据中恢复时钟 |
| PLL | 为高速串行链路提供时钟 |
| CTLE | 连续时间线性均衡 |
| DFE | 判决反馈均衡 |
| Pre-emphasis | 发送端预加重 |
| Eye Diagram | 观察链路裕量 |
| BER | Bit Error Rate,误码率 |
| Link Training | 链路训练,自动调整均衡参数 |
7 编码、扰码和 FEC
随着以太网速率提升,物理层编码和纠错变得越来越重要。不同速率标准可能使用不同编码方式。
7.1 常见编码方式
| 编码 | 常见场景 | 作用 |
|---|---|---|
| Manchester | 早期低速以太网 | 时钟恢复简单,但效率低 |
| 4B/5B | 100BASE-TX | 保证足够跳变 |
| 8B/10B | 1000BASE-X、SGMII | DC balance、comma 对齐 |
| 64B/66B | 10GBASE-R 等 | 高效率块编码 |
| 256B/257B | 更高速率场景 | 降低编码开销 |
| PAM4 | 50G lane 及以上 | 每个 symbol 传 2 bit |
7.2 Scrambler
扰码器用于打散数据模式,避免长时间连续 0 或连续 1,帮助时钟恢复并降低 EMI。扰码不是加密,而是让数据在统计上更随机。
学习重点:
- self-synchronous scrambler;
- descrambler;
- 多项式;
- 初始化;
- 错误扩散;
- 与 block lock 的关系。
7.3 FEC
FEC(Forward Error Correction)在高速以太网中非常重要。随着 PAM4 和高速 SerDes 的使用,链路原始误码率升高,需要通过 FEC 将误码率降低到系统可接受水平。
常见 FEC 相关概念:
- Reed-Solomon FEC;
- Firecode FEC;
- FEC encode/decode latency;
- corrected codeword;
- uncorrectable codeword;
- symbol error;
- FEC bypass;
- FEC 与链路延迟的权衡。
对芯片设计来说,FEC 不只是算法问题,还涉及面积、功耗、延迟和 throughput。
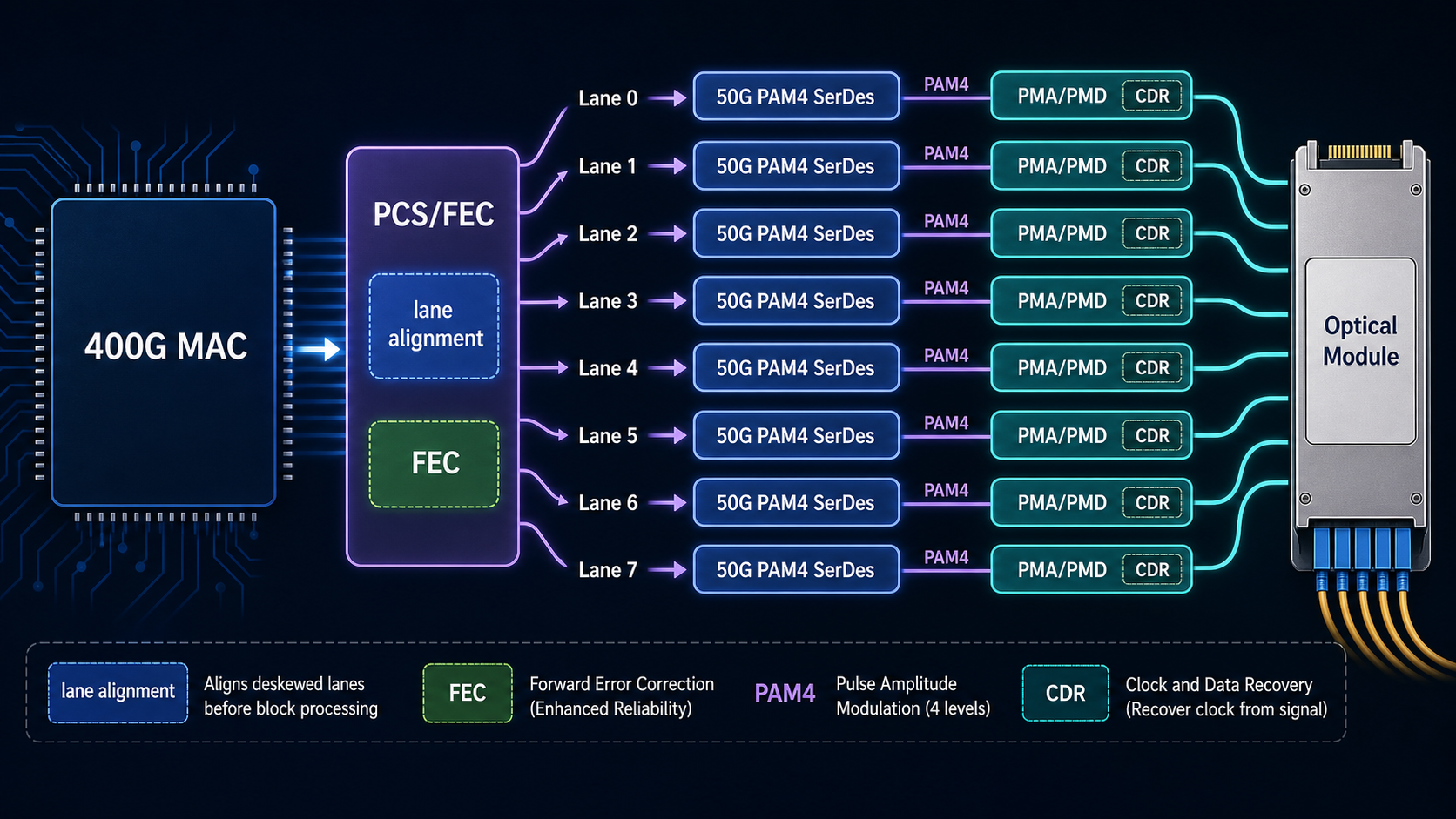
8 高速以太网速率演进
以太网速率演进不是简单地把时钟提高,而是通过多 lane 聚合、更高阶调制、更复杂编码和 FEC 共同实现。
| 标准 | 典型 lane 组合 | 说明 |
|---|---|---|
| 1G Ethernet | 1 lane | 千兆以太网 |
| 10G Ethernet | 1 × 10G | 10GBASE-R |
| 25G Ethernet | 1 × 25G | 服务器常见 |
| 40G Ethernet | 4 × 10G | 多 lane 聚合 |
| 100G Ethernet | 4 × 25G 或 2 × 50G | 数据中心常见 |
| 200G Ethernet | 4 × 50G | PAM4 常见 |
| 400G Ethernet | 8 × 50G 或 4 × 100G | 高端交换机 |
| 800G Ethernet | 8 × 100G | AI 集群和高端数据中心 |
学习高速以太网时,需要把“端口速率”和“lane 速率”区分开。例如一个 400G 端口可能由 8 条 50G lane 或 4 条 100G lane 组成。
8.1 Lane Alignment
多 lane 传输时,不同 lane 到达接收端的时间可能不同,因此 PCS 需要做 lane alignment。
核心概念:
- lane skew;
- alignment marker;
- deskew buffer;
- lane reorder;
- block lock;
- marker lock。
8.2 Gearbox
Gearbox 用于在不同数据宽度或不同时钟频率之间转换。例如 PCS 内部可能需要在 66-bit block 和 SerDes 数据宽度之间转换。
Gearbox 学习重点:
- ratio conversion;
- slip;
- block boundary;
- elastic buffer;
- latency;
- CDC 影响。
9 内部 Packet Stream 接口
MAC 与芯片内部模块之间通常不会直接传输 MII/GMII 信号,而是使用更适合芯片内部的 packet stream 接口。
9.1 常见信号
一个典型 packet stream 接口可能包含:
| 信号 | 含义 |
|---|---|
| data | 数据总线,例如 64/128/256/512 bit |
| valid | 当前 beat 有效 |
| ready | 下游可接收 |
| sop | Start of Packet |
| eop | End of Packet |
| keep / empty | 最后一拍哪些 byte 有效 |
| error | 当前 packet 是否异常 |
| user / metadata | 端口号、VLAN、QoS、timestamp 等附加信息 |
9.2 SOP/EOP 与变长包
以太网 packet 是变长的,而芯片内部 datapath 是定宽的。因此需要用 SOP/EOP 标记 packet 边界,用 keep/empty 表示最后一拍有效字节数。
Beat 0: SOP, data[511:0]
Beat 1: data[511:0]
Beat 2: EOP, data[511:0], keep = 64'b0000...1111
9.3 Backpressure
内部 packet stream 必须考虑反压。如果下游 FIFO 满、buffer 不足或 scheduler 暂停,上游需要停止发送或缓存 packet。
反压设计需要注意:
- 是否允许 packet 中间停顿;
- 是否要求 cut-through;
- 是否需要 skid buffer;
- 是否会导致 MAC TX underrun;
- 是否需要 credit-based flow control;
- packet 边界是否被破坏。
9.4 CDC
MAC、PHY、SerDes 和系统逻辑可能运行在不同 clock domain,因此 CDC 是以太网硬件设计的重点。
常见 CDC 场景:
- RX clock 到 system clock;
- system clock 到 TX clock;
- SerDes recovered clock 到 PCS clock;
- management clock 到 datapath clock;
- statistics counter 跨时钟读取。
常见解决方法:
- asynchronous FIFO;
- dual-clock packet FIFO;
- gray code pointer;
- toggle synchronizer;
- handshake synchronizer;
- counter snapshot。
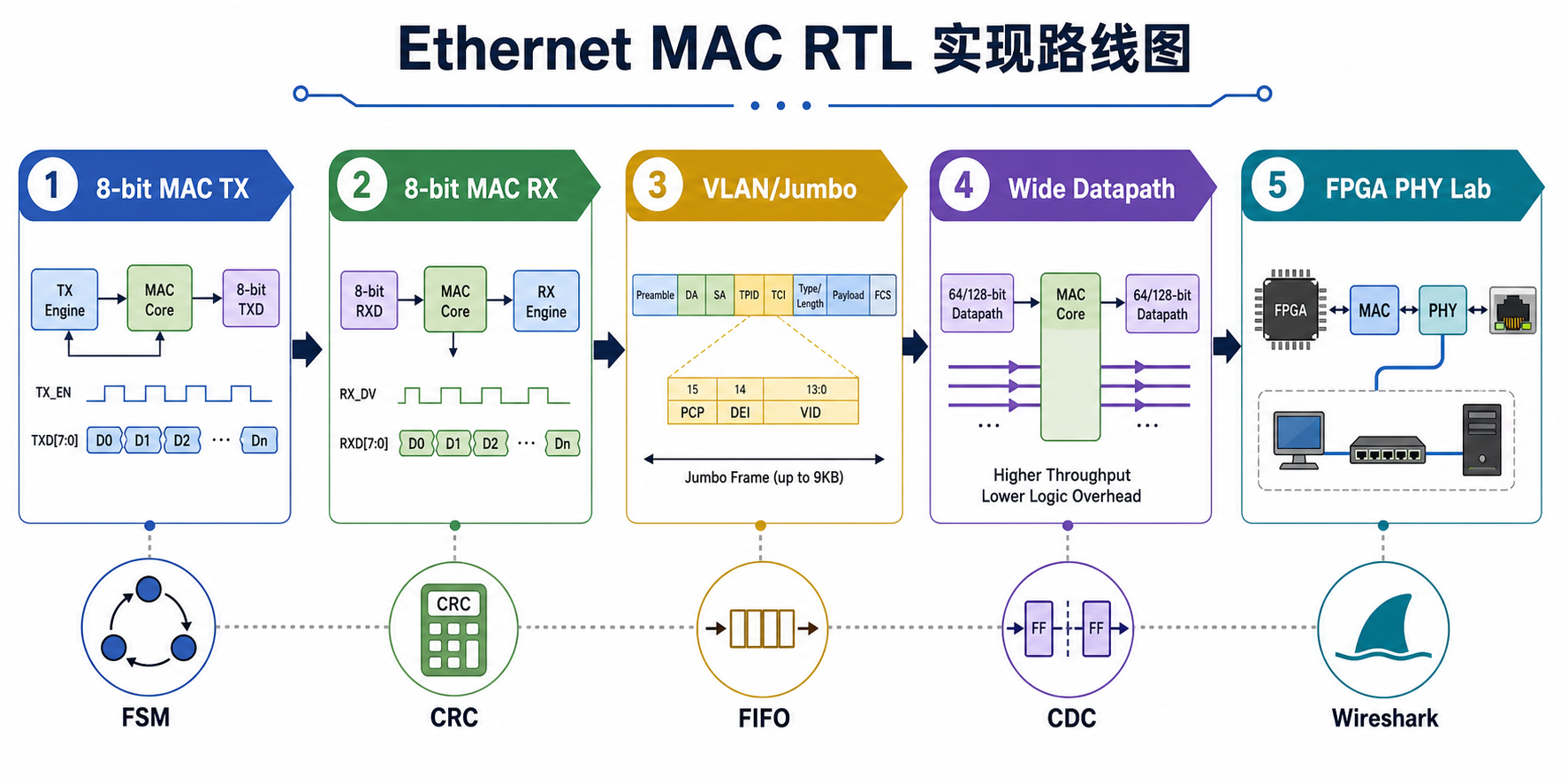
10 Ethernet MAC RTL 实现学习路线
如果目标是能够自己写一个简化 Ethernet MAC,建议按下面顺序实现。
10.1 第一阶段:8-bit 简化 MAC TX
目标:
输入一段 Ethernet frame body
-> 自动插入 Preamble/SFD
-> 自动计算 FCS
-> 输出完整 PHY byte stream
需要实现:
- TX FSM;
- byte counter;
- IFG counter;
- CRC32 serial/8-bit parallel;
- padding;
- packet input handshake。
10.2 第二阶段:8-bit 简化 MAC RX
目标:
从 PHY byte stream 接收数据
-> 检测 SFD
-> 提取 frame body
-> 校验 FCS
-> 输出 packet stream
需要实现:
- preamble detector;
- SFD detector;
- RX FSM;
- length checker;
- CRC checker;
- error flag;
- packet output handshake。
10.3 第三阶段:支持 VLAN 和 Jumbo Frame
继续增加:
- VLAN Tag 识别;
- EtherType 解析;
- 最大长度配置;
- Jumbo frame;
- runt/jabber 统计;
- address filter。
10.4 第四阶段:支持宽数据总线
将 8-bit datapath 扩展为:
- 32-bit;
- 64-bit;
- 128-bit;
- 256-bit;
- 512-bit。
重点解决:
- SOP/EOP 对齐;
- keep/empty;
- parallel CRC;
- barrel shifter;
- unaligned packet;
- multi-segment packet interface。
10.5 第五阶段:接入真实 PHY 或 FPGA IP
实验方向:
- GMII loopback;
- RGMII PHY bring-up;
- SGMII PCS/PMA;
- UDP echo;
- ARP responder;
- ICMP ping responder;
- Wireshark 抓包验证;
- iperf 测试吞吐。
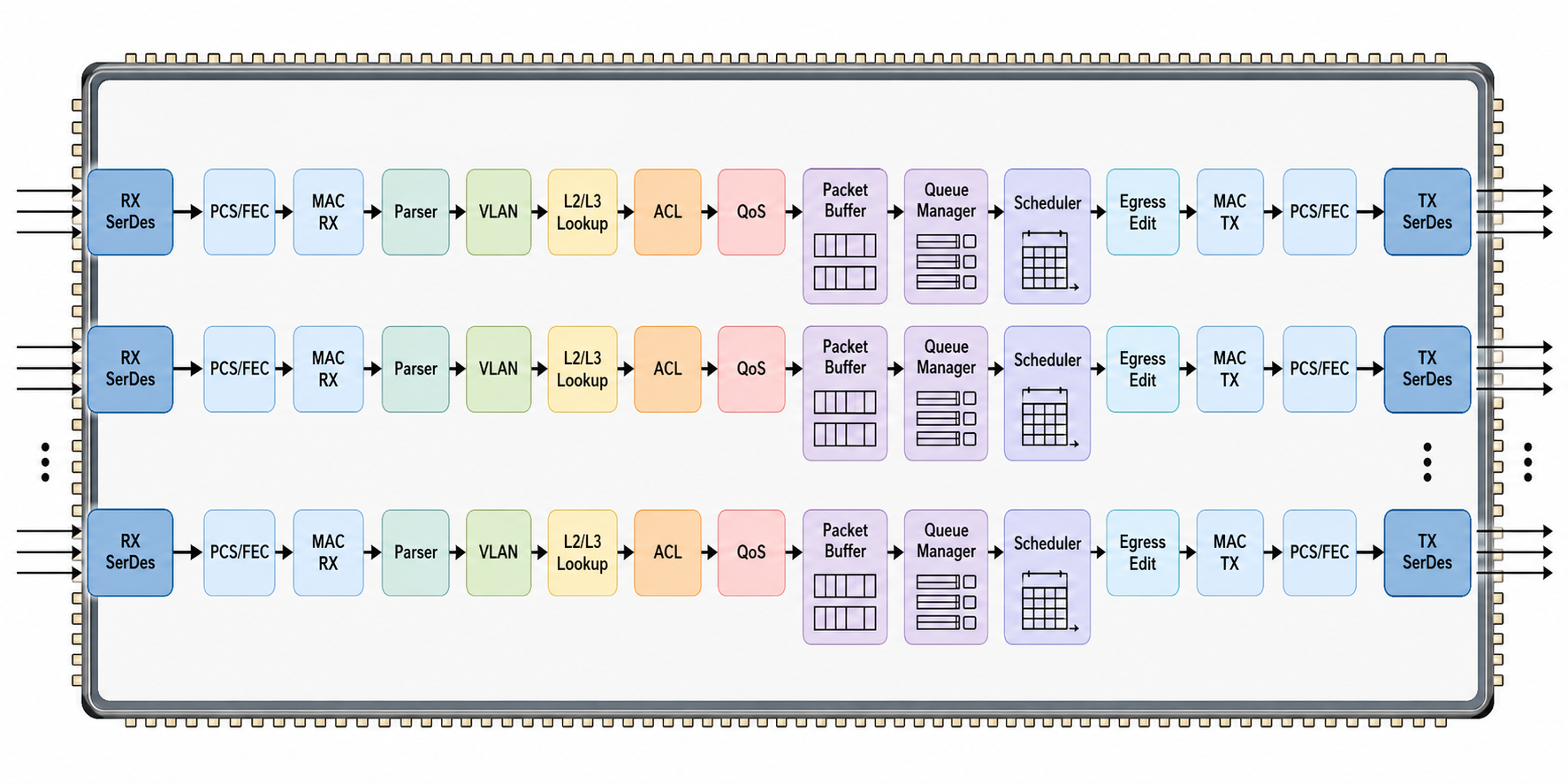
11 Switch ASIC 数据通路
当学习目标从单个 MAC 扩展到交换芯片时,重点就从“如何收发一帧”变成“如何在多端口、多队列、高吞吐下转发大量 packet”。
一个简化 Switch ASIC pipeline 如下:
RX SerDes
-> PCS / FEC
-> MAC RX
-> Parser
-> VLAN Classification
-> L2 Lookup
-> L3 Lookup
-> ACL
-> QoS Classification
-> Packet Buffer
-> Queue Manager
-> Scheduler
-> Egress Modification
-> MAC TX
-> PCS / FEC
-> TX SerDes
11.1 Parser
Parser 用于从 packet 中提取字段,生成后续查表和处理所需的 metadata。
常见解析字段:
- Destination MAC;
- Source MAC;
- VLAN Tag;
- EtherType;
- IPv4/IPv6 header;
- IP source/destination;
- TCP/UDP source/destination port;
- protocol;
- DSCP/ECN;
- MPLS label;
- VXLAN header;
- inner packet header。
11.2 Lookup
Lookup 决定 packet 如何转发。不同表项可能使用不同硬件结构。
| 表 | 作用 | 常见实现 |
|---|---|---|
| MAC Table | L2 转发 | Hash / CAM |
| VLAN Table | VLAN 成员关系和属性 | SRAM |
| LPM Table | IP 路由最长前缀匹配 | TCAM / Trie / Algorithmic |
| ACL Table | 访问控制、重定向、统计 | TCAM |
| Neighbor Table | 下一跳 MAC 信息 | SRAM / Hash |
| ECMP Table | 多路径选择 | SRAM + Hash |
11.3 ACL 和 QoS
ACL 和 QoS 通常位于 ingress pipeline 中,用于决定 packet 是否允许、是否重定向、进入哪个队列、使用什么优先级。
常见动作包括:
- permit/drop;
- redirect;
- mirror;
- remark DSCP/PCP;
- assign traffic class;
- assign color;
- policing;
- counting;
- timestamping。
12 Packet Buffer、Queue 与 Scheduler
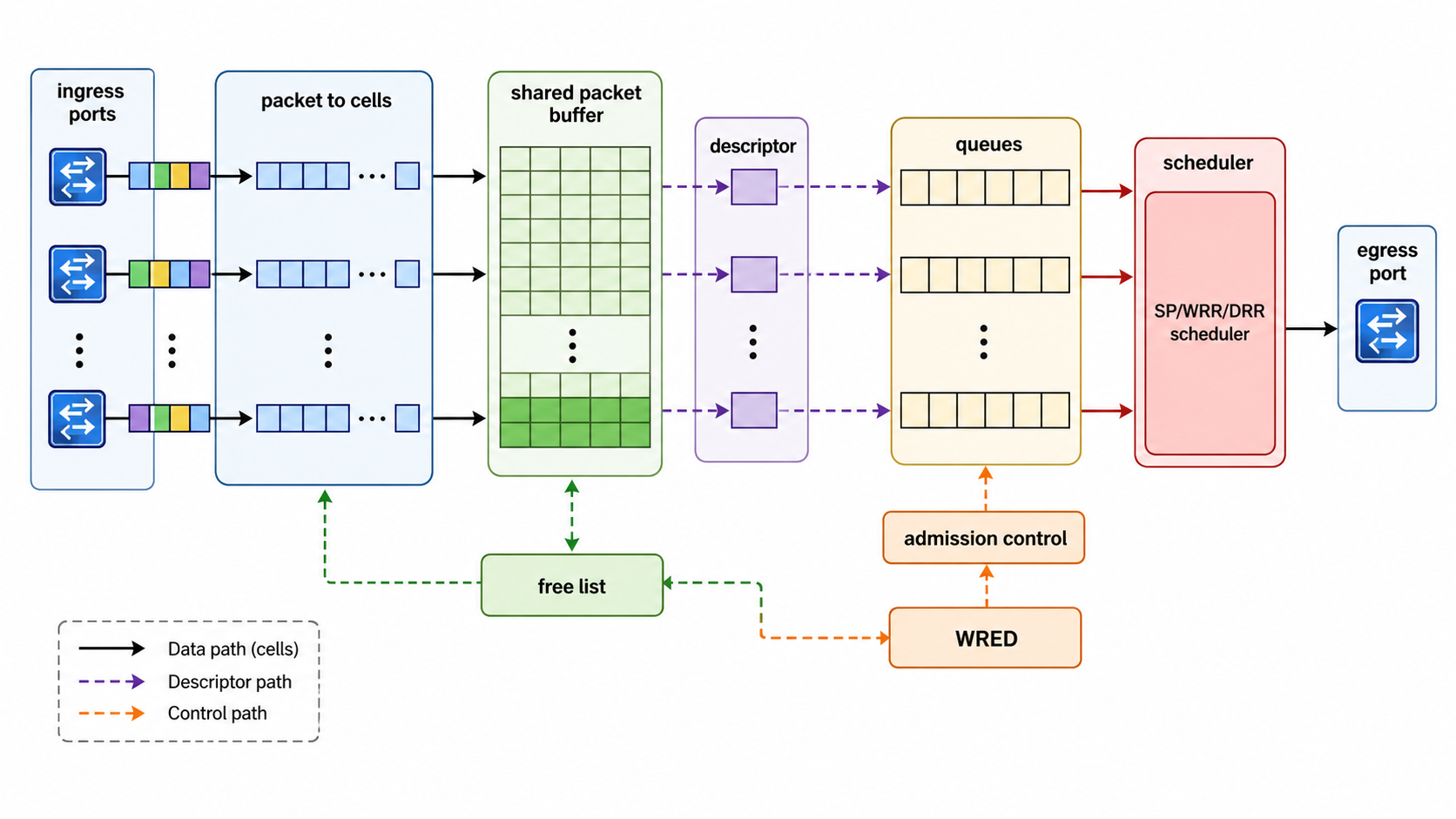
Switch ASIC 中最复杂的部分之一是 buffer 和调度。原因是以太网 packet 是突发的,多端口同时输入输出,出口可能发生拥塞。
12.1 Packet Buffer
Packet Buffer 可以采用不同架构:
| 架构 | 特点 |
|---|---|
| Input Buffer | 实现简单,但容易 HOL blocking |
| Output Buffer | 性能好,但对存储带宽要求极高 |
| Shared Buffer | 多端口共享,提高利用率 |
| VOQ | Virtual Output Queue,缓解队头阻塞 |
| Cell Buffer | 将变长 packet 切成固定大小 cell 管理 |
商用交换芯片通常会把 packet 切成 cell,并用 descriptor 记录 packet 的元信息。这样可以简化 buffer 分配和释放。
12.2 Descriptor
Descriptor 通常包含:
- packet length;
- ingress port;
- egress port bitmap;
- queue ID;
- traffic class;
- drop precedence;
- buffer address;
- timestamp;
- mirror flag;
- error flag。
12.3 Queue Manager
Queue Manager 负责把 packet descriptor 放入正确队列,并在 packet 发送完成后释放资源。
重点机制:
- enqueue;
- dequeue;
- free list;
- buffer allocation;
- threshold;
- admission control;
- tail drop;
- WRED;
- multicast replication;
- queue occupancy counter。
12.4 Scheduler
Scheduler 决定哪个 queue 可以发送下一个 packet。
常见调度算法:
| 算法 | 特点 |
|---|---|
| SP | Strict Priority,低延迟但可能饿死低优先级 |
| RR | Round Robin,简单公平 |
| WRR | Weighted Round Robin,支持带宽比例 |
| DRR | Deficit Round Robin,适合变长 packet |
| WFQ | Weighted Fair Queueing,更精细但复杂 |
| Hierarchical Scheduler | 多级调度,适合端口/业务/队列层级 |
13 流控与拥塞控制硬件
以太网芯片设计不仅要能转发 packet,还要在拥塞时决定如何暂停、丢弃、标记或调度流量。
13.1 802.3x Pause
Pause Frame 是链路级流控。接收端 buffer 接近满时,可以通知对端暂停发送。
硬件需要支持:
- Pause frame detect;
- Pause timer;
- MAC TX pause control;
- Pause frame generation;
- RX buffer watermark;
- 对统计计数器的更新。
缺点是 Pause 会暂停整个链路,可能导致 Head-of-Line Blocking。
13.2 PFC
PFC 是 Priority-based Flow Control,可以按优先级暂停特定 traffic class,常用于无损以太网。
硬件需要支持:
- 8 个 priority 的 pause timer;
- per-priority watermark;
- PFC frame parse;
- PFC frame generation;
- priority 到 queue 的映射;
- headroom buffer;
- deadlock detection。
13.3 ECN
ECN 是显式拥塞通知。与直接丢包不同,ECN 可以在拥塞时标记 packet,让端系统降低发送速率。
硬件需要支持:
- queue depth monitoring;
- ECN marking threshold;
- WRED/ECN profile;
- IP header ECN bit 修改;
- checksum update;
- congestion statistics。
13.4 RoCE 相关硬件考虑
在 AI 集群和 HPC 中,RoCE 对以太网芯片提出了更高要求:
- 低延迟;
- 低丢包;
- PFC;
- ECN;
- DCQCN;
- high priority queue;
- large shared buffer;
- precise congestion marking;
- telemetry。
14 Egress Pipeline 与 Packet 修改
Ingress pipeline 决定 packet 如何处理,Egress pipeline 则在 packet 发出前完成最终修改。
常见 egress 操作包括:
- VLAN tag add/remove/replace;
- source MAC rewrite;
- destination MAC rewrite;
- TTL decrement;
- IP checksum update;
- DSCP/PCP remark;
- mirror copy;
- timestamp insertion;
- FCS regenerate;
- padding;
- port shaping。
需要注意,任何修改 Ethernet frame body 的操作都会影响 FCS。因此 MAC TX 通常会重新计算 FCS,而不是沿用原来的 FCS。
14.1 Cut-through 与 Store-and-forward
| 模式 | 特点 |
|---|---|
| Store-and-forward | 收完整包并校验 FCS 后再转发,可靠但延迟较高 |
| Cut-through | 收到头部并完成查表后即可开始转发,延迟低但错误包可能被转发 |
| Fragment-free | 至少接收前 64 Bytes 后再转发,折中方案 |
高性能交换芯片常需要在低延迟和可靠性之间做取舍。
15 管理接口、寄存器与调试
以太网硬件模块不能只设计 datapath,还需要可配置、可观测、可调试。
15.1 MDIO
MDIO 是 MAC/控制器访问 PHY 寄存器的常见管理接口。
学习重点:
- Clause 22;
- Clause 45;
- PHY address;
- register address;
- read/write transaction;
- auto-negotiation status;
- link partner ability;
- speed/duplex status。
15.2 MAC/Switch 寄存器
常见寄存器包括:
- MAC enable;
- speed configuration;
- duplex mode;
- max frame length;
- pause enable;
- address filter;
- VLAN configuration;
- statistics counter;
- interrupt status;
- error status;
- loopback control。
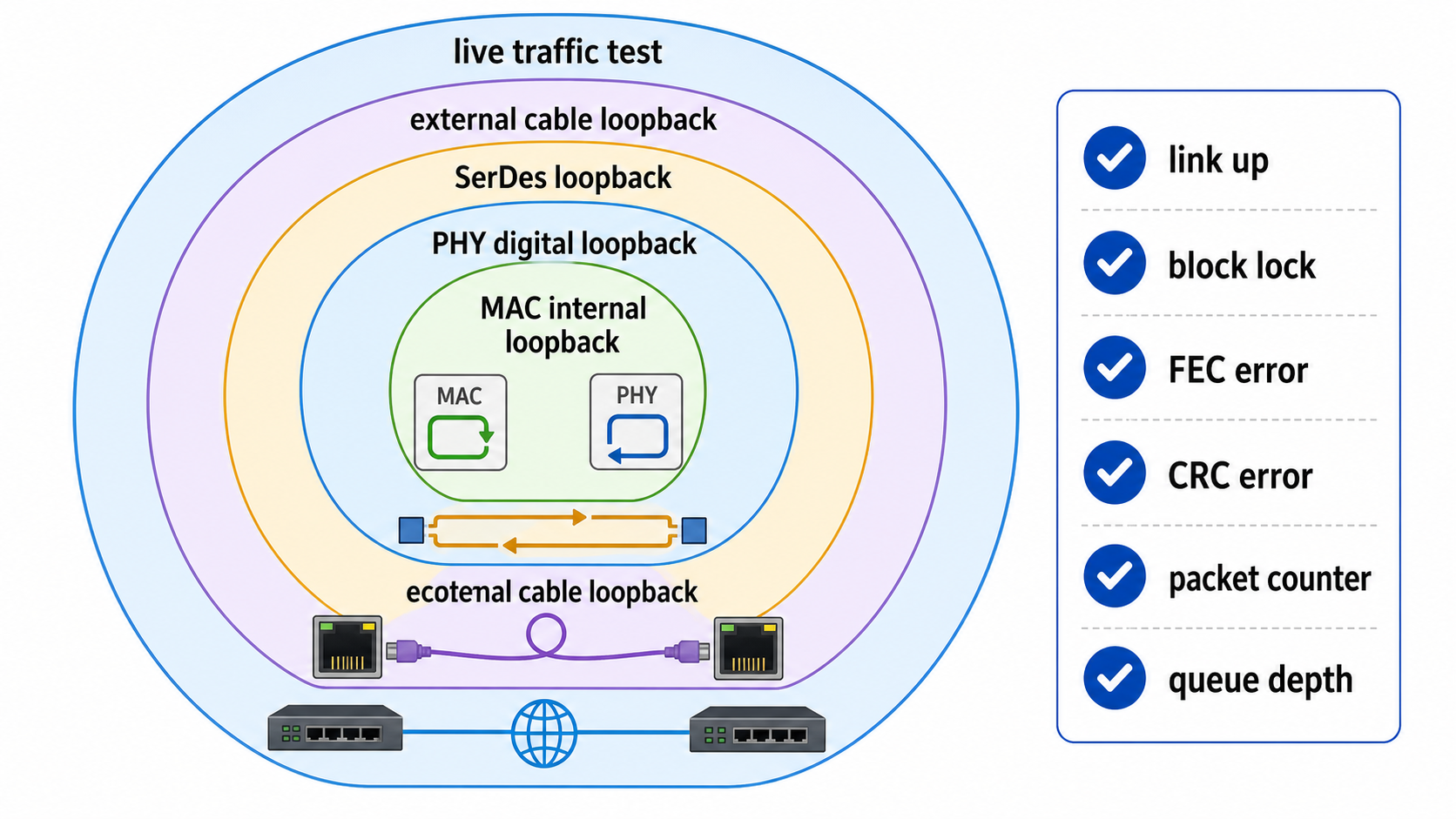
15.3 Loopback
硬件 bring-up 时,loopback 非常重要。
常见 loopback 层次:
| Loopback | 用途 |
|---|---|
| MAC internal loopback | 验证 MAC TX/RX |
| PHY digital loopback | 验证 MAC-PHY 接口 |
| SerDes near-end loopback | 验证 PCS/PMA 侧 |
| SerDes far-end loopback | 验证链路和对端 |
| External cable loopback | 验证完整物理链路 |
15.4 调试指标
常见调试观察项:
- link up/down;
- auto-negotiation complete;
- block lock;
- lane lock;
- FEC corrected count;
- FEC uncorrected count;
- CRC error;
- alignment error;
- RX/TX packet count;
- RX/TX byte count;
- buffer occupancy;
- queue depth;
- drop counter。
16 验证方法
以太网硬件验证需要同时覆盖协议正确性、数据完整性、异常场景、吞吐率和拥塞行为。
16.1 MAC 验证
MAC 验证用例包括:
- 最小帧;
- 最大标准帧;
- Jumbo frame;
- 带 VLAN tag 的帧;
- CRC 正确帧;
- CRC 错误帧;
- runt frame;
- jabber frame;
- pause frame;
- back-to-back frame;
- IFG shrink/extend;
- RX error injection;
- TX underrun。
16.2 Packet Stream 验证
重点验证:
- SOP/EOP;
- empty/keep;
- valid/ready backpressure;
- random packet length;
- random gap;
- packet drop;
- metadata 对齐;
- packet order;
- multi-clock FIFO;
- reset during packet。
16.3 Switch Pipeline 验证
重点验证:
- L2 lookup hit/miss;
- unknown unicast flooding;
- broadcast;
- multicast replication;
- VLAN filtering;
- ACL drop/redirect;
- QoS classification;
- queue mapping;
- buffer threshold;
- WRED drop;
- scheduler fairness;
- PFC pause/resume;
- ECN marking。
16.4 性能验证
性能指标包括:
- line rate;
- packet per second;
- minimum-size packet throughput;
- latency;
- jitter;
- head-of-line blocking;
- buffer utilization;
- scheduler fairness;
- burst absorption;
- congestion recovery。
17 推荐学习路线
如果只关注硬件/芯片方向,推荐按下面路线学习:
以太网帧格式
-> CRC32/FCS
-> MAC TX/RX
-> GMII/RGMII/SGMII/XGMII
-> PHY/PCS/PMA/SerDes
-> AXI-Stream/FIFO/CDC
-> Packet Parser
-> Switch ASIC Pipeline
-> Buffer/Queue/Scheduler
-> QoS/PFC/ECN
-> RoCE/Data Center Ethernet
17.1 第一阶段:MAC 基础
学习内容:
- Ethernet II frame;
- Preamble/SFD;
- IFG;
- Padding;
- FCS;
- MAC TX FSM;
- MAC RX FSM;
- CRC32。
目标:
能够自己设计一个简化 8-bit Ethernet MAC TX/RX,并用仿真验证收发流程。
17.2 第二阶段:接口和 PHY
学习内容:
- GMII;
- RGMII;
- SGMII;
- XGMII;
- PCS;
- 8B/10B;
- 64B/66B;
- auto-negotiation;
- MDIO。
目标:
能够解释 MAC 到 PHY 之间的数据如何传输,并能在 FPGA 上完成 RGMII 或 SGMII bring-up。
17.3 第三阶段:高速物理层
学习内容:
- SerDes;
- CDR;
- equalization;
- PAM4;
- FEC;
- lane alignment;
- gearbox;
- 25G/50G/100G lane。
目标:
能够理解高速以太网端口为什么需要 PCS/FEC/SerDes,以及多 lane 端口如何组合成 100G/400G。
17.4 第四阶段:Switch ASIC Pipeline
学习内容:
- parser;
- VLAN classification;
- L2 lookup;
- L3 lookup;
- ACL;
- QoS;
- metadata;
- egress modification。
目标:
能够画出一个简化交换芯片的 ingress/egress pipeline,并解释 packet 如何从入端口被转发到出端口。
17.5 第五阶段:Buffer、Queue 和 Scheduler
学习内容:
- packet buffer;
- cell buffer;
- descriptor;
- free list;
- queue manager;
- VOQ;
- SP/WRR/DRR;
- WRED;
- PFC;
- ECN。
目标:
能够理解交换芯片如何在拥塞场景下缓存、排队、丢包、暂停或标记流量。
17.6 第六阶段:数据中心以太网
学习内容:
- RoCE;
- PFC;
- ECN;
- DCQCN;
- telemetry;
- low-latency switching;
- 400G/800G Ethernet;
- AI cluster network。
目标:
能够理解高端数据中心交换芯片为什么需要大 buffer、低延迟、高速 SerDes、精细 QoS 和拥塞控制。
18 建议的练习项目
学习以太网硬件最好不要只看协议文档,建议配合 RTL 或 FPGA 项目逐步练习。
18.1 项目一:CRC32 模块
目标:
- 实现 8-bit Ethernet CRC32;
- 实现 64-bit parallel CRC32;
- 支持任意最后一拍 byte enable;
- 与 Python/Scapy/Wireshark 结果对比。
18.2 项目二:简化 MAC TX
目标:
- 输入 frame body;
- 自动插入 Preamble/SFD;
- 自动 padding;
- 自动追加 FCS;
- 控制 IFG;
- 仿真 back-to-back frame。
18.3 项目三:简化 MAC RX
目标:
- 检测 Preamble/SFD;
- 提取 frame;
- 校验 FCS;
- 识别 runt/jabber;
- 输出 packet stream;
- 统计错误计数。
18.4 项目四:ARP + ICMP Ping FPGA Demo
目标:
- FPGA 接 RGMII PHY;
- 实现 ARP responder;
- 实现 ICMP echo responder;
- PC 能 ping 通 FPGA;
- Wireshark 抓包验证。
18.5 项目五:简化二层交换机
目标:
- 两个或四个 MAC port;
- MAC learning;
- L2 forwarding;
- unknown unicast flooding;
- broadcast flooding;
- VLAN 简化支持;
- packet FIFO;
- round-robin egress arbitration。
18.6 项目六:简化 QoS Scheduler
目标:
- 多队列;
- strict priority;
- WRR;
- DRR;
- queue depth counter;
- drop threshold;
- 仿真不同流量模型下的调度效果。
19 总结
以太网硬件与芯片设计的学习重点,不是简单背诵 Ethernet frame 格式,而是理解一帧数据在硬件中的完整生命轨迹:
从 MAC RX 收到字节流
-> 校验 FCS
-> 形成内部 packet stream
-> 被 parser 提取字段
-> 被 lookup 决定转发路径
-> 被 buffer 暂存
-> 被 queue manager 管理
-> 被 scheduler 选中
-> 被 egress pipeline 修改
-> 被 MAC TX 重新发送
-> 经过 PCS/FEC/SerDes 回到物理链路
对于 RTL/ASIC 工程师,建议优先掌握以下模块:
- CRC32/FCS:理解数据完整性校验;
- Ethernet MAC TX/RX:理解帧收发的硬件实现;
- GMII/RGMII/SGMII/XGMII:理解 MAC 与 PHY/PCS 的接口;
- PCS/FEC/SerDes:理解高速以太网物理层;
- Packet Stream/FIFO/CDC:理解芯片内部 packet 数据通路;
- Parser/Lookup/ACL/QoS:理解交换芯片 pipeline;
- Buffer/Queue/Scheduler:理解高性能交换芯片的核心架构;
- PFC/ECN/RoCE:理解数据中心无损以太网和拥塞控制。
当能够从 RTL 角度讲清楚“一帧 Ethernet packet 如何进入芯片、被校验、被解析、被查表、被缓存、被调度并最终从另一个端口发出”时,以太网硬件与芯片设计的主线就已经建立起来了。
20 参考资料
-
IEEE 802.3 Ethernet Working Group
https://www.ieee802.org/3/ -
IEEE 802.1 Working Group
https://www.ieee802.org/1/ -
IEEE 802.1Q - Bridges and Bridged Networks
https://standards.ieee.org/standard/802_1Q-2022.html -
IEEE 802.1AX - Link Aggregation
https://standards.ieee.org/standard/802_1AX-2020.html -
IEEE 802.3x Flow Control
-
IEEE 802.1Qbb Priority-based Flow Control
-
IEEE 802.1Qaz Enhanced Transmission Selection
-
AMD/Xilinx Ethernet MAC IP Documentation
-
Intel FPGA Triple-Speed Ethernet IP Documentation
-
Intel Ethernet Controller Datasheets
-
Broadcom Ethernet Switch Architecture Public Materials
-
Wireshark User’s Guide
https://www.wireshark.org/docs/wsug_html_chunked/ -
The TCP/IP Guide - Ethernet
http://www.tcpipguide.com/free/t_Ethernet.htm
